 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgiBot World Colosseo: A Large-scale Manipulation Platform for Scalable and Intelligent Embodied Systems
Mar 09, 2025We explore how scalable robot data can address real-world challenges for generalized robotic manipulation. Introducing AgiBot World, a large-scale platform comprising over 1 million trajectories across 217 tasks in five deployment scenarios, we achieve an order-of-magnitude increase in data scale compared to existing datasets. Accelerated by a standardized collection pipeline with human-in-the-loop verification, AgiBot World guarantees high-quality and diverse data distribution. It is extensible from grippers to dexterous hands and visuo-tactile sensors for fine-grained skill acquisition. Building on top of data, we introduce Genie Operator-1 (GO-1), a novel generalist policy that leverages latent action representations to maximize data utilization, demonstrating predictable performance scaling with increased data volume. Policies pre-trained on our dataset achieve an average performance improvement of 30% over those trained on Open X-Embodiment, both in in-domain and out-of-distribution scenarios. GO-1 exhibits exceptional capability in real-world dexterous and long-horizon tasks, achieving over 60% success rate on complex tasks and outperforming prior RDT approach by 32%. By open-sourcing the dataset, tools, and models, we aim to democratize access to large-scale, high-quality robot data, advancing the pursuit of scalable and general-purpose intelligence.
Transsion TSUP's speech recognition system for ASRU 2023 MADASR Challenge
Jul 20, 2023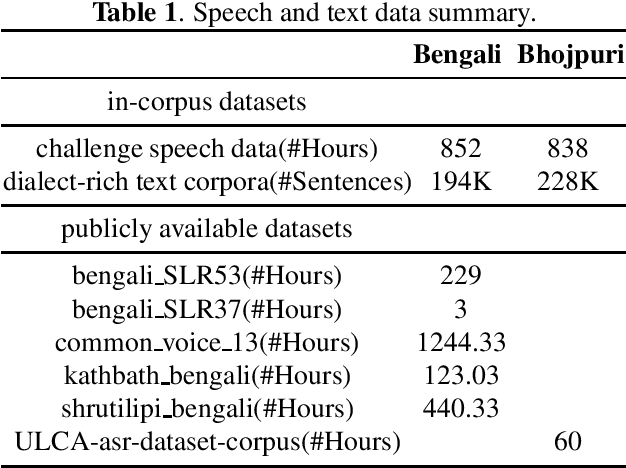

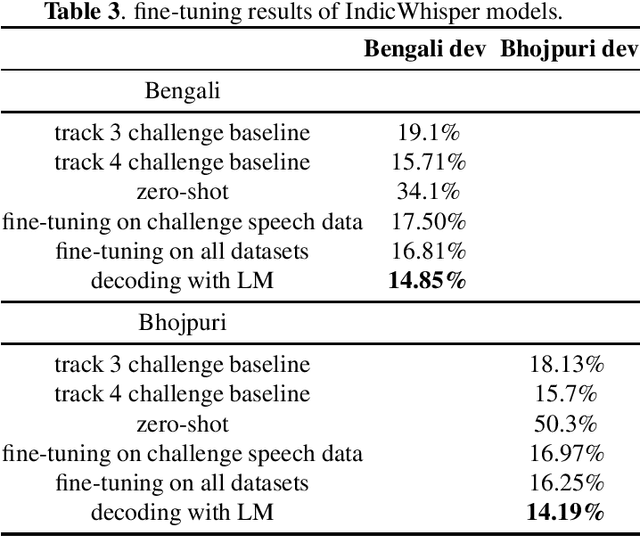
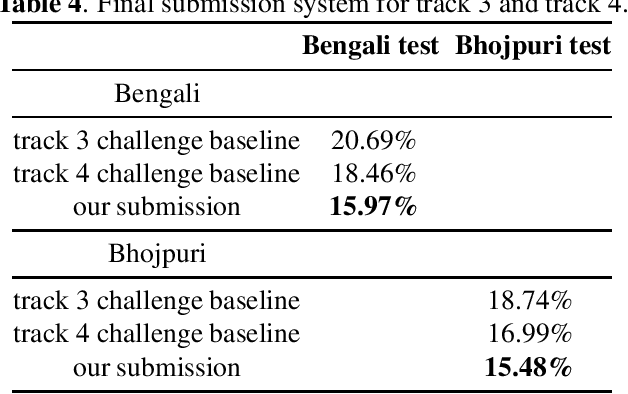
This paper presents a speech recognition system developed by the Transsion Speech Understanding Processing Team (TSUP) for the ASRU 2023 MADASR Challenge. The system focuses on adapting ASR models for low-resource Indian languages and covers all four tracks of the challenge. For tracks 1 and 2, the acoustic model utilized a squeezeformer encoder and bidirectional transformer decoder with joint CTC-Attention training loss. Additionally, an external KenLM language model was used during TLG beam search decoding. For tracks 3 and 4, pretrained IndicWhisper models were employed and finetuned on both the challenge dataset and publicly available datasets. The whisper beam search decoding was also modified to support an external KenLM language model, which enabled better utilization of the additional text provided by the challenge. The proposed method achieved word error rates (WER) of 24.17%, 24.43%, 15.97%, and 15.97% for Bengali language in the four tracks, and WER of 19.61%, 19.54%, 15.48%, and 15.48% for Bhojpuri language in the four tracks. These results demonstrate the effectiveness of the proposed method.
A Simple Temporal Information Matching Mechanism for Entity Alignment Between Temporal Knowledge Graphs
Sep 20, 2022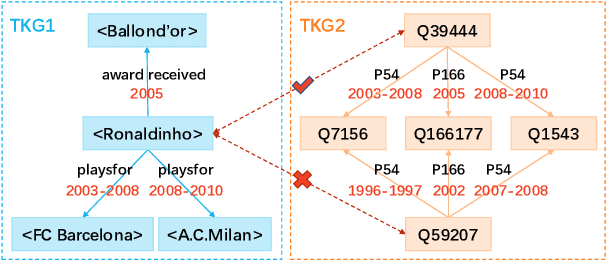

