 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerfCam: Digital Twinning for Production Lines Using 3D Gaussian Splatting and Vision Models
Apr 25, 2025We introduce PerfCam, an open source Proof-of-Concept (PoC) digital twinning framework that combines camera and sensory data with 3D Gaussian Splatting and computer vision models for digital twinning, object tracking, and Key Performance Indicators (KPIs) extraction in industrial production lines. By utilizing 3D reconstruction and Convolutional Neural Networks (CNNs), PerfCam offers a semi-automated approach to object tracking and spatial mapping, enabling digital twins that capture real-time KPIs such as availability, performance, Overall Equipment Effectiveness (OEE), and rate of conveyor belts in the production line. We validate the effectiveness of PerfCam through a practical deployment within realistic test production lines in the pharmaceutical industry and contribute an openly published dataset to support further research and development in the field. The results demonstrate PerfCam's ability to deliver actionable insights through its precise digital twin capabilities, underscoring its value as an effective tool for developing usable digital twins in smart manufacturing environments and extracting operational analytics.
A GPU-Accelerated Bi-linear ADMM Algorithm for Distributed Sparse Machine Learning
May 25, 2024This paper introduces the Bi-linear consensus Alternating Direction Method of Multipliers (Bi-cADMM), aimed at solving large-scale regularized Sparse Machine Learning (SML) problems defined over a network of computational nodes. Mathematically, these are stated as minimization problems with convex local loss functions over a global decision vector, subject to an explicit $\ell_0$ norm constraint to enforce the desired sparsity. The considered SML problem generalizes different sparse regression and classification models, such as sparse linear and logistic regression, sparse softmax regression, and sparse support vector machines. Bi-cADMM leverages a bi-linear consensus reformulation of the original non-convex SML problem and a hierarchical decomposition strategy that divides the problem into smaller sub-problems amenable to parallel computing. In Bi-cADMM, this decomposition strategy is based on a two-phase approach. Initially, it performs a sample decomposition of the data and distributes local datasets across computational nodes. Subsequently, a delayed feature decomposition of the data is conducted on Graphics Processing Units (GPUs) available to each node. This methodology allows Bi-cADMM to undertake computationally intensive data-centric computations on GPUs, while CPUs handle more cost-effective computations. The proposed algorithm is implemented within an open-source Python package called Parallel Sparse Fitting Toolbox (PsFiT), which is publicly available. Finally, computational experiments demonstrate the efficiency and scalability of our algorithm through numerical benchmarks across various SML problems featuring distributed datasets.
A cutting plane algorithm for globally solving low dimensional k-means clustering problems
Feb 21, 2024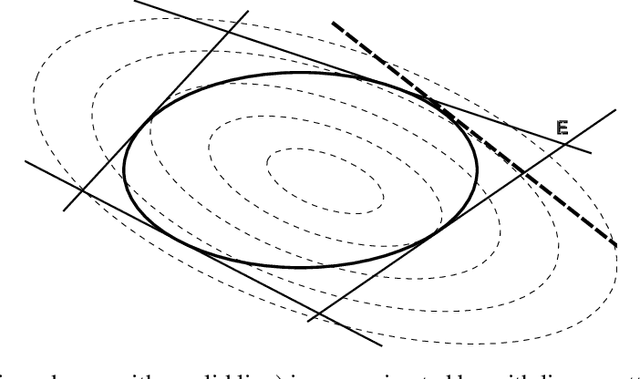
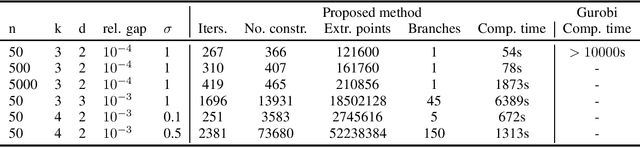
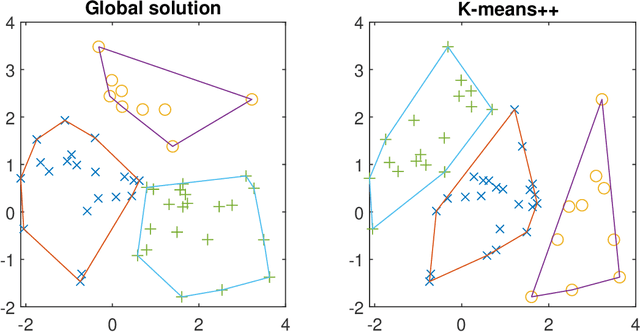
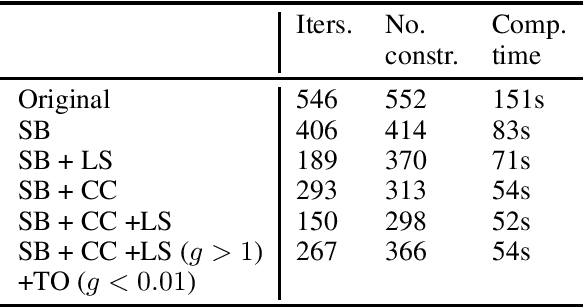
