 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUse of OWL and Semantic Web Technologies at Pinterest
Jul 03, 2019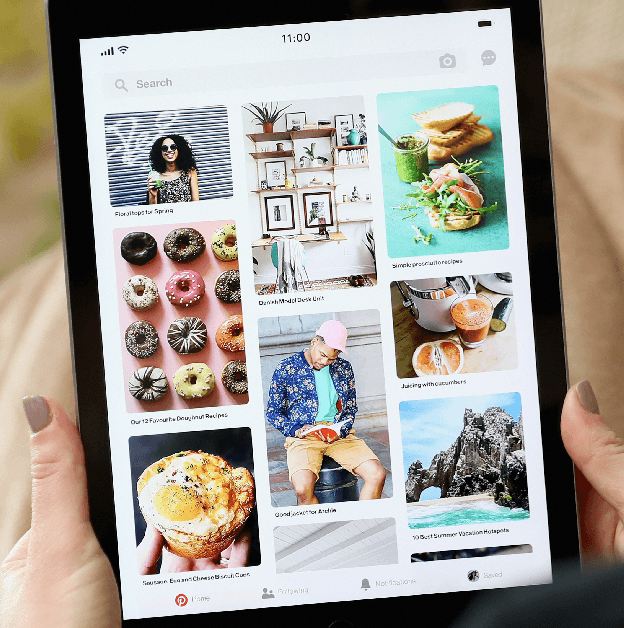
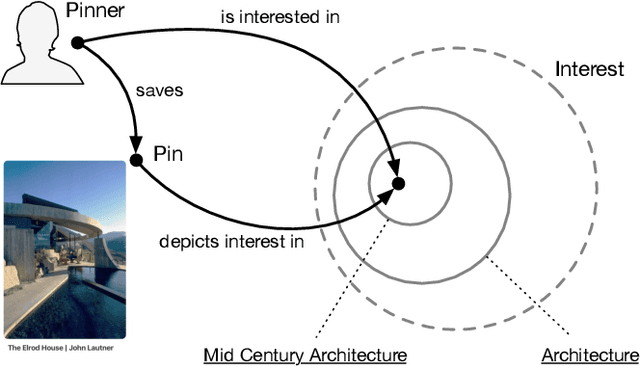
Pinterest is a popular Web application that has over 250 million active users. It is a visual discovery engine for finding ideas for recipes, fashion, weddings, home decoration, and much more. In the last year, the company adopted Semantic Web technologies to create a knowledge graph that aims to represent the vast amount of content and users on Pinterest, to help both content recommendation and ads targeting. In this paper, we present the engineering of an OWL ontology---the Pinterest Taxonomy---that forms the core of Pinterest's knowledge graph, the Pinterest Taste Graph. We describe modeling choices and enhancements to WebProt\'eg\'e that we used for the creation of the ontology. In two months, eight Pinterest engineers, without prior experience of OWL and WebProt\'eg\'e, revamped an existing taxonomy of noisy terms into an OWL ontology. We share our experience and present the key aspects of our work that we believe will be useful for others working in this area.
