 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Exact Editing of Flow-Based Diffusion Models
Dec 30, 2025Recent methods in flow-based diffusion editing have enabled direct transformations between source and target image distribution without explicit inversion. However, the latent trajectories in these methods often exhibit accumulated velocity errors, leading to semantic inconsistency and loss of structural fidelity. We propose Conditioned Velocity Correction (CVC), a principled framework that reformulates flow-based editing as a distribution transformation problem driven by a known source prior. CVC rethinks the role of velocity in inter-distribution transformation by introducing a dual-perspective velocity conversion mechanism. This mechanism explicitly decomposes the latent evolution into two components: a structure-preserving branch that remains consistent with the source trajectory, and a semantically-guided branch that drives a controlled deviation toward the target distribution. The conditional velocity field exhibits an absolute velocity error relative to the true underlying distribution trajectory, which inherently introduces potential instability and trajectory drift in the latent space. To address this quantifiable deviation and maintain fidelity to the true flow, we apply a posterior-consistent update to the resulting conditional velocity field. This update is derived from Empirical Bayes Inference and Tweedie correction, which ensures a mathematically grounded error compensation over time. Our method yields stable and interpretable latent dynamics, achieving faithful reconstruction alongside smooth local semantic conversion. Comprehensive experiments demonstrate that CVC consistently achieves superior fidelity, better semantic alignment, and more reliable editing behavior across diverse tasks.
CharaConsist: Fine-Grained Consistent Character Generation
Jul 15, 2025

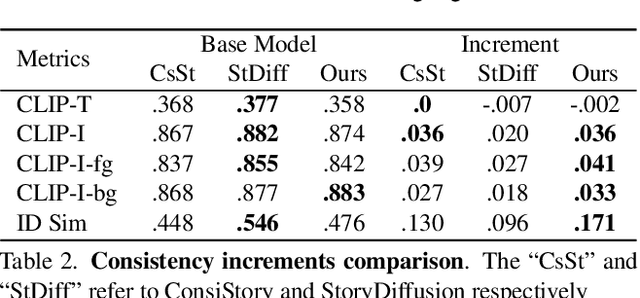

In text-to-image generation, producing a series of consistent contents that preserve the same identity is highly valuable for real-world applications. Although a few works have explored training-free methods to enhance the consistency of generated subjects, we observe that they suffer from the following problems. First, they fail to maintain consistent background details, which limits their applicability. Furthermore, when the foreground character undergoes large motion variations, inconsistencies in identity and clothing details become evident. To address these problems, we propose CharaConsist, which employs point-tracking attention and adaptive token merge along with decoupled control of the foreground and background. CharaConsist enables fine-grained consistency for both foreground and background, supporting the generation of one character in continuous shots within a fixed scene or in discrete shots across different scenes. Moreover, CharaConsist is the first consistent generation method tailored for text-to-image DiT model. Its ability to maintain fine-grained consistency, combined with the larger capacity of latest base model, enables it to produce high-quality visual outputs, broadening its applicability to a wider range of real-world scenarios. The source code has been released at https://github.com/Murray-Wang/CharaConsist
DCEdit: Dual-Level Controlled Image Editing via Precisely Localized Semantics
Mar 21, 2025This paper presents a novel approach to improving text-guided image editing using diffusion-based models. Text-guided image editing task poses key challenge of precisly locate and edit the target semantic, and previous methods fall shorts in this aspect. Our method introduces a Precise Semantic Localization strategy that leverages visual and textual self-attention to enhance the cross-attention map, which can serve as a regional cues to improve editing performance. Then we propose a Dual-Level Control mechanism for incorporating regional cues at both feature and latent levels, offering fine-grained control for more precise edits. To fully compare our methods with other DiT-based approaches, we construct the RW-800 benchmark, featuring high resolution images, long descriptive texts, real-world images, and a new text editing task. Experimental results on the popular PIE-Bench and RW-800 benchmarks demonstrate the superior performance of our approach in preserving background and providing accurate edits.