 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurgical Phase and Instrument Recognition: How to identify appropriate Dataset Splits
Jun 29, 2023Purpose: The development of machine learning models for surgical workflow and instrument recognition from temporal data represents a challenging task due to the complex nature of surgical workflows. In particular, the imbalanced distribution of data is one of the major challenges in the domain of surgical workflow recognition. In order to obtain meaningful results, careful partitioning of data into training, validation, and test sets, as well as the selection of suitable evaluation metrics are crucial. Methods: In this work, we present an openly available web-based application that enables interactive exploration of dataset partitions. The proposed visual framework facilitates the assessment of dataset splits for surgical workflow recognition, especially with regard to identifying sub-optimal dataset splits. Currently, it supports visualization of surgical phase and instrument annotations. Results: In order to validate the dedicated interactive visualizations, we use a dataset split of the Cholec80 dataset. This dataset split was specifically selected to reflect a case of strong data imbalance. Using our software, we were able to identify phases, phase transitions, and combinations of surgical instruments that were not represented in one of the sets. Conclusion: In order to obtain meaningful results in highly unbalanced class distributions, special care should be taken with respect to the selection of an appropriate split. Interactive data visualization represents a promising approach for the assessment of machine learning datasets. The source code is available at https://github.com/Cardio-AI/endovis-ml
mvHOTA: A multi-view higher order tracking accuracy metric to measure spatial and temporal associations in multi-point detection
Jun 19, 2022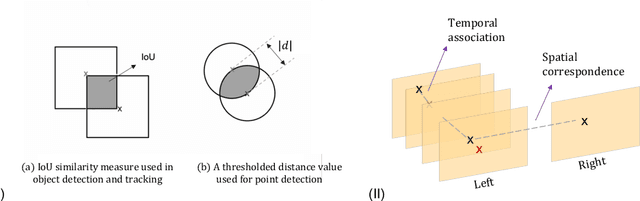
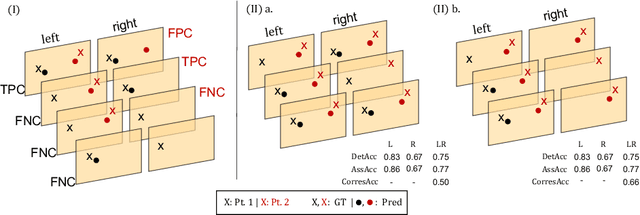
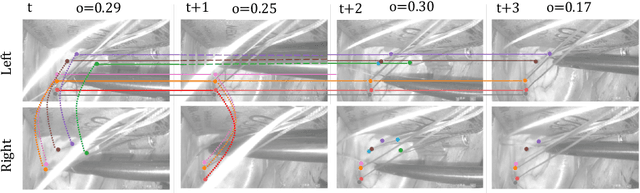
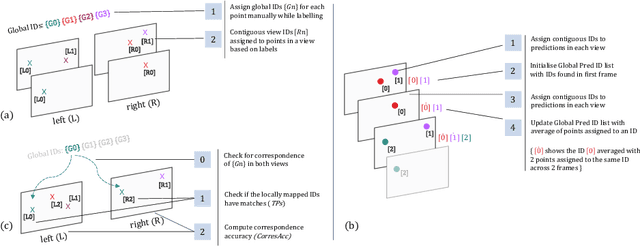
Multi-object tracking (MOT) is a challenging task that involves detecting objects in the scene and tracking them across a sequence of frames. Evaluating this task is difficult due to temporal occlusions, and varying trajectories across a sequence of images. The main evaluation metric to benchmark MOT methods on datasets such as KITTI has recently become the higher order tracking accuracy (HOTA) metric, which is capable of providing a better description of the performance over metrics such as MOTA, DetA, and IDF1. Point detection and tracking is a closely related task, which could be regarded as a special case of object detection. However, there are differences in evaluating the detection task itself (point distances vs. bounding box overlap). When including the temporal dimension and multi-view scenarios, the evaluation task becomes even more complex. In this work, we propose a multi-view higher order tracking metric (mvHOTA) to determine the accuracy of multi-point (multi-instance and multi-class) detection, while taking into account temporal and spatial associations. mvHOTA can be interpreted as the geometric mean of the detection, association, and correspondence accuracies, thereby providing equal weighting to each of the factors. We demonstrate a use-case through a publicly available endoscopic point detection dataset from a previously organised medical challenge. Furthermore, we compare with other adjusted MOT metrics for this use-case, discuss the properties of mvHOTA, and show how the proposed correspondence accuracy and the Occlusion index facilitate analysis of methods with respect to handling of occlusions. The code will be made publicly available.