Aligning Biomedical Metadata with Ontologies Using Clustering and Embeddings
Mar 19, 2019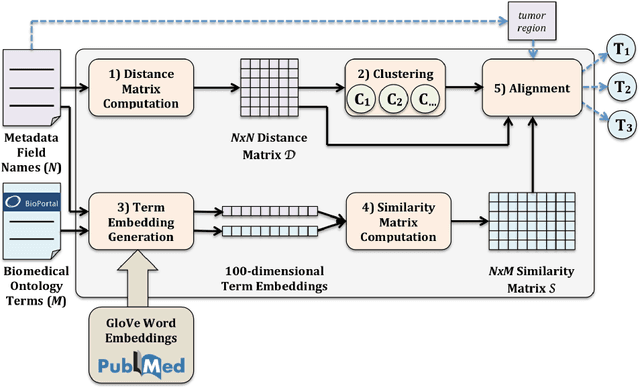
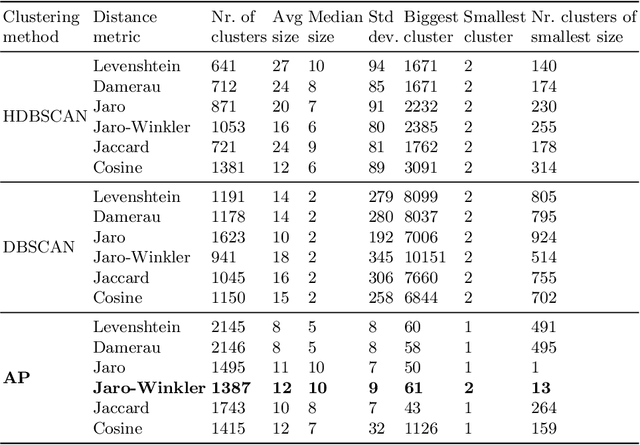
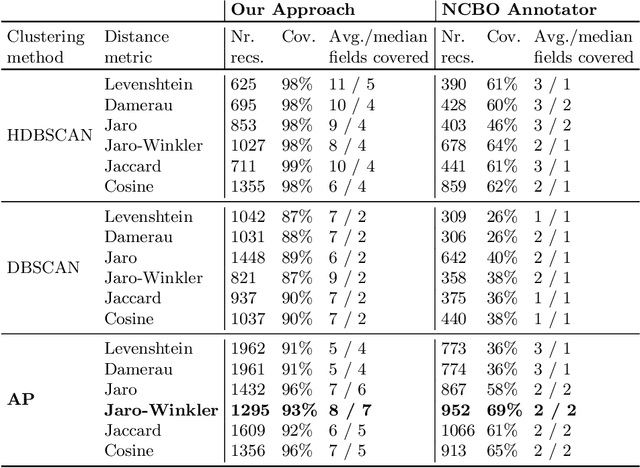
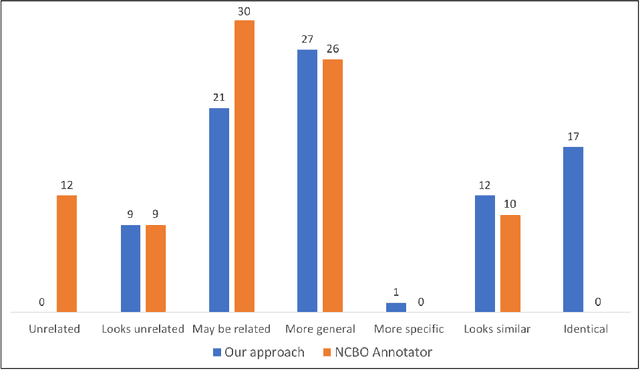
The metadata about scientific experiments published in online repositories have been shown to suffer from a high degree of representational heterogeneity---there are often many ways to represent the same type of information, such as a geographical location via its latitude and longitude. To harness the potential that metadata have for discovering scientific data, it is crucial that they be represented in a uniform way that can be queried effectively. One step toward uniformly-represented metadata is to normalize the multiple, distinct field names used in metadata (e.g., lat lon, lat and long) to describe the same type of value. To that end, we present a new method based on clustering and embeddings (i.e., vector representations of words) to align metadata field names with ontology terms. We apply our method to biomedical metadata by generating embeddings for terms in biomedical ontologies from the BioPortal repository. We carried out a comparative study between our method and the NCBO Annotator, which revealed that our method yields more and substantially better alignments between metadata and ontology terms.
