 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobally Optimal Training of Neural Networks with Threshold Activation Functions
Mar 06, 2023Threshold activation functions are highly preferable in neural networks due to their efficiency in hardware implementations. Moreover, their mode of operation is more interpretable and resembles that of biological neurons. However, traditional gradient based algorithms such as Gradient Descent cannot be used to train the parameters of neural networks with threshold activations since the activation function has zero gradient except at a single non-differentiable point. To this end, we study weight decay regularized training problems of deep neural networks with threshold activations. We first show that regularized deep threshold network training problems can be equivalently formulated as a standard convex optimization problem, which parallels the LASSO method, provided that the last hidden layer width exceeds a certain threshold. We also derive a simplified convex optimization formulation when the dataset can be shattered at a certain layer of the network. We corroborate our theoretical results with various numerical experiments.
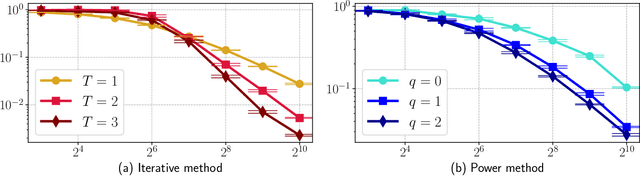
Newton-LESS: Sparsification without Trade-offs for the Sketched Newton Update
Jul 15, 2021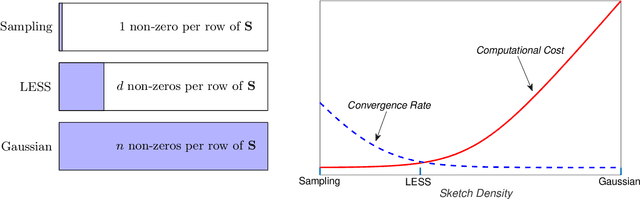
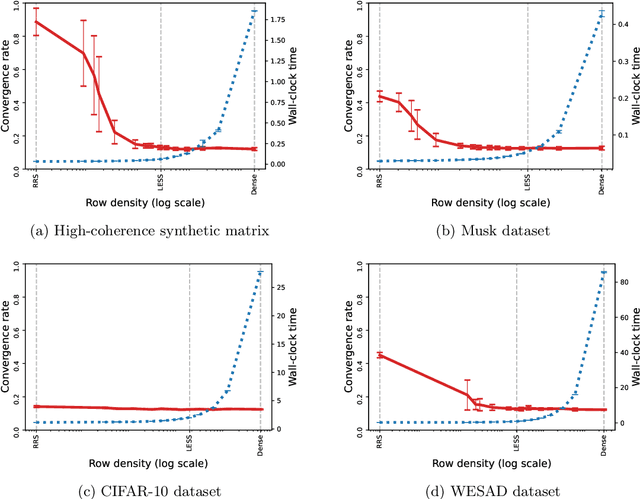
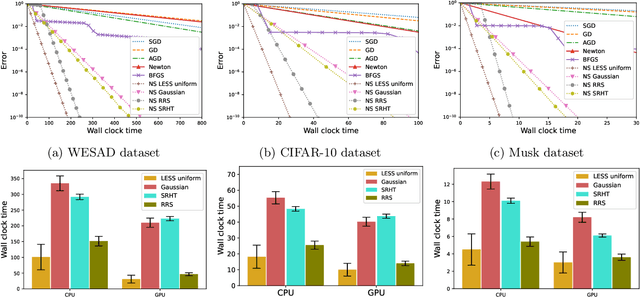
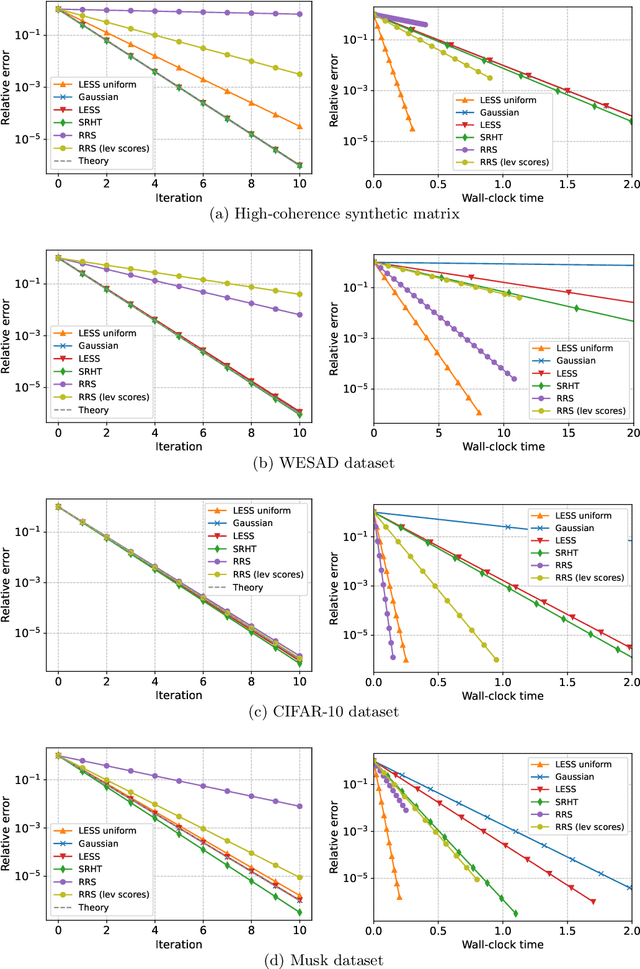
In second-order optimization, a potential bottleneck can be computing the Hessian matrix of the optimized function at every iteration. Randomized sketching has emerged as a powerful technique for constructing estimates of the Hessian which can be used to perform approximate Newton steps. This involves multiplication by a random sketching matrix, which introduces a trade-off between the computational cost of sketching and the convergence rate of the optimization algorithm. A theoretically desirable but practically much too expensive choice is to use a dense Gaussian sketching matrix, which produces unbiased estimates of the exact Newton step and which offers strong problem-independent convergence guarantees. We