Clustering is one of the most fundamental tools in data science and machine learning, and k-means clustering is one of the most common such methods. There is a variety of approximate algorithms for the k-means problem, but computing the globally optimal solution is in general NP-hard. In this paper we consider the k-means problem for instances with low dimensional data and formulate it as a structured concave assignment problem. This allows us to exploit the low dimensional structure and solve the problem to global optimality within reasonable time for large data sets with several clusters. The method builds on iteratively solving a small concave problem and a large linear programming problem. This gives a sequence of feasible solutions along with bounds which we show converges to zero optimality gap. The paper combines methods from global optimization theory to accelerate the procedure, and we provide numerical results on their performance.
Globally solving the Gromov-Wasserstein problem for point clouds in low dimensional Euclidean spaces
Jul 18, 2023This paper presents a framework for computing the Gromov-Wasserstein problem between two sets of points in low dimensional spaces, where the discrepancy is the squared Euclidean norm. The Gromov-Wasserstein problem is a generalization of the optimal transport problem that finds the assignment between two sets preserving pairwise distances as much as possible. This can be used to quantify the similarity between two formations or shapes, a common problem in AI and machine learning. The problem can be formulated as a Quadratic Assignment Problem (QAP), which is in general computationally intractable even for small problems. Our framework addresses this challenge by reformulating the QAP as an optimization problem with a low-dimensional domain, leveraging the fact that the problem can be expressed as a concave quadratic optimization problem with low rank. The method scales well with the number of points, and it can be used to find the global solution for large-scale problems with thousands of points. We compare the computational complexity of our approach with state-of-the-art methods on synthetic problems and apply it to a near-symmetrical problem which is of particular interest in computational biology.
Model-based feature selection for neural networks: A mixed-integer programming approach
Feb 20, 2023In this work, we develop a novel input feature selection framework for ReLU-based deep neural networks (DNNs), which builds upon a mixed-integer optimization approach. While the method is generally applicable to various classification tasks, we focus on finding input features for image classification for clarity of presentation. The idea is to use a trained DNN, or an ensemble of trained DNNs, to identify the salient input features. The input feature selection is formulated as a sequence of mixed-integer linear programming (MILP) problems that find sets of sparse inputs that maximize the classification confidence of each category. These ''inverse'' problems are regularized by the number of inputs selected for each category and by distribution constraints. Numerical results on the well-known MNIST and FashionMNIST datasets show that the proposed input feature selection allows us to drastically reduce the size of the input to $\sim$15\% while maintaining a good classification accuracy. This allows us to design DNNs with significantly fewer connections, reducing computational effort and producing DNNs that are more robust towards adversarial attacks.
