 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Short Term Agents for Pure-Vision Bronchoscopy Robotic Autonomy
Mar 09, 2026Accurate intraoperative navigation is essential for robot-assisted endoluminal intervention, but remains difficult because of limited endoscopic field of view and dynamic artifacts. Existing navigation platforms often rely on external localization technologies, such as electromagnetic tracking or shape sensing, which increase hardware complexity and remain vulnerable to intraoperative anatomical mismatch. We present a vision-only autonomy framework that performs long-horizon bronchoscopic navigation using preoperative CT-derived virtual targets and live endoscopic video, without external tracking during navigation. The framework uses hierarchical long-short agents: a short-term reactive agent for continuous low-latency motion control, and a long-term strategic agent for decision support at anatomically ambiguous points. When their recommendations conflict, a world-model critic predicts future visual states for candidate actions and selects the action whose predicted state best matches the target view. We evaluated the system in a high-fidelity airway phantom, three ex vivo porcine lungs, and a live porcine model. The system reached all planned segmental targets in the phantom, maintained 80\% success to the eighth generation ex vivo, and achieved in vivo navigation performance comparable to the expert bronchoscopist. These results support the preclinical feasibility of sensor-free autonomous bronchoscopic navigation.
EndoSERV: A Vision-based Endoluminal Robot Navigation System
Mar 09, 2026Robot-assisted endoluminal procedures are increasingly used for early cancer intervention. However, the intricate, narrow and tortuous pathways within the luminal anatomy pose substantial difficulties for robot navigation. Vision-based navigation offers a promising solution, but existing localization approaches are error-prone due to tissue deformation, in vivo artifacts and a lack of distinctive landmarks for consistent localization. This paper presents a novel EndoSERV localization method to address these challenges. It includes two main parts, \textit{i.e.}, \textbf{SE}gment-to-structure and \textbf{R}eal-to-\textbf{V}irtual mapping, and hence the name. For long-range and complex luminal structures, we divide them into smaller sub-segments and estimate the odometry independently. To cater for label insufficiency, an efficient transfer technique maps real image features to the virtual domain to use virtual pose ground truth. The training phases of EndoSERV include an offline pretraining to extract texture-agnostic features, and an online phase that adapts to real-world conditions. Extensive experiments based on both public and clinical datasets have been performed to demonstrate the effectiveness of the method even without any real pose labels.
TopoSculpt: Betti-Steered Topological Sculpting of 3D Fine-grained Tubular Shapes
Sep 04, 2025Medical tubular anatomical structures are inherently three-dimensional conduits with lumens, enclosing walls, and complex branching topologies. Accurate reconstruction of their geometry and topology is crucial for applications such as bronchoscopic navigation and cerebral arterial connectivity assessment. Existing methods often rely on voxel-wise overlap measures, which fail to capture topological correctness and completeness. Although topology-aware losses and persistent homology constraints have shown promise, they are usually applied patch-wise and cannot guarantee global preservation or correct geometric errors at inference. To address these limitations, we propose a novel TopoSculpt, a framework for topological refinement of 3D fine-grained tubular structures. TopoSculpt (i) adopts a holistic whole-region modeling strategy to capture full spatial context, (ii) first introduces a Topological Integrity Betti (TIB) constraint that jointly enforces Betti number priors and global integrity, and (iii) employs a curriculum refinement scheme with persistent homology to progressively correct errors from coarse to fine scales. Extensive experiments on challenging pulmonary airway and Circle of Willis datasets demonstrate substantial improvements in both geometry and topology. For instance, $\beta_{0}$ errors are reduced from 69.00 to 3.40 on the airway dataset and from 1.65 to 0.30 on the CoW dataset, with Tree length detected and branch detected rates improving by nearly 10\%. These results highlight the effectiveness of TopoSculpt in correcting critical topological errors and advancing the high-fidelity modeling of complex 3D tubular anatomy. The project homepage is available at: https://github.com/Puzzled-Hui/TopoSculpt.
From Real Artifacts to Virtual Reference: A Robust Framework for Translating Endoscopic Images
Oct 23, 2024Domain adaptation, which bridges the distributions across different modalities, plays a crucial role in multimodal medical image analysis. In endoscopic imaging, combining pre-operative data with intra-operative imaging is important for surgical planning and navigation. However, existing domain adaptation methods are hampered by distribution shift caused by in vivo artifacts, necessitating robust techniques for aligning noisy and artifact abundant patient endoscopic videos with clean virtual images reconstructed from pre-operative tomographic data for pose estimation during intraoperative guidance. This paper presents an artifact-resilient image translation method and an associated benchmark for this purpose. The method incorporates a novel ``local-global'' translation framework and a noise-resilient feature extraction strategy. For the former, it decouples the image translation process into a local step for feature denoising, and a global step for global style transfer. For feature extraction, a new contrastive learning strategy is proposed, which can extract noise-resilient features for establishing robust correspondence across domains. Detailed validation on both public and in-house clinical datasets has been conducted, demonstrating significantly improved performance compared to the current state-of-the-art.
