 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNAIS: Neural Architecture and Implementation Search and its Applications in Autonomous Driving
Nov 18, 2019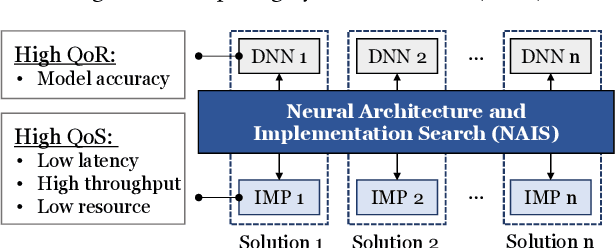

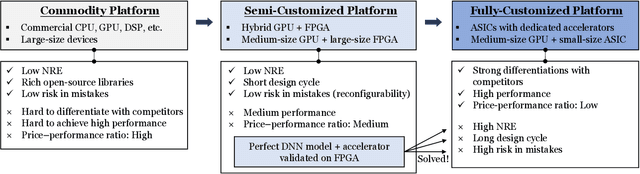

The rapidly growing demands for powerful AI algorithms in many application domains have motivated massive investment in both high-quality deep neural network (DNN) models and high-efficiency implementations. In this position paper, we argue that a simultaneous DNN/implementation co-design methodology, named Neural Architecture and Implementation Search (NAIS), deserves more research attention to boost the development productivity and efficiency of both DNN models and implementation optimization. We propose a stylized design methodology that can drastically cut down the search cost while preserving the quality of the end solution.As an illustration, we discuss this DNN/implementation methodology in the context of both FPGAs and GPUs. We take autonomous driving as a key use case as it is one of the most demanding areas for high quality AI algorithms and accelerators. We discuss how such a co-design methodology can impact the autonomous driving industry significantly. We identify several research opportunities in this exciting domain.
Self-Supervised Learning of Depth and Ego-motion with Differentiable Bundle Adjustment
Sep 28, 2019
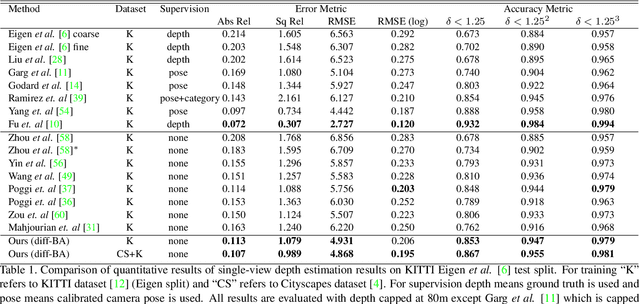
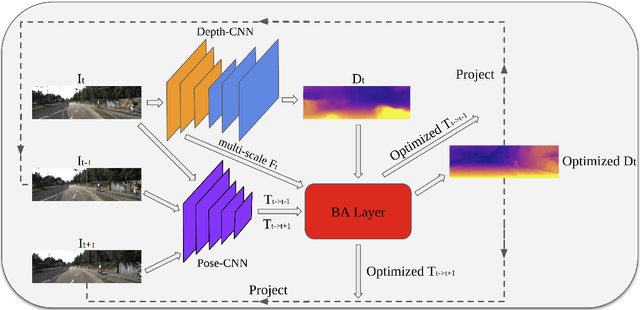
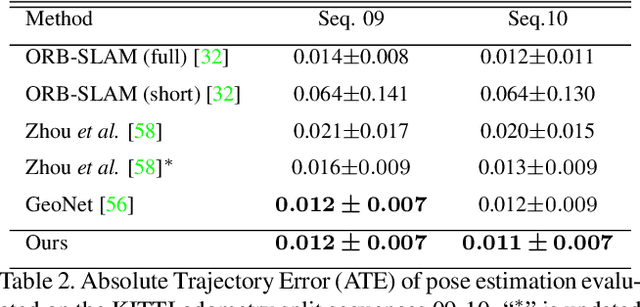
Learning to predict scene depth and camera motion from RGB inputs only is a challenging task. Most existing learning based methods deal with this task in a supervised manner which require ground-truth data that is expensive to acquire. More recent approaches explore the possibility of estimating scene depth and camera pose in a self-supervised learning framework. Despite encouraging results are shown, current methods either learn from monocular videos for depth and pose and typically do so without enforcing multi-view geometry constraints between scene structure and camera motion, or require stereo sequences as input where the ground-truth between-frame motion parameters need to be known. In this paper we propose to jointly optimize the scene depth and camera motion via incorporating differentiable Bundle Adjustment (BA) layer by minimizing the feature-metric error, and then form the photometric consistency loss with view synthesis as the final supervisory signal. The proposed approach only needs unlabeled monocular videos as input, and extensive experiments on the KITTI and Cityscapes dataset show that our method achieves state-of-the-art results in self-supervised approaches using monocular videos as input, and even gains advantage to the line of methods that learns from calibrated stereo sequences (i.e. with pose supervision).
