 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRigorous dynamical mean field theory for stochastic gradient descent methods
Oct 12, 2022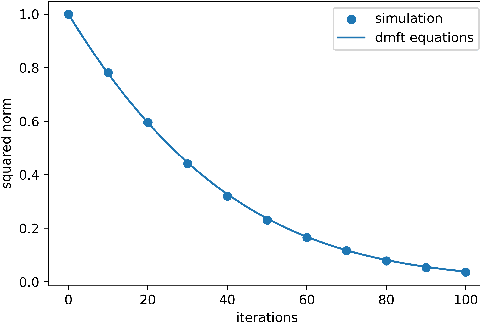

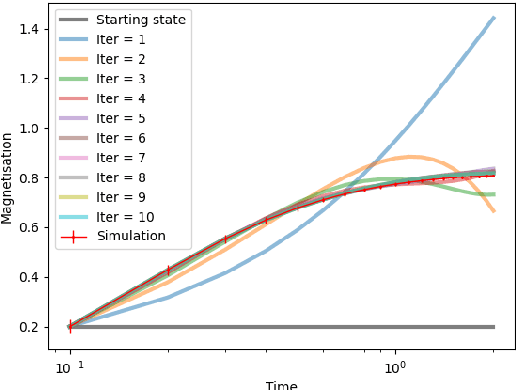
We prove closed-form equations for the exact high-dimensional asymptotics of a family of first order gradient-based methods, learning an estimator (e.g. M-estimator, shallow neural network, ...) from observations on Gaussian data with empirical risk minimization. This includes widely used algorithms such as stochastic gradient descent (SGD) or Nesterov acceleration. The obtained equations match those resulting from the discretization of dynamical mean-field theory (DMFT) equations from statistical physics when applied to gradient flow. Our proof method allows us to give an explicit description of how memory kernels build up in the effective dynamics, and to include non-separable update functions, allowing datasets with non-identity covariance matrices. Finally, we provide numerical implementations of the equations for SGD with generic extensive batch-size and with constant learning rates.
Thresholds of descending algorithms in inference problems
Jan 04, 2020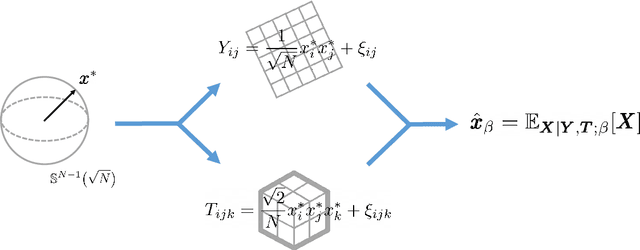

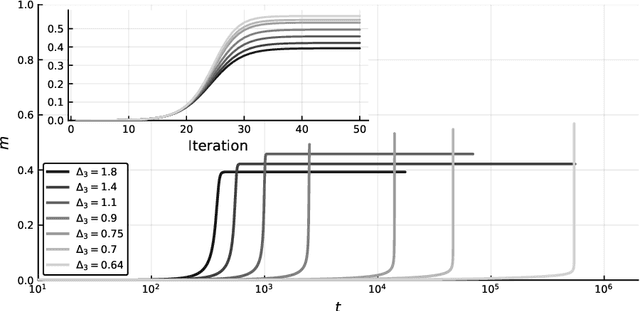
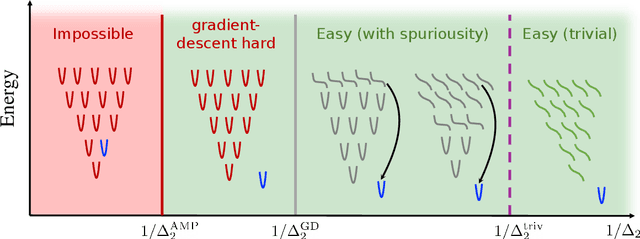
We review recent works on analyzing the dynamics of gradient-based algorithms in a prototypical statistical inference problem. Using methods and insights from the physics of glassy systems, these works showed how to understand quantitatively and qualitatively the performance of gradient-based algorithms. Here we review the key results and their interpretation in non-technical terms accessible to a wide audience of physicists in the context of related works.
