 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Learning of Depth and Ego-motion with Differentiable Bundle Adjustment
Sep 28, 2019
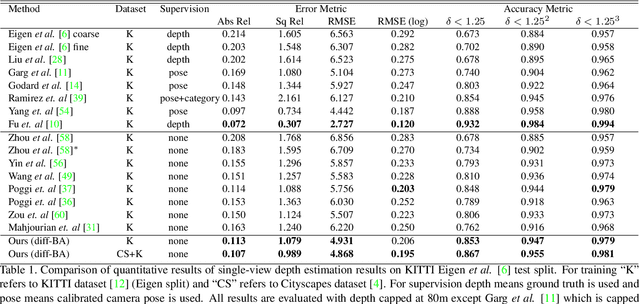
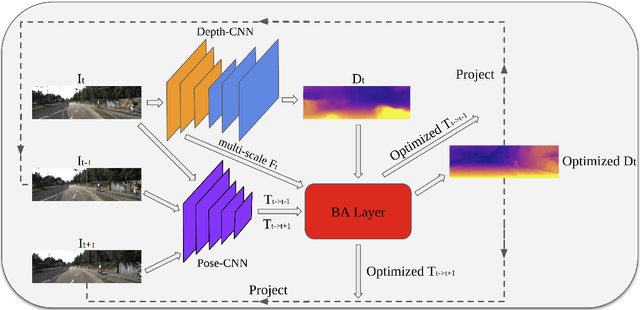
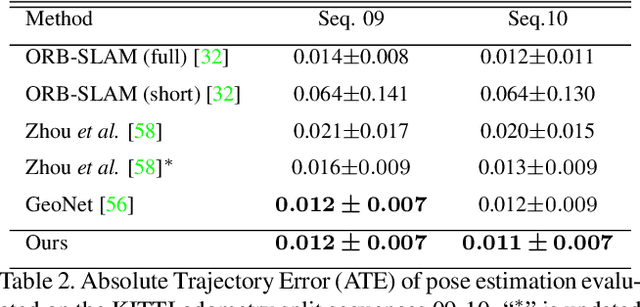
Learning to predict scene depth and camera motion from RGB inputs only is a challenging task. Most existing learning based methods deal with this task in a supervised manner which require ground-truth data that is expensive to acquire. More recent approaches explore the possibility of estimating scene depth and camera pose in a self-supervised learning framework. Despite encouraging results are shown, current methods either learn from monocular videos for depth and pose and typically do so without enforcing multi-view geometry constraints between scene structure and camera motion, or require stereo sequences as input where the ground-truth between-frame motion parameters need to be known. In this paper we propose to jointly optimize the scene depth and camera motion via incorporating differentiable Bundle Adjustment (BA) layer by minimizing the feature-metric error, and then form the photometric consistency loss with view synthesis as the final supervisory signal. The proposed approach only needs unlabeled monocular videos as input, and extensive experiments on the KITTI and Cityscapes dataset show that our method achieves state-of-the-art results in self-supervised approaches using monocular videos as input, and even gains advantage to the line of methods that learns from calibrated stereo sequences (i.e. with pose supervision).