 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXGLUE: A New Benchmark Dataset for Cross-lingual Pre-training, Understanding and Generation
Apr 19, 2020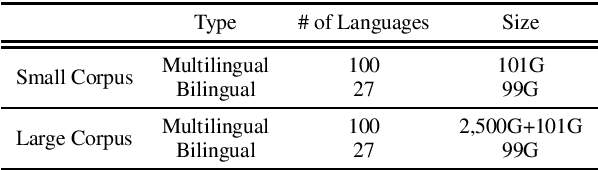
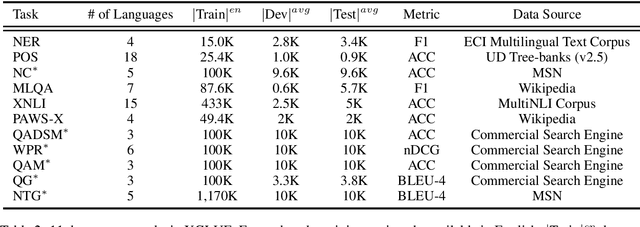
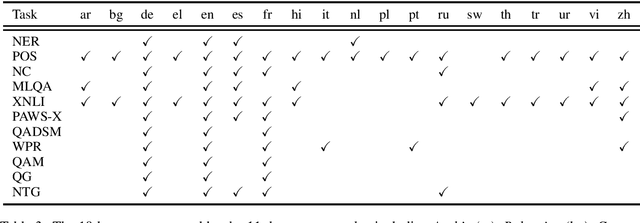
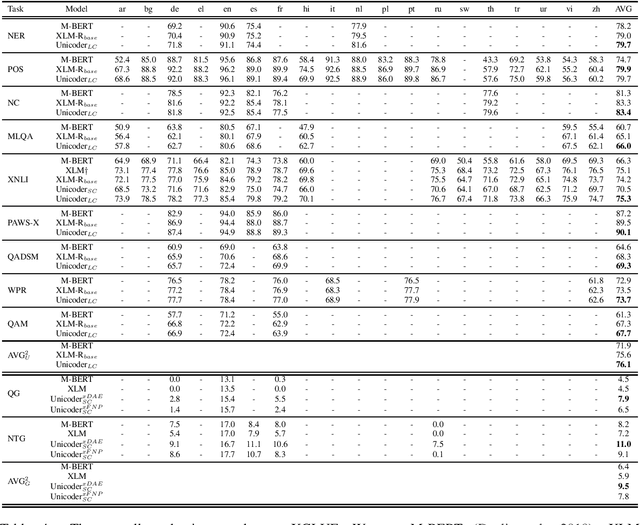
In this paper, we introduce XGLUE, a new benchmark dataset to train large-scale cross-lingual pre-trained models using multilingual and bilingual corpora, and evaluate their performance across a diverse set of cross-lingual tasks. Comparing to GLUE (Wang et al.,2019), which is labeled in English and includes natural language understanding tasks only, XGLUE has three main advantages: (1) it provides two corpora with different sizes for cross-lingual pre-training; (2) it provides 11 diversified tasks that cover both natural language understanding and generation scenarios; (3) for each task, it provides labeled data in multiple languages. We extend a recent cross-lingual pre-trained model Unicoder (Huang et al., 2019) to cover both understanding and generation tasks, which is evaluated on XGLUE as a strong baseline. We also evaluate the base versions (12-layer) of Multilingual BERT, XLM and XLM-R for comparison.
Fast and Accurate Knowledge-Aware Document Representation Enhancement for News Recommendations
Oct 25, 2019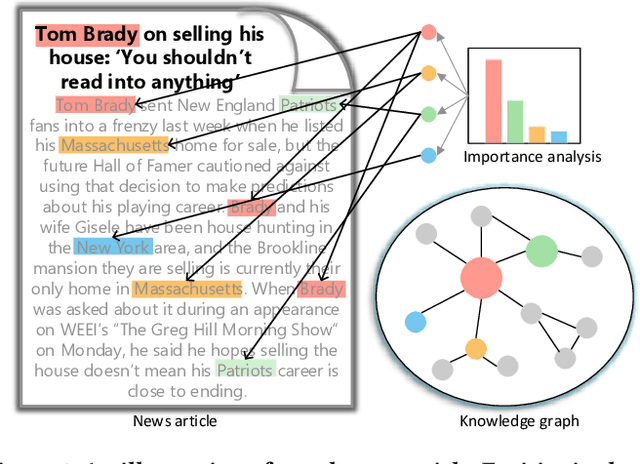



Knowledge graph contains well-structured external information and has shown to be useful for recommender systems. Most existing knowledge-aware methods assume that the item from recommender systems can be linked to an entity in a knowledge graph, thus item embeddings can be better learned by jointly modeling of both recommender systems and a knowledge graph. However, this is not the situation for news recommendation, where items, namely news articles, are in fact related to a collection of knowledge entities. The importance score and semantic information of entities in one article differ from each other, which depend on the topic of the article and relations among co-occurred entities. How to fully utilize these entities for better news recommendation service is non-trivial. In this paper, we propose a fast and effective knowledge-aware representation enhancement model for improving news document understanding. The model, named \emph{KRED}, consists of three layers: (1) an entity representation layer; (2) a context embedding layer; and (3) an information distillation layer. An entity is represented by the embeddings of itself and its surrounding entities. The context embedding layer is designed to distinguish dynamic context of different entities such as frequency, category and position. The information distillation layer will aggregate the entity embeddings under the guidance of the original document vector, transforming the document vector into a new one. We have conduct extensive experiments on a real-world news reading dataset. The results demonstrate that our proposed model greatly benefits a variety of news recommendation tasks, including personalized news recommendation, article category classification, article popularity prediction and local news detection.