Mutual information for symmetric rank-one matrix estimation: A proof of the replica formula
Jun 13, 2016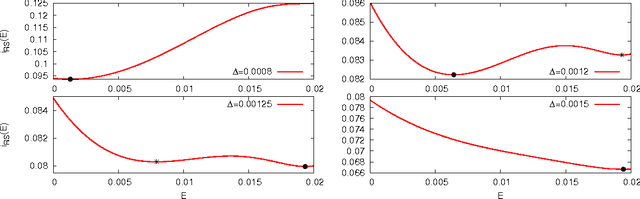
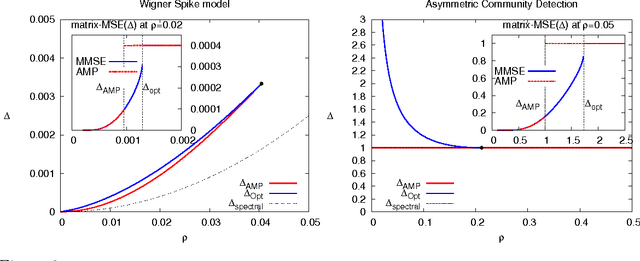
Factorizing low-rank matrices has many applications in machine learning and statistics. For probabilistic models in the Bayes optimal setting, a general expression for the mutual information has been proposed using heuristic statistical physics computations, and proven in few specific cases. Here, we show how to rigorously prove the conjectured formula for the symmetric rank-one case. This allows to express the minimal mean-square-error and to characterize the detectability phase transitions in a large set of estimation problems ranging from community detection to sparse PCA. We also show that for a large set of parameters, an iterative algorithm called approximate message-passing is Bayes optimal. There exists, however, a gap between what currently known polynomial algorithms can do and what is expected information theoretically. Additionally, the proof technique has an interest of its own and exploits three essential ingredients: the interpolation method introduced in statistical physics by Guerra, the analysis of the approximate message-passing algorithm and the theory of spatial coupling and threshold saturation in coding. Our approach is generic and applicable to other open problems in statistical estimation where heuristic statistical physics predictions are available.
Phase Transitions in Sparse PCA
Mar 01, 2015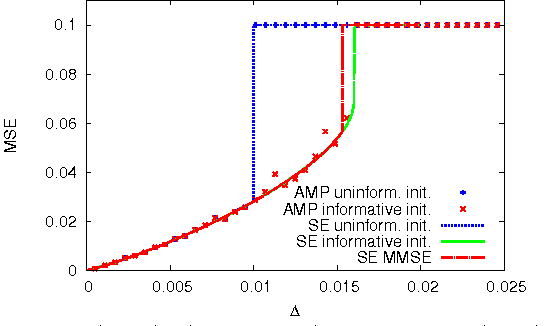
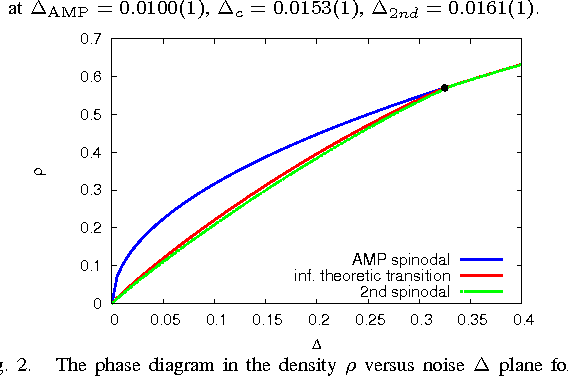
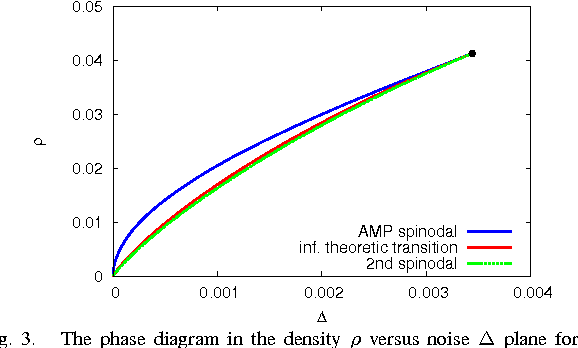
We study optimal estimation for sparse principal component analysis when the number of non-zero elements is small but on the same order as the dimension of the data. We employ approximate message passing (AMP) algorithm and its state evolution to analyze what is the information theoretically minimal mean-squared error and the one achieved by AMP in the limit of large sizes. For a special case of rank one and large enough density of non-zeros Deshpande and Montanari [1] proved that AMP is asymptotically optimal. We show that both for low density and for large rank the problem undergoes a series of phase transitions suggesting existence of a region of parameters where estimation is information theoretically possible, but AMP (and presumably every other polynomial algorithm) fails. The analysis of the large rank limit is particularly instructive.