Structure-Attentioned Memory Network for Monocular Depth Estimation
Sep 10, 2019
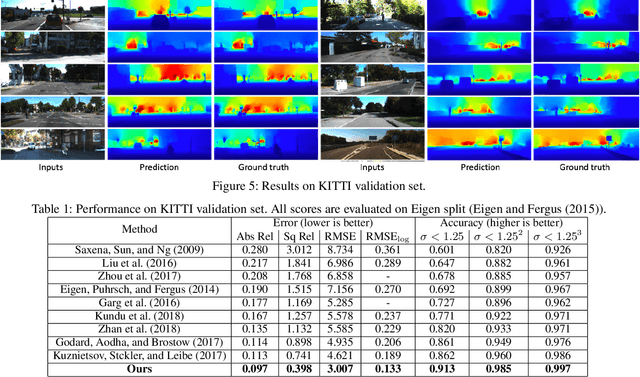
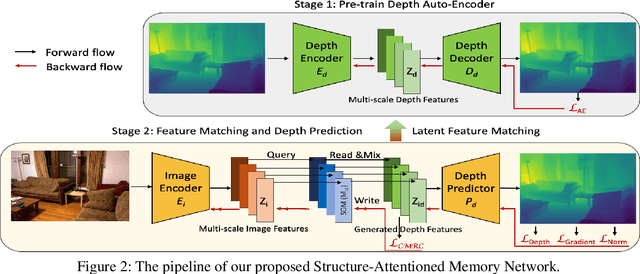
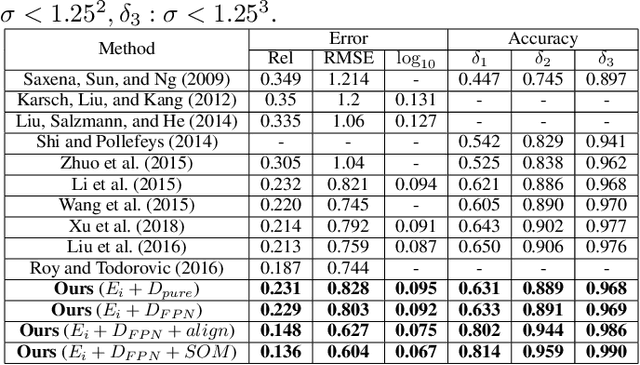
Monocular depth estimation is a challenging task that aims to predict a corresponding depth map from a given single RGB image. Recent deep learning models have been proposed to predict the depth from the image by learning the alignment of deep features between the RGB image and the depth domains. In this paper, we present a novel approach, named Structure-Attentioned Memory Network, to more effectively transfer domain features for monocular depth estimation by taking into account the common structure regularities (e.g., repetitive structure patterns, planar surfaces, symmetries) in domain adaptation. To this end, we introduce a new Structure-Oriented Memory (SOM) module to learn and memorize the structure-specific information between RGB image domain and the depth domain. More specifically, in the SOM module, we develop a Memorable Bank of Filters (MBF) unit to learn a set of filters that memorize the structure-aware image-depth residual pattern, and also an Attention Guided Controller (AGC) unit to control the filter selection in the MBF given image features queries. Given the query image feature, the trained SOM module is able to adaptively select the best customized filters for cross-domain feature transferring with an optimal structural disparity between image and depth. In summary, we focus on addressing this structure-specific domain adaption challenge by proposing a novel end-to-end multi-scale memorable network for monocular depth estimation. The experiments show that our proposed model demonstrates the superior performance compared to the existing supervised monocular depth estimation approaches on the challenging KITTI and NYU Depth V2 benchmarks.
