 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranssion TSUP's speech recognition system for ASRU 2023 MADASR Challenge
Jul 20, 2023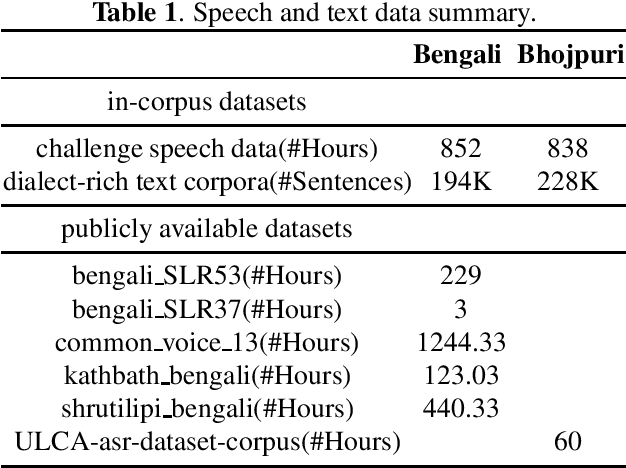

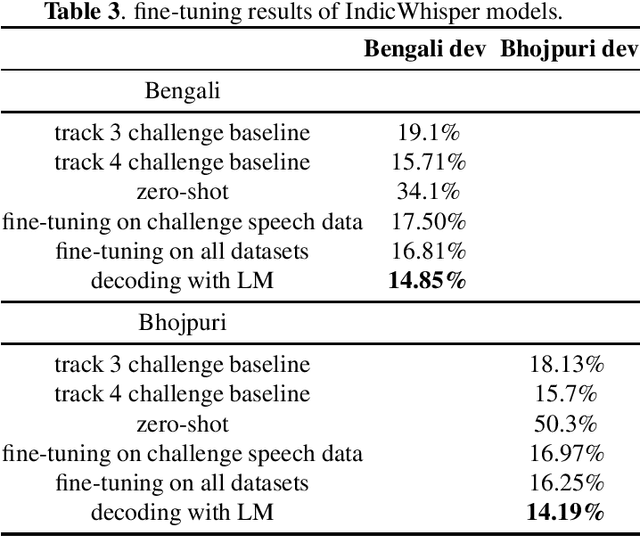
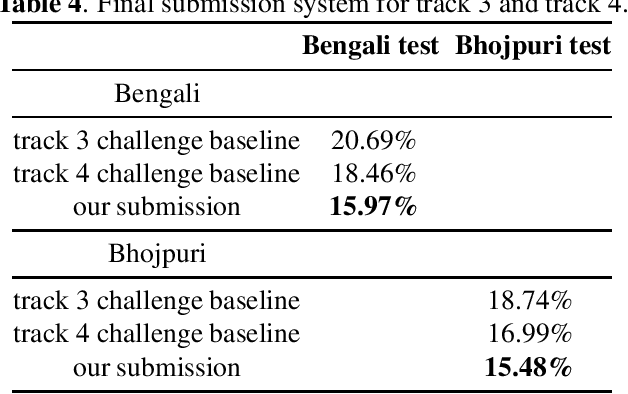
This paper presents a speech recognition system developed by the Transsion Speech Understanding Processing Team (TSUP) for the ASRU 2023 MADASR Challenge. The system focuses on adapting ASR models for low-resource Indian languages and covers all four tracks of the challenge. For tracks 1 and 2, the acoustic model utilized a squeezeformer encoder and bidirectional transformer decoder with joint CTC-Attention training loss. Additionally, an external KenLM language model was used during TLG beam search decoding. For tracks 3 and 4, pretrained IndicWhisper models were employed and finetuned on both the challenge dataset and publicly available datasets. The whisper beam search decoding was also modified to support an external KenLM language model, which enabled better utilization of the additional text provided by the challenge. The proposed method achieved word error rates (WER) of 24.17%, 24.43%, 15.97%, and 15.97% for Bengali language in the four tracks, and WER of 19.61%, 19.54%, 15.48%, and 15.48% for Bhojpuri language in the four tracks. These results demonstrate the effectiveness of the proposed method.