Comparison of Evaluation Metrics for Landmark Detection in CMR Images
Jan 28, 2022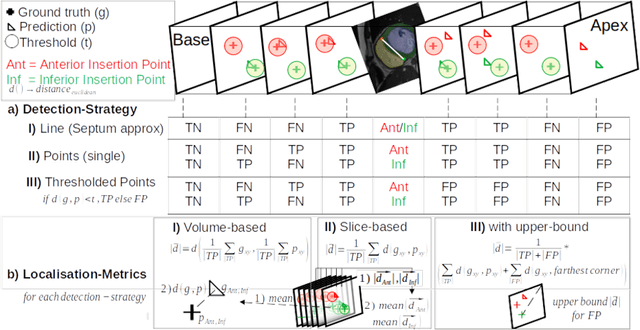

Cardiac Magnetic Resonance (CMR) images are widely used for cardiac diagnosis and ventricular assessment. Extracting specific landmarks like the right ventricular insertion points is of importance for spatial alignment and 3D modeling. The automatic detection of such landmarks has been tackled by multiple groups using Deep Learning, but relatively little attention has been paid to the failure cases of evaluation metrics in this field. In this work, we extended the public ACDC dataset with additional labels of the right ventricular insertion points and compare different variants of a heatmap-based landmark detection pipeline. In this comparison, we demonstrate very likely pitfalls of apparently simple detection and localisation metrics which highlights the importance of a clear detection strategy and the definition of an upper limit for localisation-based metrics. Our preliminary results indicate that a combination of different metrics is necessary, as they yield different winners for method comparison. Additionally, they highlight the need of a comprehensive metric description and evaluation standardisation, especially for the error cases where no metrics could be computed or where no lower/upper boundary of a metric exists. Code and labels: https://github.com/Cardio-AI/rvip_landmark_detection
Comparison of Depth Estimation Setups from Stereo Endoscopy and Optical Tracking for Point Measurements
Jan 26, 2022


To support minimally-invasive intraoperative mitral valve repair, quantitative measurements from the valve can be obtained using an infra-red tracked stylus. It is desirable to view such manually measured points together with the endoscopic image for further assistance. Therefore, hand-eye calibration is required that links both coordinate systems and is a prerequisite to project the points onto the image plane. A complementary approach to this is to use a vision-based endoscopic stereo-setup to detect and triangulate points of interest, to obtain the 3D coordinates. In this paper, we aim to compare both approaches on a rigid phantom and two patient-individual silicone replica which resemble the intraoperative scenario. The preliminary results indicate that 3D landmark estimation, either labeled manually or through partly automated detection with a deep learning approach, provides more accurate triangulated depth measurements when performed with a tailored image-based method than with stylus measurements.