Learning Object-specific Distance from a Monocular Image
Sep 09, 2019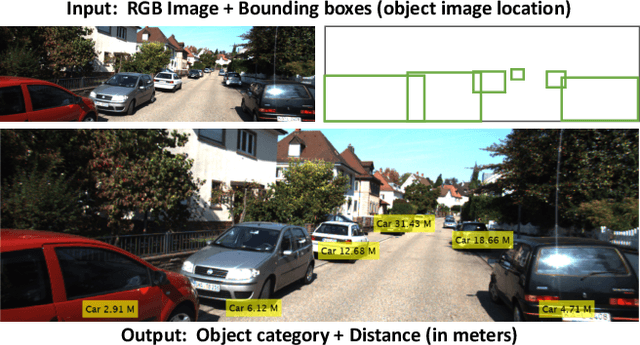
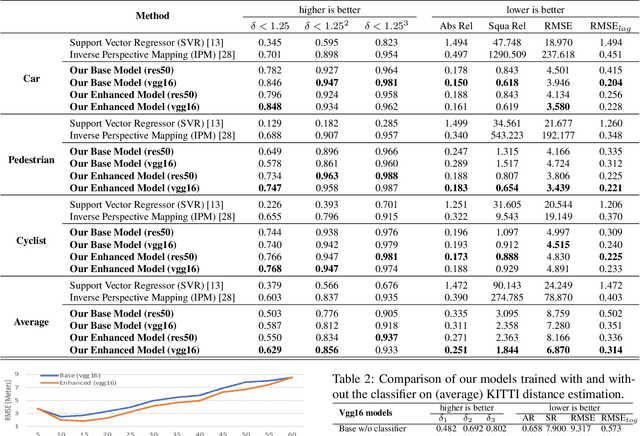
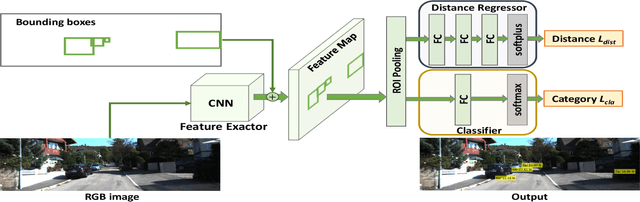

Environment perception, including object detection and distance estimation, is one of the most crucial tasks for autonomous driving. Many attentions have been paid on the object detection task, but distance estimation only arouse few interests in the computer vision community. Observing that the traditional inverse perspective mapping algorithm performs poorly for objects far away from the camera or on the curved road, in this paper, we address the challenging distance estimation problem by developing the first end-to-end learning-based model to directly predict distances for given objects in the images. Besides the introduction of a learning-based base model, we further design an enhanced model with a keypoint regressor, where a projection loss is defined to enforce a better distance estimation, especially for objects close to the camera. To facilitate the research on this task, we construct the extented KITTI and nuScenes (mini) object detection datasets with a distance for each object. Our experiments demonstrate that our proposed methods outperform alternative approaches (e.g., the traditional IPM, SVR) on object-specific distance estimation, particularly for the challenging cases that objects are on a curved road. Moreover, the performance margin implies the effectiveness of our enhanced method.