 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Variable Quality of Metadata About Biological Samples Used in Biomedical Experiments
Paper and Code

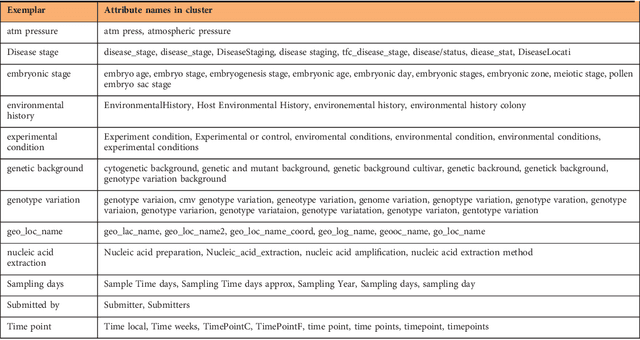
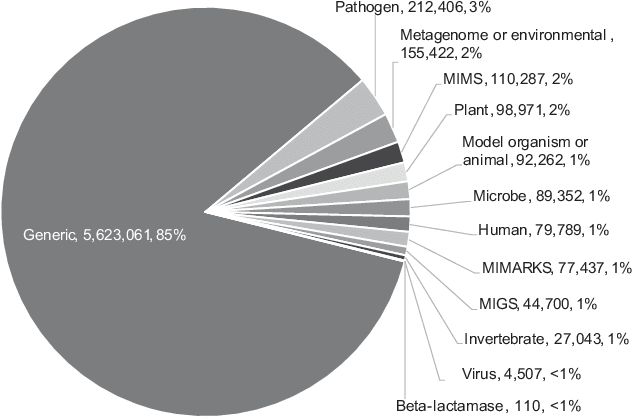
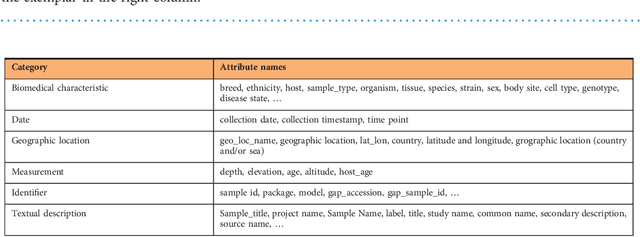
We present an analytical study of the quality of metadata about samples used in biomedical experiments. The metadata under analysis are stored in two well- known databases: BioSample---a repository managed by the National Center for Biotechnology Information (NCBI), and BioSamples---a repository managed by the European Bioinformatics Institute (EBI). We tested whether 11.4M sample metadata records in the two repositories are populated with values that fulfill the stated requirements for such values. Our study revealed multiple anomalies in the metadata. Most metadata field names and their values are not standardized or controlled. Even simple binary or numeric fields are often populated with inadequate values of different data types. By clustering metadata field names, we discovered there are often many distinct ways to represent the same aspect of a sample. Overall, the metadata we analyzed reveal that there is a lack of principled mechanisms to enforce and validate metadata requirements. The significant aberrancies that we found in the metadata are likely to impede search and secondary use of the associated datasets.