Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Reinforcement Learning: Observing Rewards at a Cost
Paper and Code
Nov 24, 2020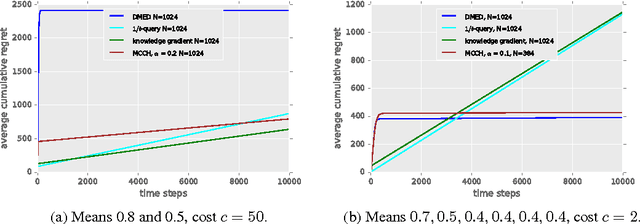

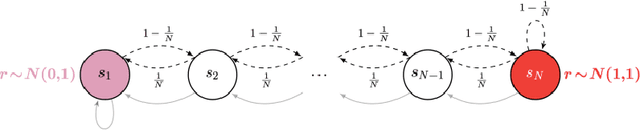
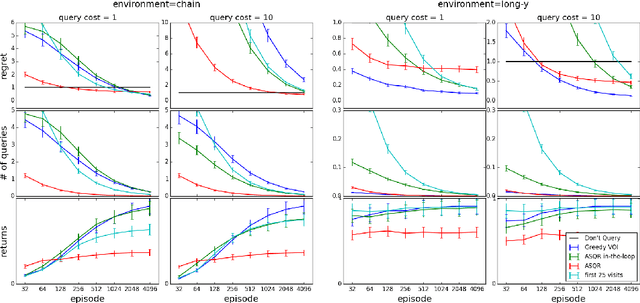
Active reinforcement learning (ARL) is a variant on reinforcement learning where the agent does not observe the reward unless it chooses to pay a query cost c > 0. The central question of ARL is how to quantify the long-term value of reward information. Even in multi-armed bandits, computing the value of this information is intractable and we have to rely on heuristics. We propose and evaluate several heuristic approaches for ARL in multi-armed bandits and (tabular) Markov decision processes, and discuss and illustrate some challenging aspects of the ARL problem.
* Originally appeared at the NeurIPS 2016 "Future of Interactive
Learning Machines (FILM)" workshop
View paper on