show that the Gaussian sketching matrix can be drastically sparsified, significantly reducing the computational cost of sketching, without substantially affecting its convergence properties. This approach, called Newton-LESS, is based on a recently introduced sketching technique: LEverage Score Sparsified (LESS) embeddings. We prove that Newton-LESS enjoys nearly the same problem-independent local convergence rate as Gaussian embeddings, not just up to constant factors but even down to lower order terms, for a large class of optimization tasks. In particular, this leads to a new state-of-the-art convergence result for an iterative least squares solver. Finally, we extend LESS embeddings to include uniformly sparsified random sign matrices which can be implemented efficiently and which perform well in numerical experiments.
Adaptive Newton Sketch: Linear-time Optimization with Quadratic Convergence and Effective Hessian Dimensionality
May 15, 2021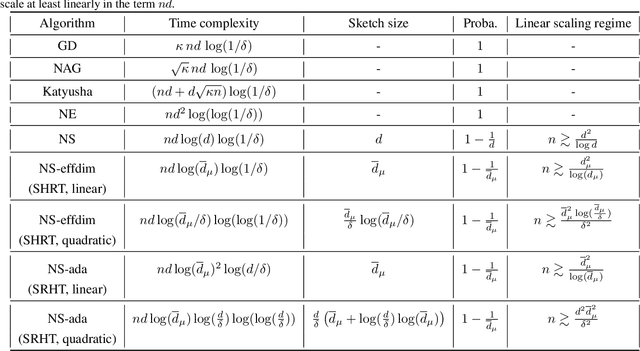
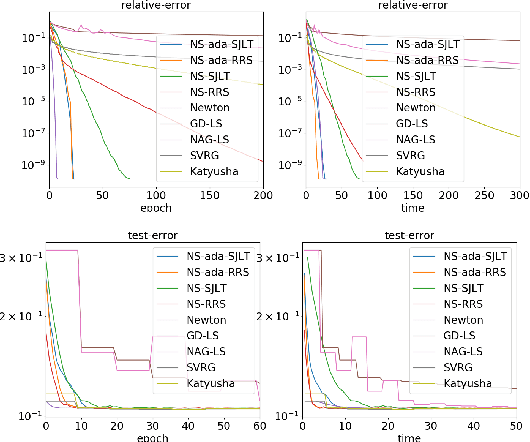
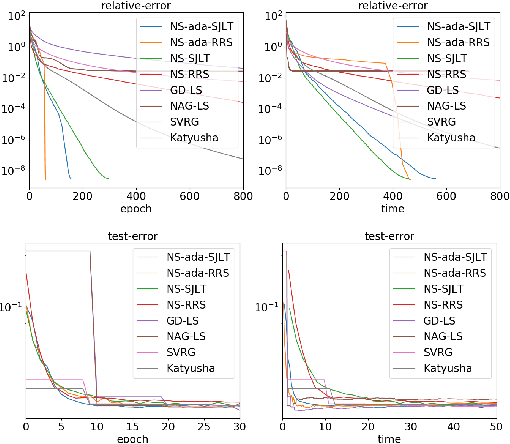
We propose a randomized algorithm with quadratic convergence rate for convex optimization problems with a self-concordant, composite, strongly convex objective function. Our method is based on performing an approximate Newton step using a random projection of the Hessian. Our first contribution is to show that, at each iteration, the embedding dimension (or sketch size) can be as small as the effective dimension of the Hessian matrix. Leveraging this novel fundamental result, we design an algorithm with a sketch size proportional to the effective dimension and which exhibits a quadratic rate of convergence. This result dramatically improves on the classical linear-quadratic convergence rates of state-of-the-art sub-sampled Newton methods. However, in most practical cases, the effective dimension is not known beforehand, and this raises the question of how to pick a sketch size as small as the effective dimension while preserving a quadratic convergence rate. Our second and main contribution is thus to propose an adaptive sketch size algorithm with quadratic convergence rate and which does not require