 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Reinforcement Learning: Observing Rewards at a Cost
Nov 24, 2020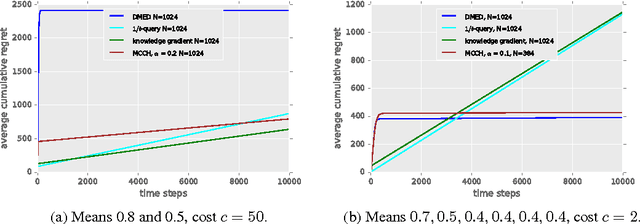

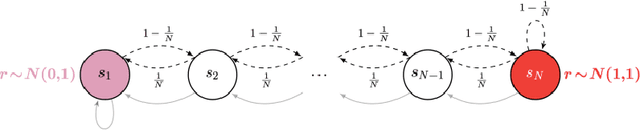
Active reinforcement learning (ARL) is a variant on reinforcement learning where the agent does not observe the reward unless it chooses to pay a query cost c > 0. The central question of ARL is how to quantify the long-term value of reward information. Even in multi-armed bandits, computing the value of this information is intractable and we have to rely on heuristics. We propose and evaluate several heuristic approaches for ARL in multi-armed bandits and (tabular) Markov decision processes, and discuss and illustrate some challenging aspects of the ARL problem.
When Will AI Exceed Human Performance? Evidence from AI Experts
May 03, 2018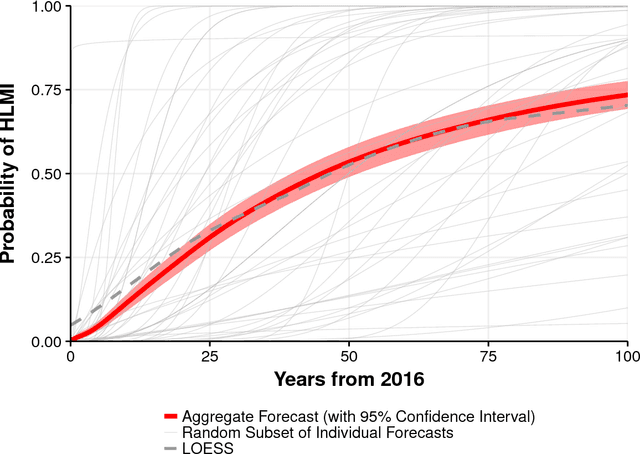
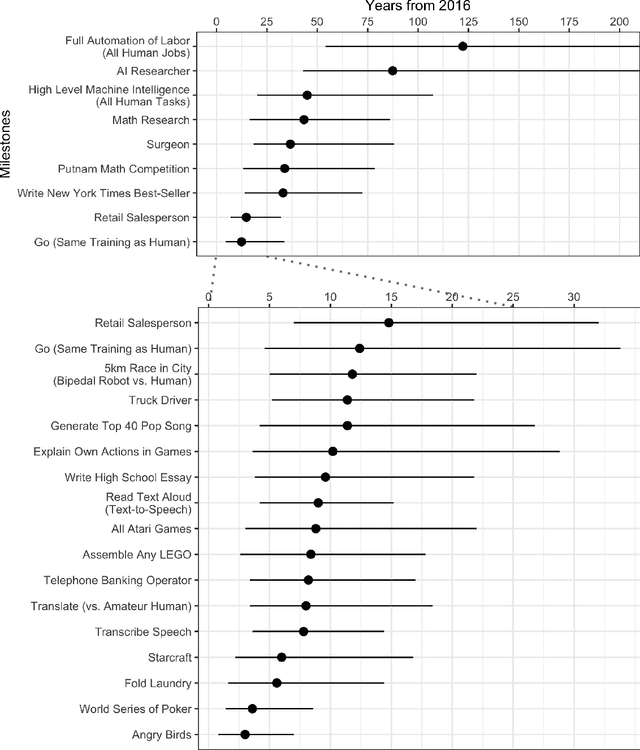


Advances in artificial intelligence (AI) will transform modern life by reshaping transportation, health, science, finance, and the military. To adapt public policy, we need to better anticipate these advances. Here we report the results from a large survey of machine learning researchers on their beliefs about progress in AI. Researchers predict AI will outperform humans in many activities in the next ten years, such as translating languages (by 2024), writing high-school essays (by 2026), driving a truck (by 2027), working in retail (by 2031), writing a bestselling book (by 2049), and working as a surgeon (by 2053). Researchers believe there is a 50% chance of AI outperforming humans in all tasks in 45 years and of automating all human jobs in 120 years, with Asian respondents expecting these dates much sooner than North Americans. These results will inform discussion amongst researchers and policymakers about anticipating and managing trends in AI.
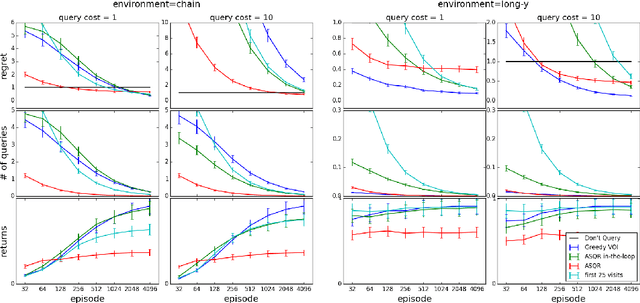
Agent-Agnostic Human-in-the-Loop Reinforcement Learning
Jan 15, 2017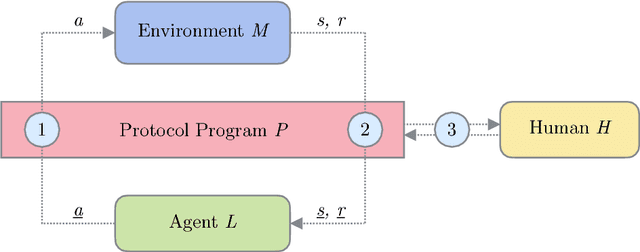


