 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Metadata More FAIR Using Large Language Models
Paper and Code
Jul 24, 2023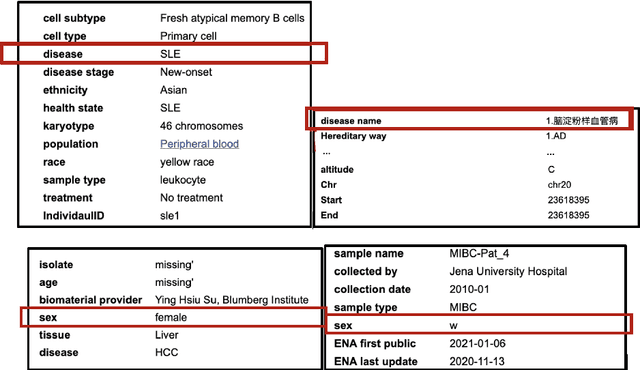

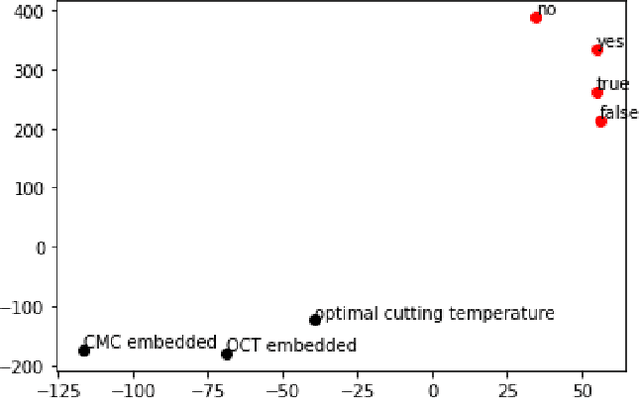

With the global increase in experimental data artifacts, harnessing them in a unified fashion leads to a major stumbling block - bad metadata. To bridge this gap, this work presents a Natural Language Processing (NLP) informed application, called FAIRMetaText, that compares metadata. Specifically, FAIRMetaText analyzes the natural language descriptions of metadata and provides a mathematical similarity measure between two terms. This measure can then be utilized for analyzing varied metadata, by suggesting terms for compliance or grouping similar terms for identification of replaceable terms. The efficacy of the algorithm is presented qualitatively and quantitatively on publicly available research artifacts and demonstrates large gains across metadata related tasks through an in-depth study of a wide variety of Large Language Models (LLMs). This software can drastically reduce the human effort in sifting through various natural language metadata while employing several experimental datasets on the same topic.