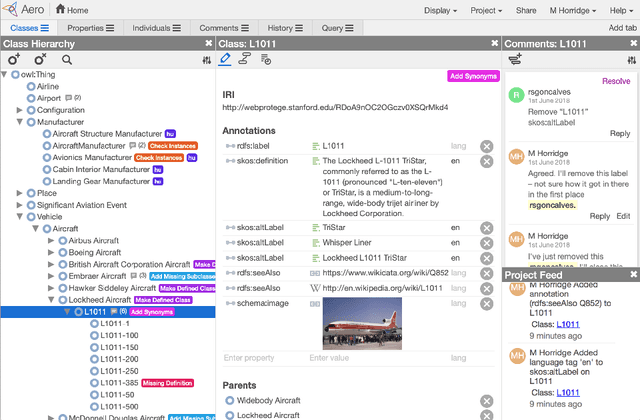
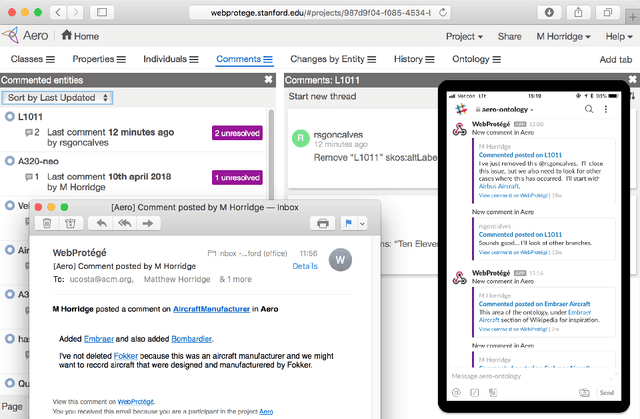
WebProtégé: A Cloud-Based Ontology Editor
Mar 06, 2019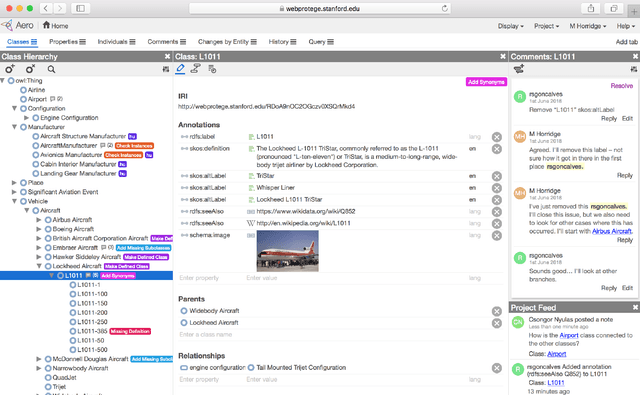
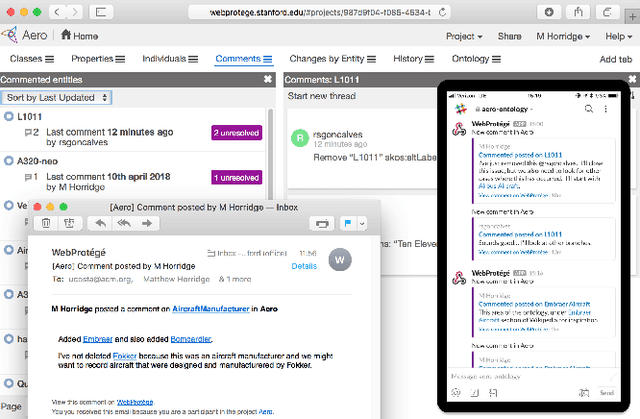
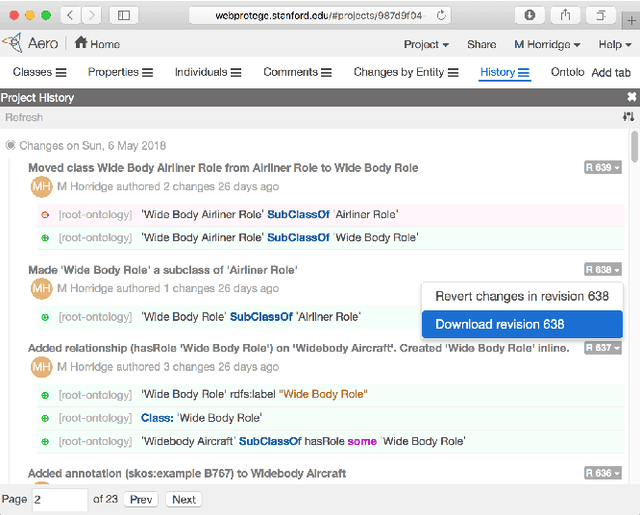
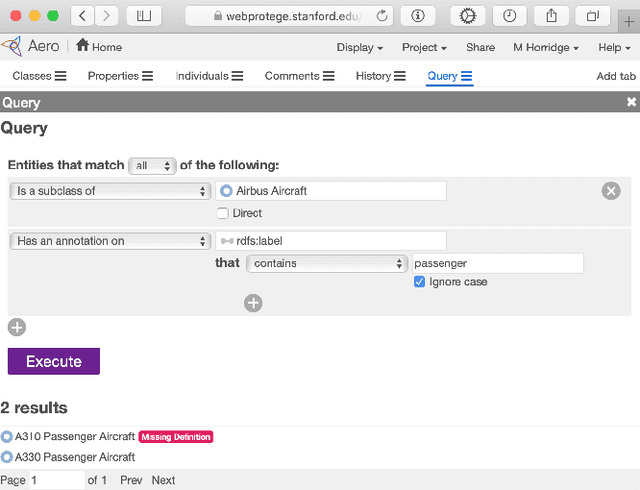
We present WebProt\'eg\'e, a tool to develop ontologies represented in the Web Ontology Language (OWL). WebProt\'eg\'e is a cloud-based application that allows users to collaboratively edit OWL ontologies, and it is available for use at https://webprotege.stanford.edu. WebProt\'ege\'e currently hosts more than 68,000 OWL ontology projects and has over 50,000 user accounts. In this paper, we detail the main new features of the latest version of WebProt\'eg\'e.