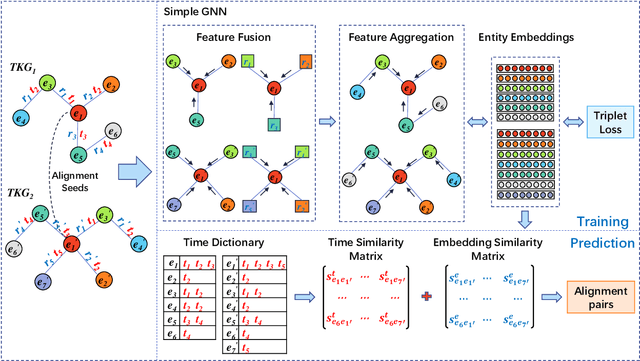
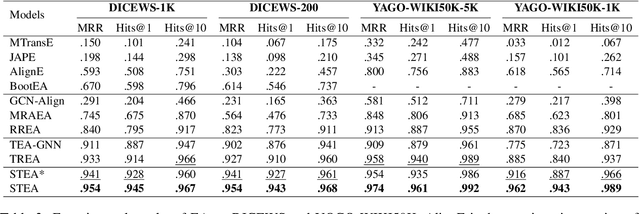
Entity alignment (EA) aims to find entities in different knowledge graphs (KGs) that refer to the same object in the real world. Recent studies incorporate temporal information to augment the representations of KGs. The existing methods for EA between temporal KGs (TKGs) utilize a time-aware attention mechanism to incorporate relational and temporal information into entity embeddings. The approaches outperform the previous methods by using temporal information. However, we believe that it is not necessary to learn the embeddings of temporal information in KGs since most TKGs have uniform temporal representations. Therefore, we propose a simple graph neural network (GNN) model combined with a temporal information matching mechanism, which achieves better performance with less time and fewer parameters. Furthermore, since alignment seeds are difficult to label in real-world applications, we also propose a method to generate unsupervised alignment seeds via the temporal information of TKG. Extensive experiments on public datasets indicate that our supervised method significantly outperforms the previous methods and the unsupervised one has competitive performance.
A Dual-Attention Neural Network for Pun Location and Using Pun-Gloss Pairs for Interpretation
Oct 14, 2021

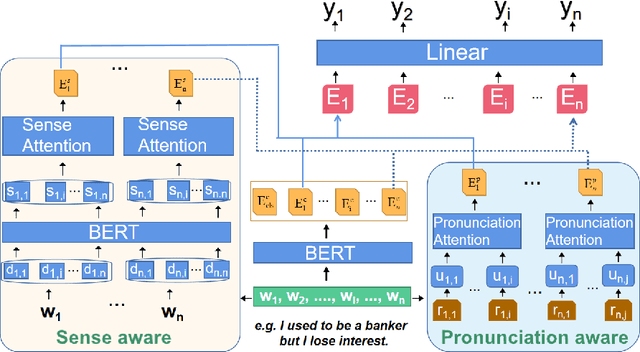
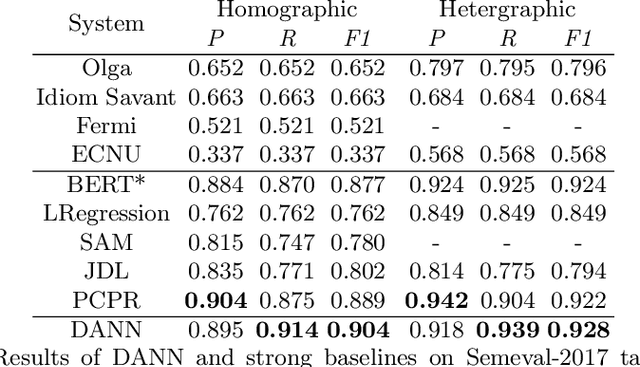
Pun location is to identify the punning word (usually a word or a phrase that makes the text ambiguous) in a given short text, and pun interpretation is to find out two different meanings of the punning word. Most previous studies adopt limited word senses obtained by WSD(Word Sense Disambiguation) technique or pronunciation information in isolation to address pun location. For the task of pun interpretation, related work pays attention to various WSD algorithms. In this paper, a model called DANN (Dual-Attentive Neural Network) is proposed for pun location, effectively integrates word senses and pronunciation with context information to address two kinds of pun at the same time. Furthermore, we treat pun interpretation as a classification task and construct pungloss pairs as processing data to solve this task. Experiments on the two benchmark datasets show that our proposed methods achieve new state-of-the-art results. Our source code is available in the public code repository.