Efficient Domain Adaptation for Endoscopic Visual Odometry
Mar 16, 2024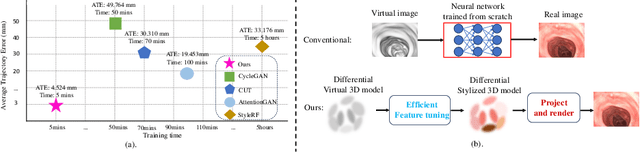
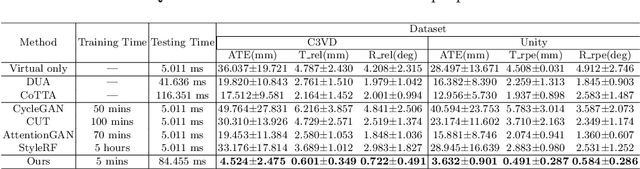
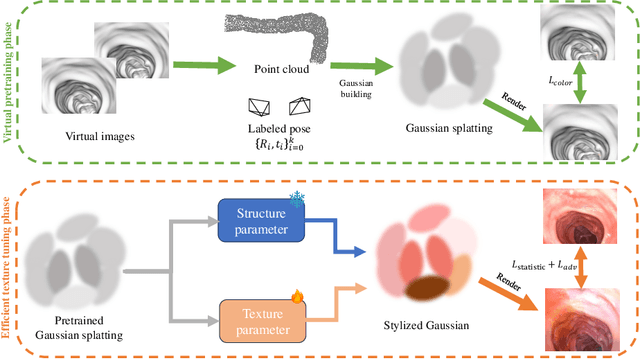
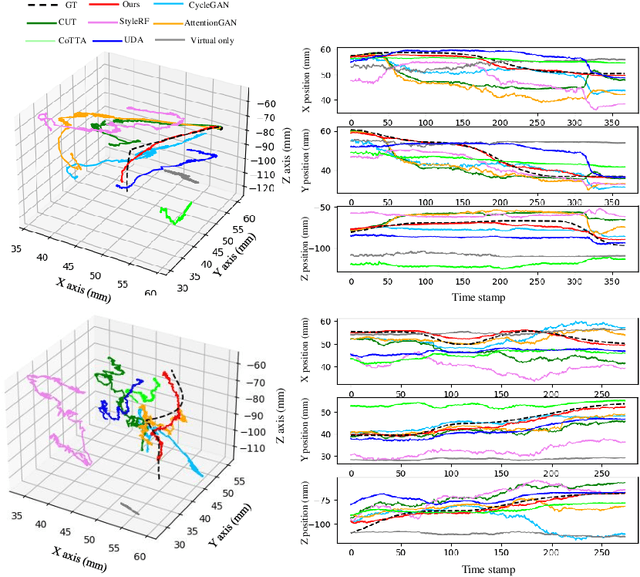
Visual odometry plays a crucial role in endoscopic imaging, yet the scarcity of realistic images with ground truth poses poses a significant challenge. Therefore, domain adaptation offers a promising approach to bridge the pre-operative planning domain with the intra-operative real domain for learning odometry information. However, existing methodologies suffer from inefficiencies in the training time. In this work, an efficient neural style transfer framework for endoscopic visual odometry is proposed, which compresses the time from pre-operative planning to testing phase to less than five minutes. For efficient traing, this work focuses on training modules with only a limited number of real images and we exploit pre-operative prior information to dramatically reduce training duration. Moreover, during the testing phase, we propose a novel Test Time Adaptation (TTA) method to mitigate the gap in lighting conditions between training and testing datasets. Experimental evaluations conducted on two public endoscope datasets showcase that our method achieves state-of-the-art accuracy in visual odometry tasks while boasting the fastest training speeds. These results demonstrate significant promise for intra-operative surgery applications.
Unleashing the Power of Depth and Pose Estimation Neural Networks by Designing Compatible Endoscopic Images
Sep 14, 2023Deep learning models have witnessed depth and pose estimation framework on unannotated datasets as a effective pathway to succeed in endoscopic navigation. Most current techniques are dedicated to developing more advanced neural networks to improve the accuracy. However, existing methods ignore the special properties of endoscopic images, resulting in an inability to fully unleash the power of neural networks. In this study, we conduct a detail analysis of the properties of endoscopic images and improve the compatibility of images and neural networks, to unleash the power of current neural networks. First, we introcude the Mask Image Modelling (MIM) module, which inputs partial image information instead of complete image information, allowing the network to recover global information from partial pixel information. This enhances the network' s ability to perceive global information and alleviates the phenomenon of local overfitting in convolutional neural networks due to local artifacts. Second, we propose a lightweight neural network to enhance the endoscopic images, to explicitly improve the compatibility between images and neural networks. Extensive experiments are conducted on the three public datasets and one inhouse dataset, and the proposed modules improve baselines by a large margin. Furthermore, the enhanced images we proposed, which have higher network compatibility, can serve as an effective data augmentation method and they are able to extract more stable feature points in traditional feature point matching tasks and achieve outstanding performance.
