 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEndoSERV: A Vision-based Endoluminal Robot Navigation System
Mar 09, 2026Robot-assisted endoluminal procedures are increasingly used for early cancer intervention. However, the intricate, narrow and tortuous pathways within the luminal anatomy pose substantial difficulties for robot navigation. Vision-based navigation offers a promising solution, but existing localization approaches are error-prone due to tissue deformation, in vivo artifacts and a lack of distinctive landmarks for consistent localization. This paper presents a novel EndoSERV localization method to address these challenges. It includes two main parts, \textit{i.e.}, \textbf{SE}gment-to-structure and \textbf{R}eal-to-\textbf{V}irtual mapping, and hence the name. For long-range and complex luminal structures, we divide them into smaller sub-segments and estimate the odometry independently. To cater for label insufficiency, an efficient transfer technique maps real image features to the virtual domain to use virtual pose ground truth. The training phases of EndoSERV include an offline pretraining to extract texture-agnostic features, and an online phase that adapts to real-world conditions. Extensive experiments based on both public and clinical datasets have been performed to demonstrate the effectiveness of the method even without any real pose labels.
Long-Short Term Agents for Pure-Vision Bronchoscopy Robotic Autonomy
Mar 09, 2026Accurate intraoperative navigation is essential for robot-assisted endoluminal intervention, but remains difficult because of limited endoscopic field of view and dynamic artifacts. Existing navigation platforms often rely on external localization technologies, such as electromagnetic tracking or shape sensing, which increase hardware complexity and remain vulnerable to intraoperative anatomical mismatch. We present a vision-only autonomy framework that performs long-horizon bronchoscopic navigation using preoperative CT-derived virtual targets and live endoscopic video, without external tracking during navigation. The framework uses hierarchical long-short agents: a short-term reactive agent for continuous low-latency motion control, and a long-term strategic agent for decision support at anatomically ambiguous points. When their recommendations conflict, a world-model critic predicts future visual states for candidate actions and selects the action whose predicted state best matches the target view. We evaluated the system in a high-fidelity airway phantom, three ex vivo porcine lungs, and a live porcine model. The system reached all planned segmental targets in the phantom, maintained 80\% success to the eighth generation ex vivo, and achieved in vivo navigation performance comparable to the expert bronchoscopist. These results support the preclinical feasibility of sensor-free autonomous bronchoscopic navigation.
From Real Artifacts to Virtual Reference: A Robust Framework for Translating Endoscopic Images
Oct 23, 2024Domain adaptation, which bridges the distributions across different modalities, plays a crucial role in multimodal medical image analysis. In endoscopic imaging, combining pre-operative data with intra-operative imaging is important for surgical planning and navigation. However, existing domain adaptation methods are hampered by distribution shift caused by in vivo artifacts, necessitating robust techniques for aligning noisy and artifact abundant patient endoscopic videos with clean virtual images reconstructed from pre-operative tomographic data for pose estimation during intraoperative guidance. This paper presents an artifact-resilient image translation method and an associated benchmark for this purpose. The method incorporates a novel ``local-global'' translation framework and a noise-resilient feature extraction strategy. For the former, it decouples the image translation process into a local step for feature denoising, and a global step for global style transfer. For feature extraction, a new contrastive learning strategy is proposed, which can extract noise-resilient features for establishing robust correspondence across domains. Detailed validation on both public and in-house clinical datasets has been conducted, demonstrating significantly improved performance compared to the current state-of-the-art.
Trajectory optimization of tail-sitter considering speed constraints
Jun 12, 2024



Tail-sitters combine the advantages of fixed-wing unmanned aerial vehicles (UAVs) and vertical take-off and landing UAVs, and have been widely designed and researched in recent years. With the change in modern UAV application scenarios, it is required that UAVs have fast maneuverable three-dimensional flight capabilities. Due to the highly nonlinear aerodynamics produced by the fuselage and wings of the tail-sitter, how to quickly generate a smooth and executable trajectory is a problem that needs to be solved urgently. We constrain the speed of the tail-sitter, eliminate the differential dynamics constraints in the trajectory generation process of the tail-sitter through differential flatness, and allocate the time variable of the trajectory through the state-of-the-art trajectory generation method named MINCO. Because we discretize the trajectory in time, we convert the speed constraint on the vehicle into a soft constraint, thereby achieving the time-optimal trajectory for the tail-sitter to fly through any given waypoints.
Alleviating Class-wise Gradient Imbalance for Pulmonary Airway Segmentation
Nov 24, 2020
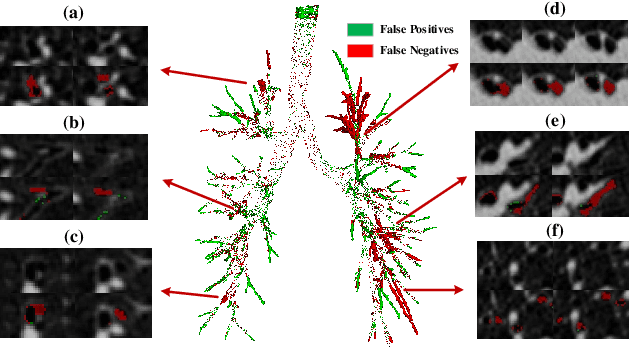
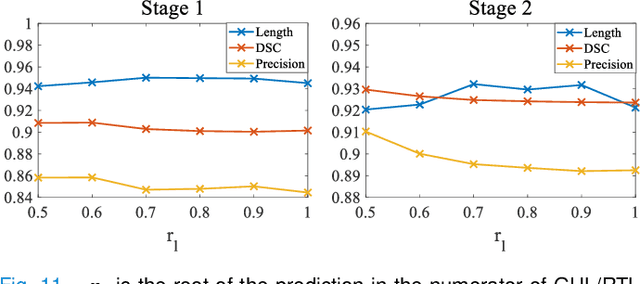
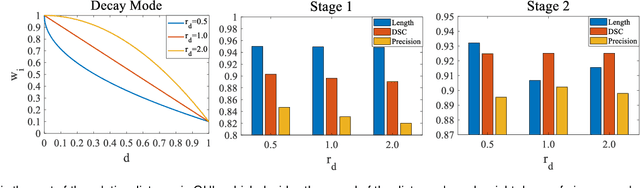
Automated airway segmentation is a prerequisite for pre-operative diagnosis and intra-operative navigation for pulmonary intervention. Due to the small size and scattered spatial distribution of peripheral bronchi, this is hampered by severe class imbalance between foreground and background regions, which makes it challenging for CNN-based methods to parse distal small airways. In this paper, we demonstrate that this problem is arisen by gradient erosion and dilation of the neighborhood voxels. During back-propagation, if the ratio of the foreground gradient to background gradient is small while the class imbalance is local, the foreground gradients can be eroded by their neighborhoods. This process cumulatively increases the noise information included in the gradient flow from top layers to the bottom ones, limiting the learning of small structures in CNNs. To alleviate this problem, we use group supervision and the corresponding WingsNet to provide complementary gradient flows to enhance the training of shallow layers. To further address the intra-class imbalance between large and small airways, we design a General Union loss function which obviates the impact of airway size by distance-based weights and adaptively tunes the gradient ratio based on the learning process. Extensive experiments on public datasets demonstrate that the proposed method can predict the airway structures with higher accuracy and better morphological completeness.