prior knowledge or estimation of the effective dimension: at each iteration, it starts with a small sketch size, and increases it until quadratic progress is achieved. Importantly, we show that the embedding dimension remains proportional to the effective dimension throughout the entire path and that our method achieves state-of-the-art computational complexity for solving convex optimization programs with a strongly convex component.
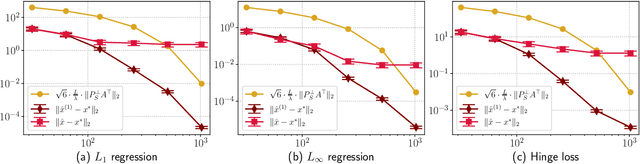
Fast Convex Quadratic Optimization Solvers with Adaptive Sketching-based Preconditioners
Apr 29, 2021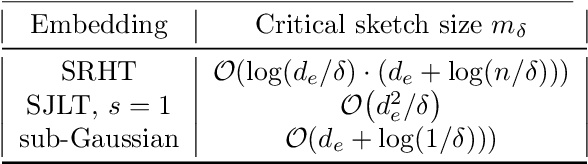



We consider least-squares problems with quadratic regularization and propose novel sketching-based iterative methods with an adaptive sketch size. The sketch size can be as small as the effective dimension of the data matrix to guarantee linear convergence. However, a major difficulty in choosing the sketch size in terms of the effective dimension lies in the fact that the latter is usually unknown in practice. Current sketching-based solvers for regularized least-squares fall short on addressing this issue. Our main contribution is to propose adaptive versions of standard sketching-based iterative solvers, namely, the iterative Hessian sketch and the preconditioned conjugate gradient method, that do not require a priori estimation of the effective dimension. We propose an adaptive mechanism to control the sketch size according to the progress made in each step of the iterative solver. If enough progress is not made, the sketch size increases to improve the convergence rate. We prove that the adaptive sketch size scales at most in terms of the effective dimension, and that our adaptive methods are guaranteed to converge linearly. Consequently, our adaptive methods improve the state-of-the-art complexity for solving dense, ill-conditioned least-squares problems. Importantly, we illustrate numerically on several synthetic and real datasets that our method is extremely efficient and is often significantly faster than standard least-squares solvers such as a direct factorization based solver, the conjugate gradient method and its preconditioned variants.