P-split formulations: A class of intermediate formulations between big-M and convex hull for disjunctive constraints
Feb 10, 2022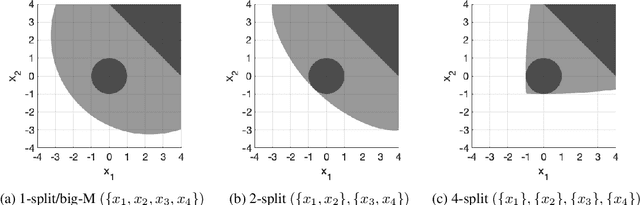
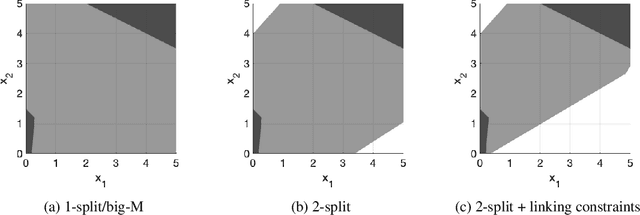
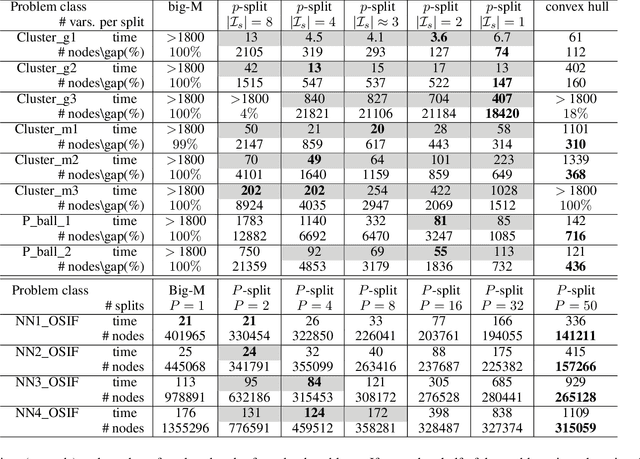
We develop a class of mixed-integer formulations for disjunctive constraints intermediate to the big-M and convex hull formulations in terms of relaxation strength. The main idea is to capture the best of both the big-M and convex hull formulations: a computationally light formulation with a tight relaxation. The "$P$-split" formulations are based on a lifted transformation that splits convex additively separable constraints into $P$ partitions and forms the convex hull of the linearized and partitioned disjunction. We analyze the continuous relaxation of the $P$-split formulations and show that, under certain assumptions, the formulations form a hierarchy starting from a big-M equivalent and converging to the convex hull. The goal of the $P$-split formulations is to form a strong approximation of the convex hull through a computationally simpler formulation. We computationally compare the $P$-split formulations against big-M and convex hull formulations on 320 test instances. The test problems include K-means clustering, P_ball problems, and optimization over trained ReLU neural networks. The computational results show promising potential of the $P$-split formulations. For many of the test problems, $P$-split formulations are solved with a similar number of explored nodes as the convex hull formulation, while reducing the solution time by an order of magnitude and outperforming big-M both in time and number of explored nodes.