Real-time Workload Pattern Analysis for Large-scale Cloud Databases
Jul 05, 2023



Hosting database services on cloud systems has become a common practice. This has led to the increasing volume of database workloads, which provides the opportunity for pattern analysis. Discovering workload patterns from a business logic perspective is conducive to better understanding the trends and characteristics of the database system. However, existing workload pattern discovery systems are not suitable for large-scale cloud databases which are commonly employed by the industry. This is because the workload patterns of large-scale cloud databases are generally far more complicated than those of ordinary databases. In this paper, we propose Alibaba Workload Miner (AWM), a real-time system for discovering workload patterns in complicated large-scale workloads. AWM encodes and discovers the SQL query patterns logged from user requests and optimizes the querying processing based on the discovered patterns. First, Data Collection & Preprocessing Module collects streaming query logs and encodes them into high-dimensional feature embeddings with rich semantic contexts and execution features. Next, Online Workload Mining Module separates encoded queries by business groups and discovers the workload patterns for each group. Meanwhile, Offline Training Module collects labels and trains the classification model using the labels. Finally, Pattern-based Optimizing Module optimizes query processing in cloud databases by exploiting discovered patterns. Extensive experimental results on one synthetic dataset and two real-life datasets (extracted from Alibaba Cloud databases) show that AWM enhances the accuracy of pattern discovery by 66% and reduce the latency of online inference by 22%, compared with the state-of-the-arts.
SEA: A Scalable Entity Alignment System
Apr 14, 2023



Entity alignment (EA) aims to find equivalent entities in different knowledge graphs (KGs). State-of-the-art EA approaches generally use Graph Neural Networks (GNNs) to encode entities. However, most of them train the models and evaluate the results in a fullbatch fashion, which prohibits EA from being scalable on largescale datasets. To enhance the usability of GNN-based EA models in real-world applications, we present SEA, a scalable entity alignment system that enables to (i) train large-scale GNNs for EA, (ii) speed up the normalization and the evaluation process, and (iii) report clear results for users to estimate different models and parameter settings. SEA can be run on a computer with merely one graphic card. Moreover, SEA encompasses six state-of-the-art EA models and provides access for users to quickly establish and evaluate their own models. Thus, SEA allows users to perform EA without being involved in tedious implementations, such as negative sampling and GPU-accelerated evaluation. With SEA, users can gain a clear view of the model performance. In the demonstration, we show that SEA is user-friendly and is of high scalability even on computers with limited computational resources.
Unsupervised Entity Alignment for Temporal Knowledge Graphs
Feb 08, 2023Entity alignment (EA) is a fundamental data integration task that identifies equivalent entities between different knowledge graphs (KGs). Temporal Knowledge graphs (TKGs) extend traditional knowledge graphs by introducing timestamps, which have received increasing attention. State-of-the-art time-aware EA studies have suggested that the temporal information of TKGs facilitates the performance of EA. However, existing studies have not thoroughly exploited the advantages of temporal information in TKGs. Also, they perform EA by pre-aligning entity pairs, which can be labor-intensive and thus inefficient. In this paper, we present DualMatch which effectively fuses the relational and temporal information for EA. DualMatch transfers EA on TKGs into a weighted graph matching problem. More specifically, DualMatch is equipped with an unsupervised method, which achieves EA without necessitating seed alignment. DualMatch has two steps: (i) encoding temporal and relational information into embeddings separately using a novel label-free encoder, Dual-Encoder; and (ii) fusing both information and transforming it into alignment using a novel graph-matching-based decoder, GM-Decoder. DualMatch is able to perform EA on TKGs with or without supervision, due to its capability of effectively capturing temporal information. Extensive experiments on three real-world TKG datasets offer the insight that DualMatch outperforms the state-of-the-art methods in terms of H@1 by 2.4% - 10.7% and MRR by 1.7% - 7.6%, respectively.
Unleashing the Power of Visual Prompting At the Pixel Level
Dec 20, 2022This paper presents a simple and effective visual prompting method for adapting pre-trained models to downstream recognition tasks. Our method includes two key designs. First, rather than directly adding together the prompt and the image, we treat the prompt as an extra and independent learnable component. We show that the strategy of reconciling the prompt and the image matters, and find that warping the prompt around a properly shrinked image empirically works the best. Second, we re-introduce two "old tricks" commonly used in building transferable adversarial examples, i.e., input diversity and gradient normalization, into visual prompting. These techniques improve optimization and enable the prompt to generalize better. We provide extensive experimental results to demonstrate the effectiveness of our method. Using a CLIP model, our prompting method sets a new record of 82.8% average accuracy across 12 popular classification datasets, substantially surpassing the prior art by +5.6%. It is worth noting that this prompting performance already outperforms linear probing by +2.1% and can even match fully fine-tuning in certain datasets. In addition, our prompting method shows competitive performance across different data scales and against distribution shifts. The code is publicly available at https://github.com/UCSC-VLAA/EVP.