Providing Reinforcement Learning agents with expert advice can dramatically improve various aspects of learning. Prior work has developed teaching protocols that enable agents to learn efficiently in complex environments; many of these methods tailor the teacher's guidance to agents with a particular representation or underlying learning scheme, offering effective but specialized teaching procedures. In this work, we explore protocol programs, an agent-agnostic schema for Human-in-the-Loop Reinforcement Learning. Our goal is to incorporate the beneficial properties of a human teacher into Reinforcement Learning without making strong assumptions about the inner workings of the agent. We show how to represent existing approaches such as action pruning, reward shaping, and training in simulation as special cases of our schema and conduct preliminary experiments on simple domains.
Theano: A Python framework for fast computation of mathematical expressions
May 09, 2016
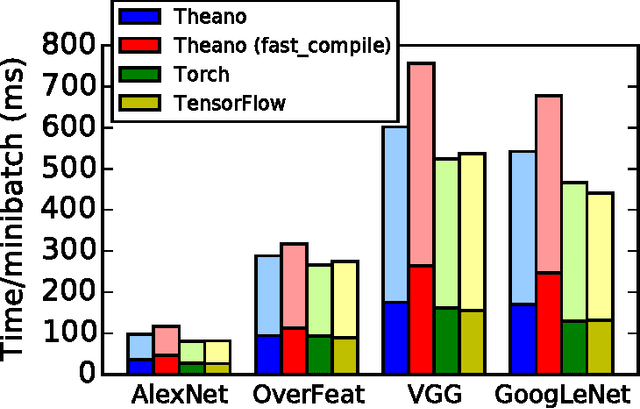
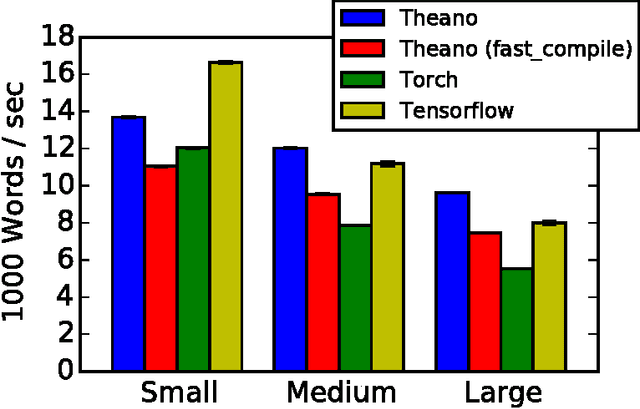
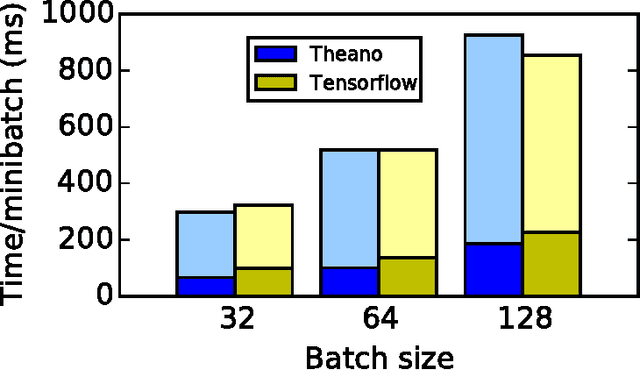
Theano is a Python library that allows to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently. Since its introduction, it has been one of the most used CPU and GPU mathematical compilers - especially in the machine learning community - and has shown steady performance improvements. Theano is being actively and continuously developed since 2008, multiple frameworks have been built on top of it and it has been used to produce many state-of-the-art machine learning models. The present article is structured as follows. Section I provides an overview of the Theano software and its community. Section II presents the principal features of Theano and how to use them, and compares them with other similar projects. Section III focuses on recently-introduced functionalities and improvements. Section IV compares the performance of Theano against Torch7 and TensorFlow on several machine learning models. Section V discusses current limitations of Theano and potential ways of improving it.