Point detection through multi-instance deep heatmap regression for sutures in endoscopy
Nov 16, 2021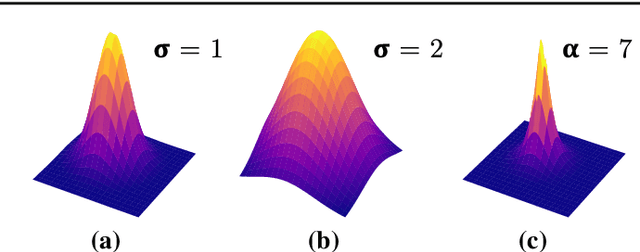
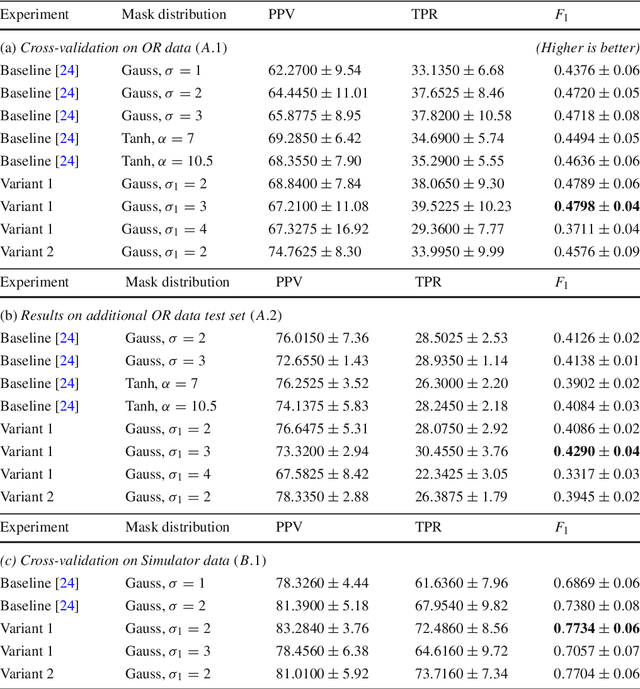
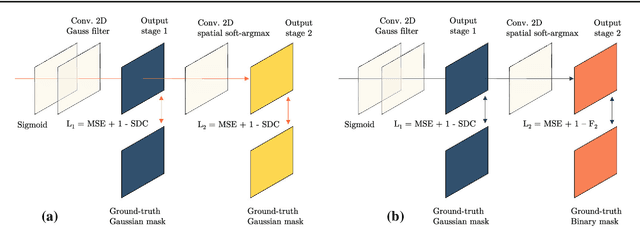
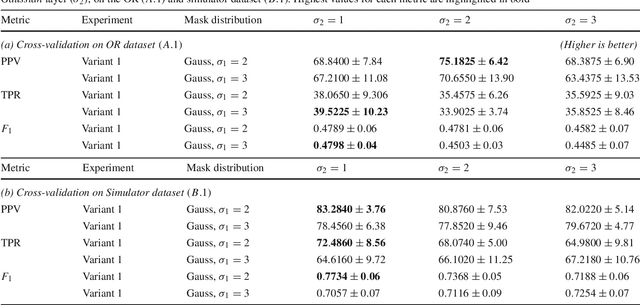
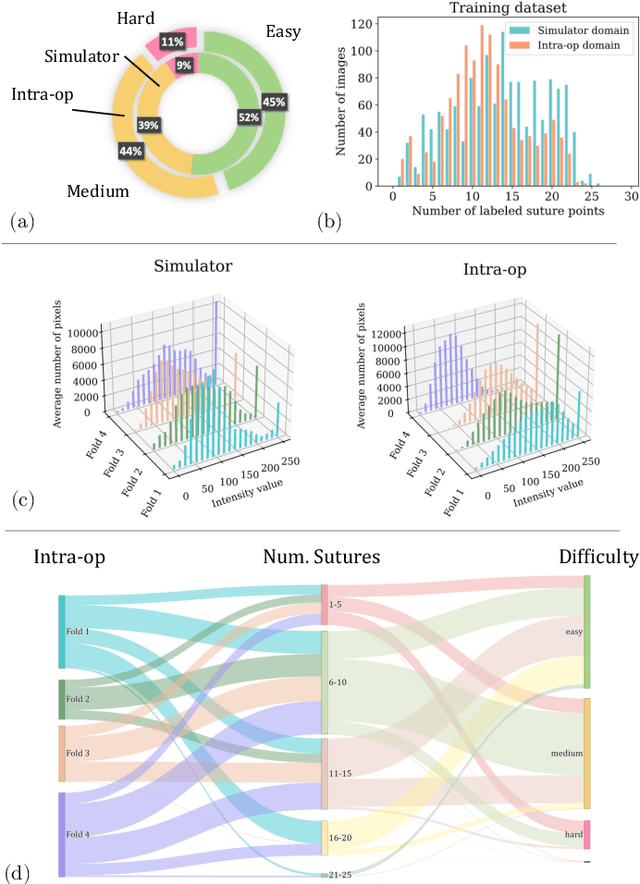
Purpose: Mitral valve repair is a complex minimally invasive surgery of the heart valve. In this context, suture detection from endoscopic images is a highly relevant task that provides quantitative information to analyse suturing patterns, assess prosthetic configurations and produce augmented reality visualisations. Facial or anatomical landmark detection tasks typically contain a fixed number of landmarks, and use regression or fixed heatmap-based approaches to localize the landmarks. However in endoscopy, there are a varying number of sutures in every image, and the sutures may occur at any location in the annulus, as they are not semantically unique. Method: In this work, we formulate the suture detection task as a multi-instance deep heatmap regression problem, to identify entry and exit points of sutures. We extend our previous work, and introduce the novel use of a 2D Gaussian layer followed by a differentiable 2D spatial Soft-Argmax layer to function as a local non-maximum suppression. Results: We present extensive experiments with multiple heatmap distribution functions and two variants of the proposed model. In the intra-operative domain, Variant 1 showed a mean F1 of +0.0422 over the baseline. Similarly, in the simulator domain, Variant 1 showed a mean F1 of +0.0865 