Adaptive and Oblivious Randomized Subspace Methods for High-Dimensional Optimization: Sharp Analysis and Lower Bounds
Dec 13, 2020
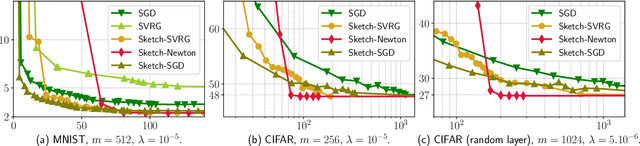
We propose novel randomized optimization methods for high-dimensional convex problems based on restrictions of variables to random subspaces. We consider oblivious and data-adaptive subspaces and study their approximation properties via convex duality and Fenchel conjugates. A suitable adaptive subspace can be generated by sampling a correlated random matrix whose second order statistics mirror the input data. We illustrate that the adaptive strategy can significantly outperform the standard oblivious sampling method, which is widely used in the recent literature. We show that the relative error of the randomized approximations can be tightly characterized in terms of the spectrum of the data matrix and Gaussian width of the dual tangent cone at optimum. We develop lower bounds for both optimization and statistical error measures based on concentration of measure and Fano's inequality. We then present the consequences of our theory with data matrices of varying spectral decay profiles. Experimental results show that the proposed approach enables significant speed ups in a wide variety of machine learning and optimization problems including logistic regression, kernel classification with random convolution layers and shallow neural networks with rectified linear units.
All Local Minima are Global for Two-Layer ReLU Neural Networks: The Hidden Convex Optimization Landscape
Jun 10, 2020
We are interested in two-layer ReLU neural networks from an optimization perspective. We prove that the path-connected sublevel set, i.e., valleys, of a neural network which is Clarke stationary with respect to the training loss with weight decay regularization contains a specific, simpler and more structured neural network, which we call its minimal representation. We provide an explicit construction of a continuous path between the neural network and its minimal counterpart. Importantly, we show that characterizing the optimality properties of a neural network can be reduced to characterizing those of its minimal representation. Thanks to the specific structure of minimal neural networks, we show that we can embed them into a convex optimization landscape. Leveraging convexity, we are able to (i) characterize the minimal size of the hidden layer so that the neural network optimization landscape has no spurious valleys and (ii) provide a polynomial-time algorithm for checking if a neural network is a global minimum of the training loss. Overall, we provide a rich framework for studying the landscape of the neural network training loss through our embedding to a convex optimization landscape.
Effective Dimension Adaptive Sketching Methods for Faster Regularized Least-Squares Optimization
Jun 10, 2020
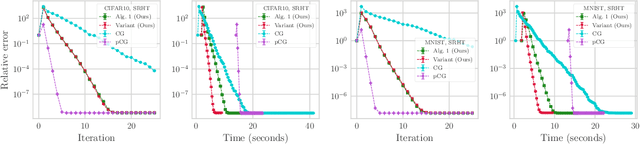

We propose a new randomized algorithm for solving L2-regularized least-squares problems based on sketching. We consider two of the most popular random embeddings, namely, Gaussian embeddings and the Subsampled Randomized Hadamard Transform (SRHT). While current randomized solvers for least-squares optimization prescribe an embedding dimension at least greater than the data dimension, we show that the embedding dimension can be reduced to the effective dimension of the optimization problem, and still preserve high-probability convergence guarantees. In this regard, we derive sharp matrix deviation inequalities over ellipsoids for both Gaussian and SRHT embeddings. Specifically, we improve on the constant of a classical Gaussian concentration bound whereas, for SRHT embeddings, our deviation inequality involves a novel technical approach. Leveraging these bounds, we are able to design a practical and adaptive algorithm which does not require to know the effective dimension beforehand. Our method starts with an initial embedding dimension equal to 1 and, over iterations, increases the embedding dimension up to the effective one. Finally, we prove that our algorithm improves the state-of-the-art computational complexity for solving regularized least-squares problems. Further, we show numerically that it outperforms standard least-squares solvers such as the conjugate gradient method and its pre-conditioned version on several standard machine learning datasets.