* 6 pages, 3 figures
Model Selection for Degree-corrected Block Models
May 30, 2013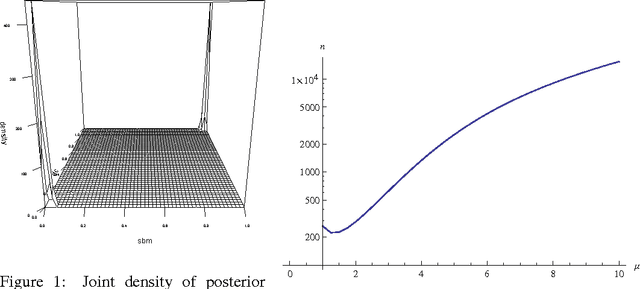
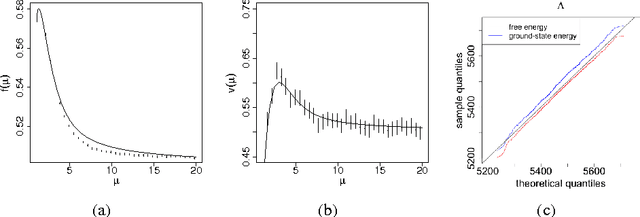
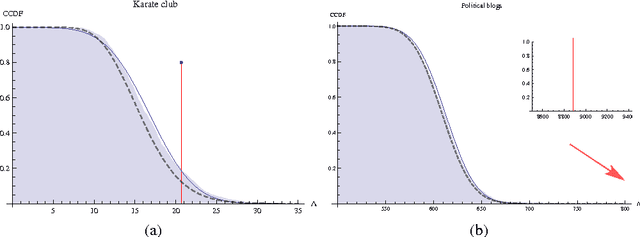
The proliferation of models for networks raises challenging problems of model selection: the data are sparse and globally dependent, and models are typically high-dimensional and have large numbers of latent variables. Together, these issues mean that the usual model-selection criteria do not work properly for networks. We illustrate these challenges, and show one way to resolve them, by considering the key network-analysis problem of dividing a graph into communities or blocks of nodes with homogeneous patterns of links to the rest of the network. The standard tool for doing this is the stochastic block model, under which the probability of a link between two nodes is a function solely of the blocks to which they belong. This imposes a homogeneous degree distribution within each block; this can be unrealistic, so degree-corrected block models add a parameter for each node, modulating its over-all degree. The choice between ordinary and degree-corrected block models matters because they make very different inferences about communities. We present the first principled and tractable approach to model selection between standard and degree-corrected block models, based on new large-graph asymptotics for the distribution of log-likelihood ratios under the stochastic block model, finding substantial departures from classical results for sparse graphs. We also develop linear-time approximations for log-likelihoods under both the stochastic block model and the degree-corrected model, using belief propagation. Applications to simulated and real networks show excellent agreement with our approximations. Our results thus both solve the practical problem of deciding on degree correction, and point to a general approach to model selection in network analysis.