Maximizing information from chemical engineering data sets: Applications to machine learning
Jan 25, 2022
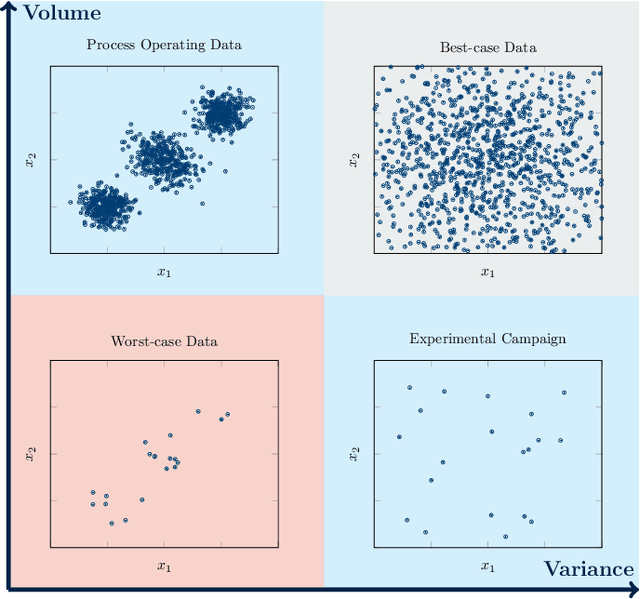
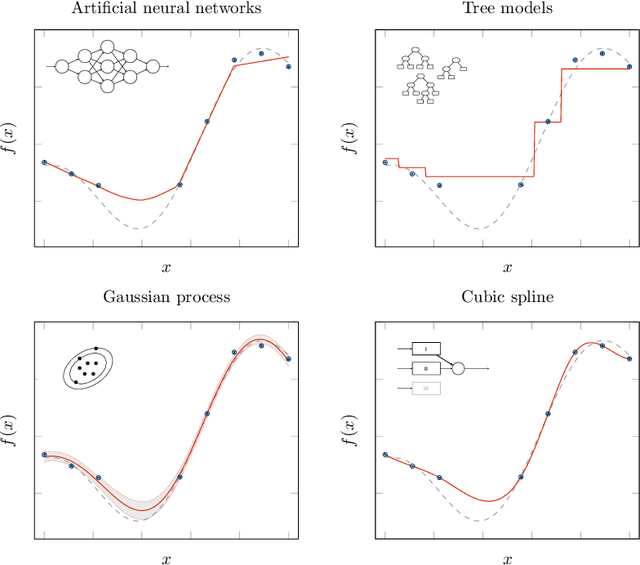
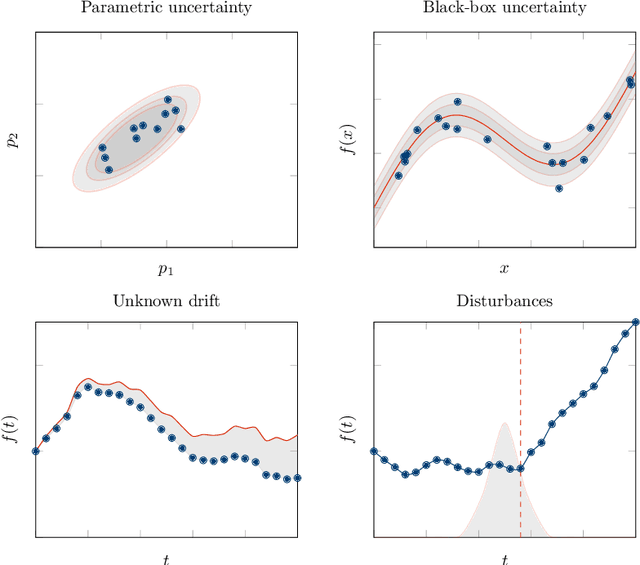
It is well-documented how artificial intelligence can have (and already is having) a big impact on chemical engineering. But classical machine learning approaches may be weak for many chemical engineering applications. This review discusses how challenging data characteristics arise in chemical engineering applications. We identify four characteristics of data arising in chemical engineering applications that make applying classical artificial intelligence approaches difficult: (1) high variance, low volume data, (2) low variance, high volume data, (3) noisy/corrupt/missing data, and (4) restricted data with physics-based limitations. For each of these four data characteristics, we discuss applications where these data characteristics arise and show how current chemical engineering research is extending the fields of data science and machine learning to incorporate these challenges. Finally, we identify several challenges for future research.
Partition-based formulations for mixed-integer optimization of trained ReLU neural networks
Feb 08, 2021

This paper introduces a class of mixed-integer formulations for trained ReLU neural networks. The approach balances model size and tightness by partitioning node inputs into a number of groups and forming the convex hull over the partitions via disjunctive programming. At one extreme, one partition per input recovers the convex hull of a node, i.e., the tightest possible formulation for each node. For fewer partitions, we develop smaller relaxations that approximate the convex hull, and show that they outperform existing formulations. Specifically, we propose strategies for partitioning variables based on theoretical motivations and validate these strategies using extensive computational experiments. Furthermore, the proposed scheme complements known algorithmic approaches, e.g., optimization-based bound tightening captures dependencies within a partition.
