 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUse of a Structured Knowledge Base Enhances Metadata Curation by Large Language Models
Apr 08, 2024

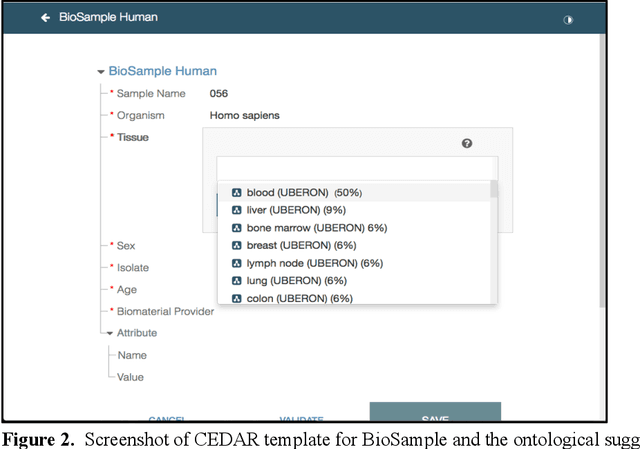

Metadata play a crucial role in ensuring the findability, accessibility, interoperability, and reusability of datasets. This paper investigates the potential of large language models (LLMs), specifically GPT-4, to improve adherence to metadata standards. We conducted experiments on 200 random data records describing human samples relating to lung cancer from the NCBI BioSample repository, evaluating GPT-4's ability to suggest edits for adherence to metadata standards. We computed the adherence accuracy of field name-field value pairs through a peer review process, and we observed a marginal average improvement in adherence to the standard data dictionary from 79% to 80% (p<0.01). We then prompted GPT-4 with domain information in the form of the textual descriptions of CEDAR templates and recorded a significant improvement to 97% from 79% (p<0.01). These results indicate that, while LLMs may not be able to correct legacy metadata to ensure satisfactory adherence to standards when unaided, they do show promise for use in automated metadata curation when integrated with a structured knowledge base.