over the baseline. Conclusion: The proposed model shows an improvement over the baseline in the intra-operative and the simulator domains. The data is made publicly available within the scope of the MICCAI AdaptOR2021 Challenge https://adaptor2021.github.io/, and the code at https://github.com/Cardio-AI/suture-detection-pytorch/. DOI:10.1007/s11548-021-02523-w. The link to the open access article can be found here: https://link.springer.com/article/10.1007%2Fs11548-021-02523-w
* Accepted to International Journal of Computer Assisted Radiology and Surgery, 15 pages, 5 figures
Mutually improved endoscopic image synthesis and landmark detection in unpaired image-to-image translation
Jul 14, 2021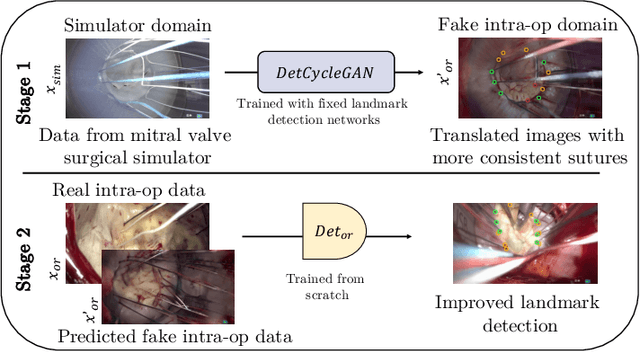
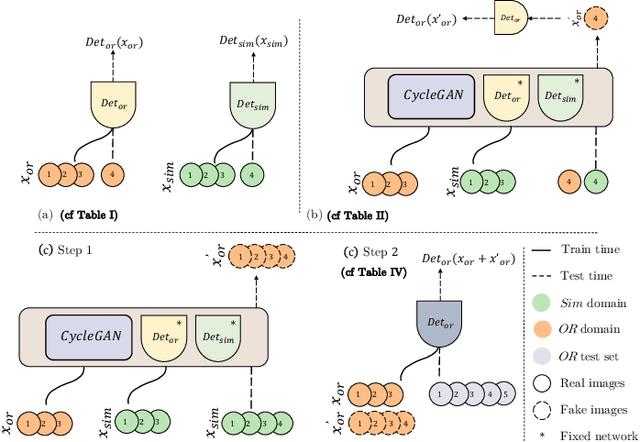
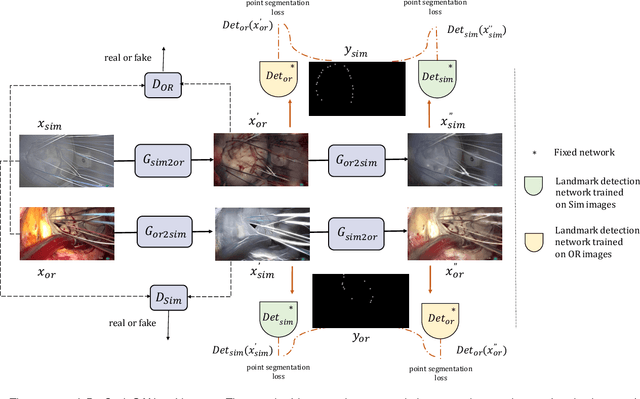
The CycleGAN framework allows for unsupervised image-to-image translation of unpaired data. In a scenario of surgical training on a physical surgical simulator, this method can be used to transform endoscopic images of phantoms into images which more closely resemble the intra-operative appearance of the same surgical target structure. This can be viewed as a novel augmented reality approach, which we coined Hyperrealism in previous work. In this use case, it is of paramount importance to display objects like needles, sutures or instruments consistent in both domains while altering the style to a more tissue-like appearance. Segmentation of these objects would allow for a direct transfer, however, contouring of these, partly tiny and thin foreground objects is cumbersome and