Between steps: Intermediate relaxations between big-M and convex hull formulations
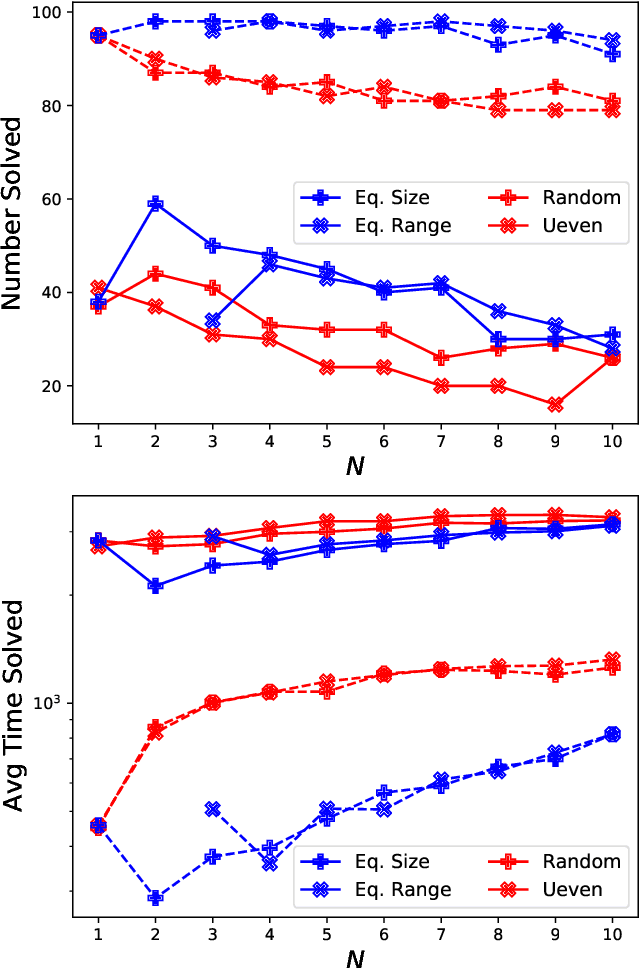
Jan 29, 2021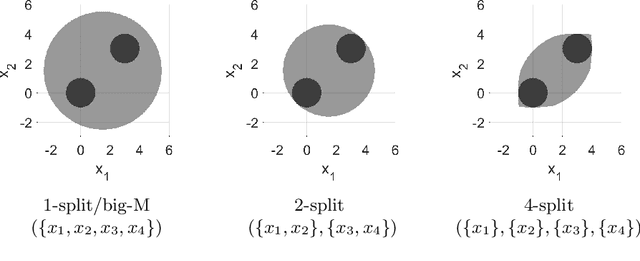
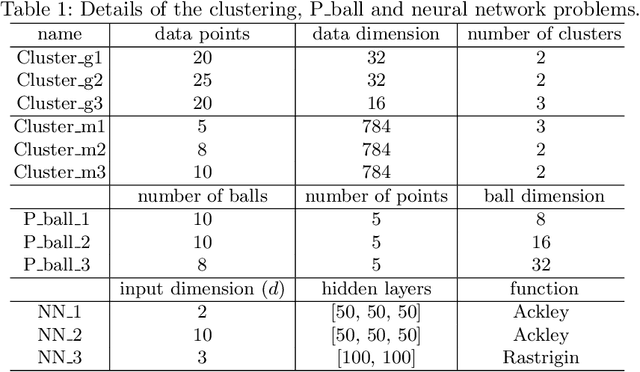
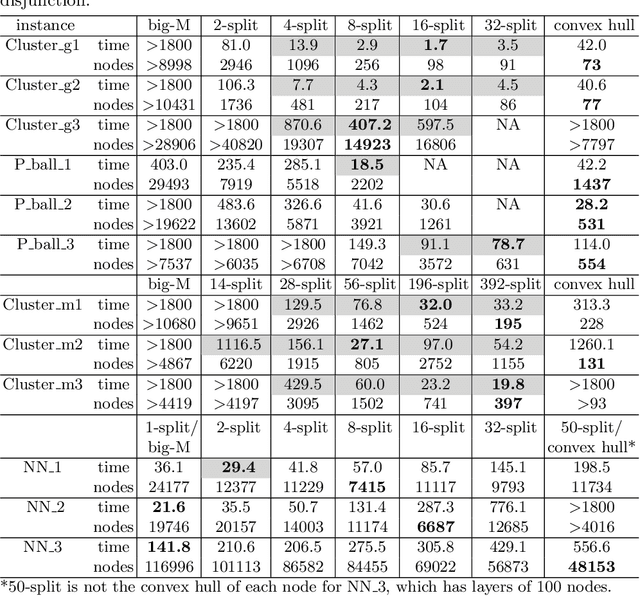
This work develops a class of relaxations in between the big-M and convex hull formulations of disjunctions, drawing advantages from both. The proposed "P-split" formulations split convex additively separable constraints into P partitions and form the convex hull of the partitioned disjuncts. Parameter P represents the trade-off of model size vs. relaxation strength. We examine the novel formulations and prove that, under certain assumptions, the relaxations form a hierarchy starting from a big-M equivalent and converging to the convex hull. We computationally compare the proposed formulations to big-M and convex hull formulations on a test set including: K-means clustering, P_ball problems, and ReLU neural networks. The computational results show that the intermediate P-split formulations can form strong outer approximations of the convex hull with fewer variables and constraints than the extended convex hull formulations, giving significant computational advantages over both the big-M and convex hull.
