 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNote2Chat: Improving LLMs for Multi-Turn Clinical History Taking Using Medical Notes
Jan 29, 2026Effective clinical history taking is a foundational yet underexplored component of clinical reasoning. While large language models (LLMs) have shown promise on static benchmarks, they often fall short in dynamic, multi-turn diagnostic settings that require iterative questioning and hypothesis refinement. To address this gap, we propose \method{}, a note-driven framework that trains LLMs to conduct structured history taking and diagnosis by learning from widely available medical notes. Instead of relying on scarce and sensitive dialogue data, we convert real-world medical notes into high-quality doctor-patient dialogues using a decision tree-guided generation and refinement pipeline. We then propose a three-stage fine-tuning strategy combining supervised learning, simulated data augmentation, and preference learning. Furthermore, we propose a novel single-turn reasoning paradigm that reframes history taking as a sequence of single-turn reasoning problems. This design enhances interpretability and enables local supervision, dynamic adaptation, and greater sample efficiency. Experimental results show that our method substantially improves clinical reasoning, achieving gains of +16.9 F1 and +21.0 Top-1 diagnostic accuracy over GPT-4o. Our code and dataset can be found at https://github.com/zhentingsheng/Note2Chat.
Toward Global Large Language Models in Medicine
Jan 05, 2026Despite continuous advances in medical technology, the global distribution of health care resources remains uneven. The development of large language models (LLMs) has transformed the landscape of medicine and holds promise for improving health care quality and expanding access to medical information globally. However, existing LLMs are primarily trained on high-resource languages, limiting their applicability in global medical scenarios. To address this gap, we constructed GlobMed, a large multilingual medical dataset, containing over 500,000 entries spanning 12 languages, including four low-resource languages. Building on this, we established GlobMed-Bench, which systematically assesses 56 state-of-the-art proprietary and open-weight LLMs across multiple multilingual medical tasks, revealing significant performance disparities across languages, particularly for low-resource languages. Additionally, we introduced GlobMed-LLMs, a suite of multilingual medical LLMs trained on GlobMed, with parameters ranging from 1.7B to 8B. GlobMed-LLMs achieved an average performance improvement of over 40% relative to baseline models, with a more than threefold increase in performance on low-resource languages. Together, these resources provide an important foundation for advancing the equitable development and application of LLMs globally, enabling broader language communities to benefit from technological advances.
Fine-grained wound tissue analysis using deep neural network
Feb 28, 2018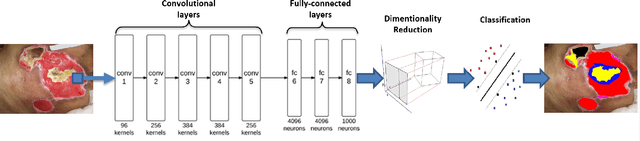
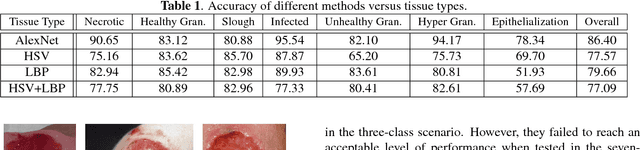

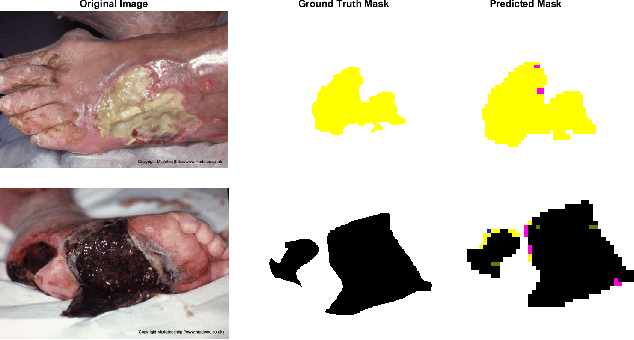
Tissue assessment for chronic wounds is the basis of wound grading and selection of treatment approaches. While several image processing approaches have been proposed for automatic wound tissue analysis, there has been a shortcoming in these approaches for clinical practices. In particular, seemingly, all previous approaches have assumed only 3 tissue types in the chronic wounds, while these wounds commonly exhibit 7 distinct tissue types that presence of each one changes the treatment procedure. In this paper, for the first time, we investigate the classification of 7 wound issue types. We work with wound professionals to build a new database of 7 types of wound tissue. We propose to use pre-trained deep neural networks for feature extraction and classification at the patch-level. We perform experiments to demonstrate that our approach outperforms other state-of-the-art. We will make our database publicly available to facilitate research in wound assessment.