The Variable Quality of Metadata About Biological Samples Used in Biomedical Experiments
Aug 17, 2018
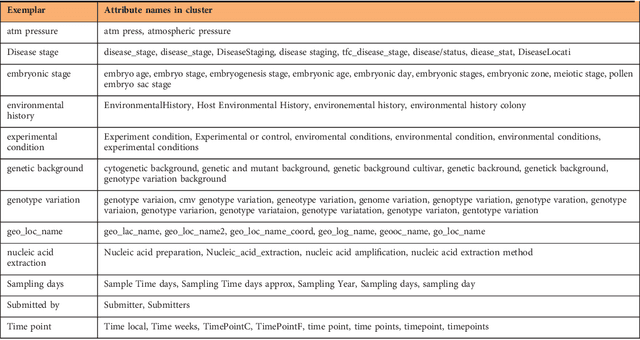
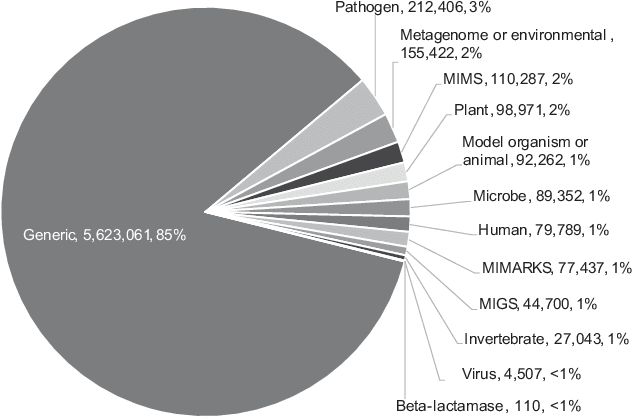
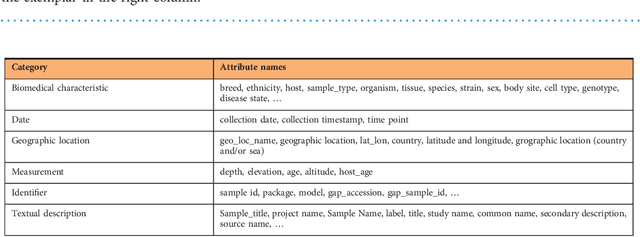
We present an analytical study of the quality of metadata about samples used in biomedical experiments. The metadata under analysis are stored in two well- known databases: BioSample---a repository managed by the National Center for Biotechnology Information (NCBI), and BioSamples---a repository managed by the European Bioinformatics Institute (EBI). We tested whether 11.4M sample metadata records in the two repositories are populated with values that fulfill the stated requirements for such values. Our study revealed multiple anomalies in the metadata. Most metadata field names and their values are not standardized or controlled. Even simple binary or numeric fields are often populated with inadequate values of different data types. By clustering metadata field names, we discovered there are often many distinct ways to represent the same aspect of a sample. Overall, the metadata we analyzed reveal that there is a lack of principled mechanisms to enforce and validate metadata requirements. The significant aberrancies that we found in the metadata are likely to impede search and secondary use of the associated datasets.