ENTMOOT: A Framework for Optimization over Ensemble Tree Models
Mar 10, 2020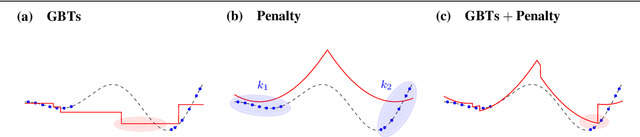
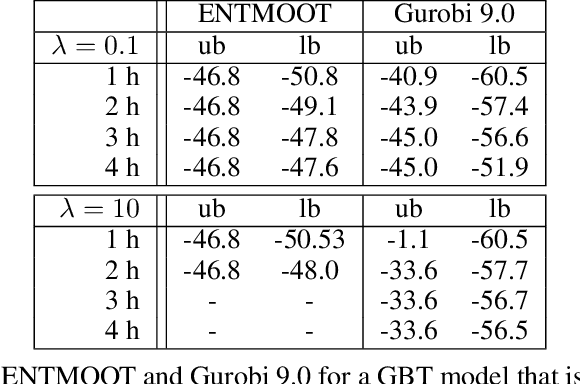


Gradient boosted trees and other regression tree models perform well in a wide range of real-world, industrial applications. These tree models (i) offer insight into important prediction features, (ii) effectively manage sparse data, and (iii) have excellent prediction capabilities. Despite their advantages, they are generally unpopular for decision-making tasks and black-box optimization, which is due to their difficult-to-optimize structure and the lack of a reliable uncertainty measure. ENTMOOT is our new framework for integrating (already trained) tree models into larger optimization problems. The contributions of ENTMOOT include: (i) explicitly introducing a reliable uncertainty measure that is compatible with tree models, (ii) solving the larger optimization problems that incorporate these uncertainty aware tree models, (iii) proving that the solutions are globally optimal, i.e. no better solution exists. In particular, we show how the ENTMOOT approach allows a simple integration of tree models into decision-making and black-box optimization, where it proves as a strong competitor to commonly-used frameworks.