Optimal Randomized First-Order Methods for Least-Squares Problems
Feb 26, 2020

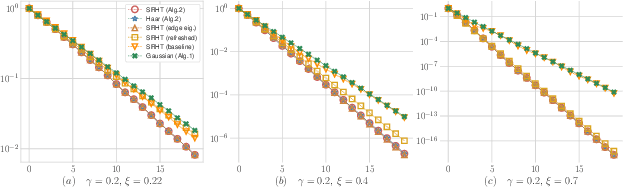
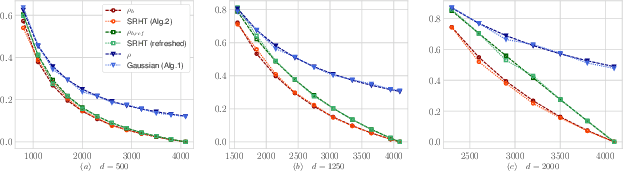
We provide an exact analysis of a class of randomized algorithms for solving overdetermined least-squares problems. We consider first-order methods, where the gradients are pre-conditioned by an approximation of the Hessian, based on a subspace embedding of the data matrix. This class of algorithms encompasses several randomized methods among the fastest solvers for least-squares problems. We focus on two classical embeddings, namely, Gaussian projections and subsampled randomized Hadamard transforms (SRHT). Our key technical innovation is the derivation of the limiting spectral density of SRHT embeddings. Leveraging this novel result, we derive the family of normalized orthogonal polynomials of the SRHT density and we find the optimal pre-conditioned first-order method along with its rate of convergence. Our analysis of Gaussian embeddings proceeds similarly, and leverages classical random matrix theory results. In particular, we show that for a given sketch size, SRHT embeddings exhibits a faster rate of convergence than Gaussian embeddings. Then, we propose a new algorithm by optimizing the computational complexity over the choice of the sketching dimension. To our knowledge, our resulting algorithm yields the best known complexity for solving least-squares problems with no condition number dependence.
Limiting Spectrum of Randomized Hadamard Transform and Optimal Iterative Sketching Methods
Feb 21, 2020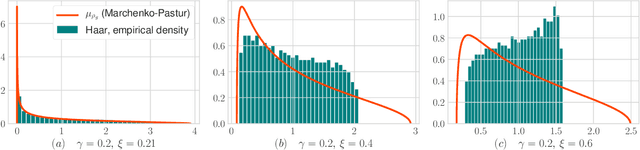
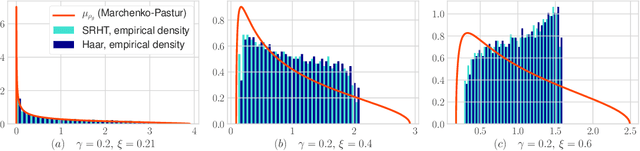
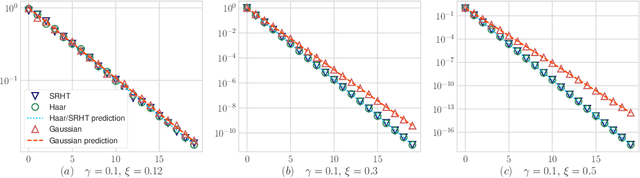
We provide an exact analysis of the limiting spectrum of matrices randomly projected either with the subsampled randomized Hadamard transform, or truncated Haar matrices. We characterize this limiting distribution through its Stieltjes transform, a classical object in random matrix theory, and compute the first and second inverse moments. We leverage the limiting spectrum and asymptotic freeness of random matrices to obtain an exact analysis of iterative sketching methods for solving least squares problems. Our results also yield optimal step-sizes and convergence rates in terms of simple closed-form expressions. Moreover, we show that the convergence rate for Haar and randomized Hadamard matrices are identical, and uniformly improve upon Gaussian random projections. The developed techniques and formulas can be applied to a plethora of randomized algorithms that employ fast randomized Hadamard dimension reduction.
High-Dimensional Optimization in Adaptive Random Subspaces
Jul 08, 2019


We propose a new randomized optimization method for high-dimensional problems which can be seen as a generalization of coordinate descent to random subspaces. We show that an adaptive sampling strategy for the random subspace significantly outperforms the oblivious sampling method, which is the common choice in the recent literature. The adaptive subspace can be efficiently generated by a correlated random matrix ensemble whose statistics mimic the input data. We prove that the improvement in the relative error of the solution can be tightly characterized in terms of the spectrum of the data matrix, and provide probabilistic upper-bounds. We then illustrate the consequences of our theory with data matrices of different spectral decay. Extensive experimental results show that the proposed approach offers significant speed ups in machine learning problems including logistic regression, kernel classification with random convolution layers and shallow neural networks with rectified linear units. Our analysis is based on convex analysis and Fenchel duality, and establishes connections to sketching and randomized matrix decomposition.