perhaps inaccurate. Instead, we propose to use landmark detection on the points when sutures pass into the tissue. This objective is directly incorporated into a CycleGAN framework by treating the performance of pre-trained detector models as an additional optimization goal. We show that a task defined on these sparse landmark labels improves consistency of synthesis by the generator network in both domains. Comparing a baseline CycleGAN architecture to our proposed extension (DetCycleGAN), mean precision (PPV) improved by +61.32, mean sensitivity (TPR) by +37.91, and mean F1 score by +0.4743. Furthermore, it could be shown that by dataset fusion, generated intra-operative images can be leveraged as additional training data for the detection network itself. The data is released within the scope of the AdaptOR MICCAI Challenge 2021 at https://adaptor2021.github.io/, and code at https://github.com/Cardio-AI/detcyclegan_pytorch.
Stereo Correspondence and Reconstruction of Endoscopic Data Challenge
Jan 28, 2021

The stereo correspondence and reconstruction of endoscopic data sub-challenge was organized during the Endovis challenge at MICCAI 2019 in Shenzhen, China. The task was to perform dense depth estimation using 7 training datasets and 2 test sets of structured light data captured using porcine cadavers. These were provided by a team at Intuitive Surgical. 10 teams participated in the challenge day. This paper contains 3 additional methods which were submitted after the challenge finished as well as a supplemental section from these teams on issues they found with the dataset.
Heatmap-based 2D Landmark Detection with a Varying Number of Landmarks
Jan 07, 2021
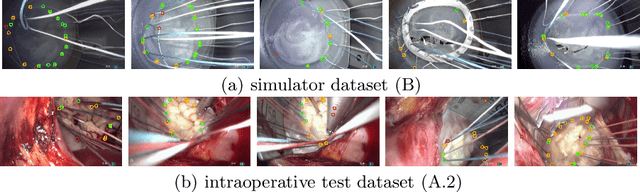
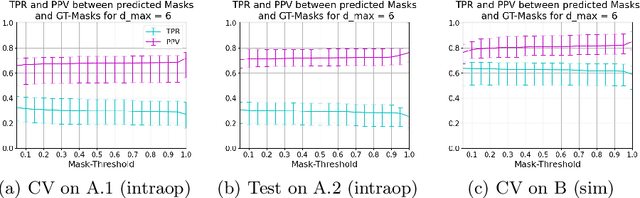
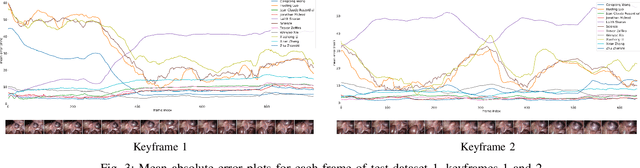
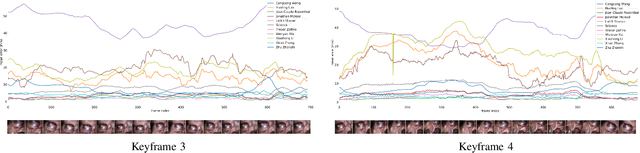
Mitral valve repair is a surgery to restore the function of the mitral valve. To achieve this, a prosthetic ring is sewed onto the mitral annulus. Analyzing the sutures, which are punctured through the annulus for ring implantation, can be useful in surgical skill assessment, for quantitative surgery and for positioning a virtual prosthetic ring model in the scene via augmented reality. This work presents a neural network approach which detects the sutures in endoscopic images of mitral valve repair and therefore solves a landmark detection problem with varying amount of landmarks, as opposed to most other existing deep learning-based landmark detection approaches. The neural network is trained separately on two data collections from different domains with the same architecture and hyperparameter settings. The datasets consist of more than 1,300 stereo frame pairs each, with a total over 60,000 annotated landmarks. The proposed heatmap-based neural network achieves a mean positive predictive value (PPV) of 66.68$\pm$4.67% and a mean true positive rate (TPR) of 24.45$\pm$5.06% on the intraoperative test dataset and a mean PPV of 81.50\pm5.77\% and a mean TPR of 61.60$\pm$6.11% on a dataset recorded during surgical simulation. The best detection results are achieved when the camera is positioned above the mitral valve with good illumination. A detection from a sideward view is also possible if the mitral valve is well perceptible.
Towards Augmented Reality-based Suturing in Monocular Laparoscopic Training
Jan 19, 2020
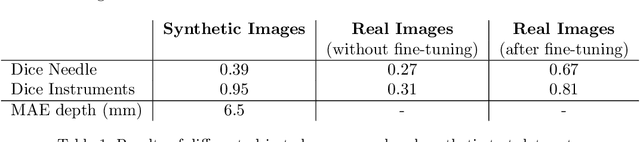
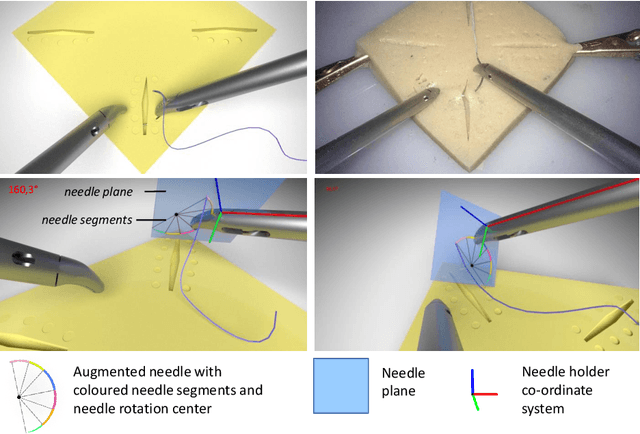

Minimally Invasive Surgery (MIS) techniques have gained rapid popularity among surgeons since they offer significant clinical benefits including reduced recovery time and diminished post-operative adverse effects. However, conventional endoscopic systems output monocular video which compromises depth perception, spatial orientation and field of view. Suturing is one of the most complex tasks performed under these circumstances. Key components of this tasks are the interplay between needle holder and the surgical needle. Reliable 3D localization of needle and instruments in real time could be used to augment the scene with additional parameters that describe their quantitative geometric relation, e.g. the relation between the estimated needle plane and its rotation center and the instrument. This could contribute towards standardization and training of basic skills and operative techniques, enhance overall surgical performance, and reduce the risk of complications. The paper proposes an Augmented Reality environment with quantitative and qualitative visual representations to enhance laparoscopic training outcomes performed on a silicone pad. This is enabled by a multi-task supervised deep neural network which performs multi-class segmentation and depth map prediction. Scarcity of labels has been conquered by creating a virtual environment which resembles the surgical training scenario to generate dense depth maps and segmentation maps. The proposed convolutional neural network was tested on real surgical training scenarios and showed to be robust to occlusion of the needle. The network achieves a dice score of 0.67 for surgical needle segmentation, 0.81 for needle holder instrument segmentation and a mean absolute error of 6.5 mm for depth estimation.
Cross-Domain Conditional Generative Adversarial Networks for Stereoscopic Hyperrealism in Surgical Training
Jun 24, 2019
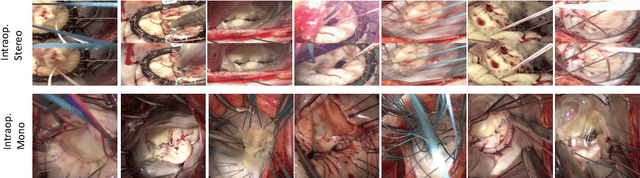
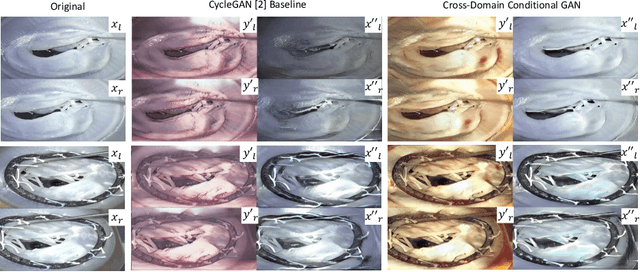
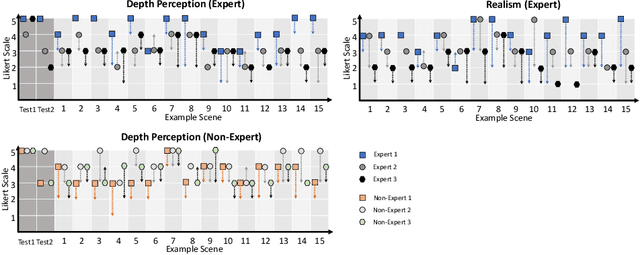
Phantoms for surgical training are able to mimic cutting and suturing properties and patient-individual shape of organs, but lack a realistic visual appearance that captures the heterogeneity of surgical scenes. In order to overcome this in endoscopic approaches, hyperrealistic concepts have been proposed to be used in an augmented reality-setting, which are based on deep image-to-image transformation methods. Such concepts are able to generate realistic representations of phantoms learned from real intraoperative endoscopic sequences. Conditioned on frames from the surgical training process, the learned models are able to generate impressive results by transforming unrealistic parts of the image (e.g.\ the uniform phantom texture is replaced by the more heterogeneous texture of the tissue). Image-to-image synthesis usually learns a mapping $G:X~\to~Y$ such that the distribution of images from $G(X)$ is indistinguishable from the distribution $Y$. However, it does not necessarily force the generated images to be consistent and without artifacts. In the endoscopic image domain this can affect depth cues and stereo consistency of a stereo image pair, which ultimately impairs surgical vision. We propose a cross-domain conditional generative adversarial network approach (GAN) that aims to generate more consistent stereo pairs. The results show substantial improvements in depth perception and realism evaluated by 3 domain experts and 3 medical students on a 3D monitor over the baseline method. In 84 of 90 instances our proposed method was preferred or rated equal to the baseline.