 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTree ensemble kernels for Bayesian optimization with known constraints over mixed-feature spaces
Jul 02, 2022
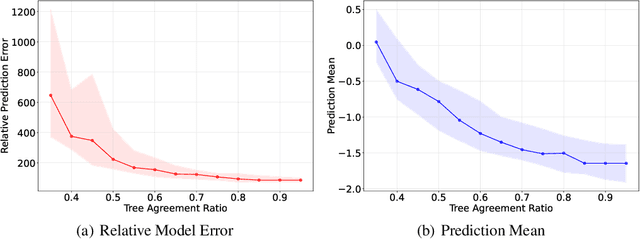
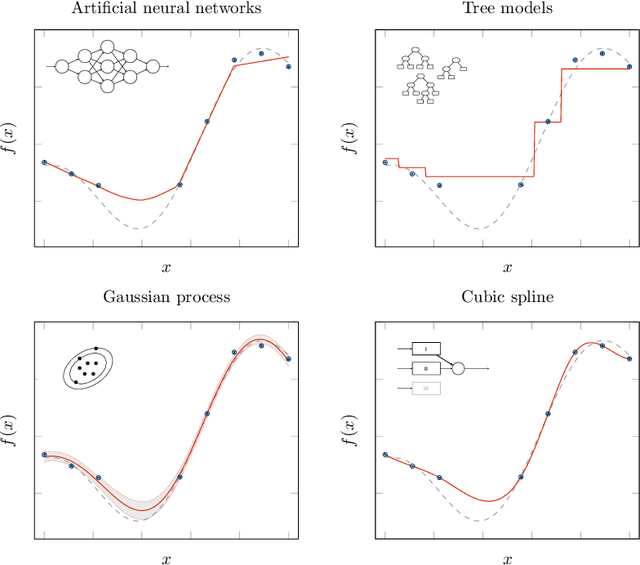
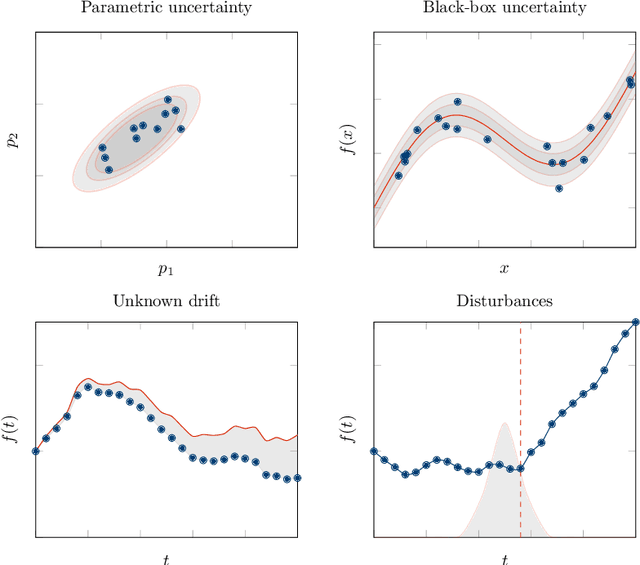
Tree ensembles can be well-suited for black-box optimization tasks such as algorithm tuning and neural architecture search, as they achieve good predictive performance with little to no manual tuning, naturally handle discrete feature spaces, and are relatively insensitive to outliers in the training data. Two well-known challenges in using tree ensembles for black-box optimization are (i) effectively quantifying model uncertainty for exploration and (ii) optimizing over the piece-wise constant acquisition function. To address both points simultaneously, we propose using the kernel interpretation of tree ensembles as a Gaussian Process prior to obtain model variance estimates, and we develop a compatible optimization formulation for the acquisition function. The latter further allows us to seamlessly integrate known constraints to improve sampling efficiency by considering domain-knowledge in engineering settings and modeling search space symmetries, e.g., hierarchical relationships in neural architecture search. Our framework performs as well as state-of-the-art methods for unconstrained black-box optimization over continuous/discrete features and outperforms competing methods for problems combining mixed-variable feature spaces and known input constraints.
OMLT: Optimization & Machine Learning Toolkit
Feb 04, 2022
The optimization and machine learning toolkit (OMLT) is an open-source software package incorporating neural network and gradient-boosted tree surrogate models, which have been trained using machine learning, into larger optimization problems. We discuss the advances in optimization technology that made OMLT possible and show how OMLT seamlessly integrates with the algebraic modeling language Pyomo. We demonstrate how to use OMLT for solving decision-making problems in both computer science and engineering.
Maximizing information from chemical engineering data sets: Applications to machine learning
Jan 25, 2022
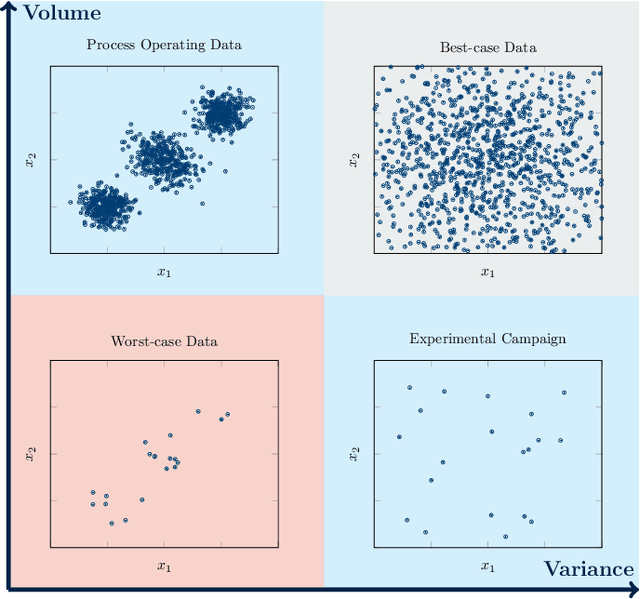
It is well-documented how artificial intelligence can have (and already is having) a big impact on chemical engineering. But classical machine learning approaches may be weak for many chemical engineering applications. This review discusses how challenging data characteristics arise in chemical engineering applications. We identify four characteristics of data arising in chemical engineering applications that make applying classical artificial intelligence approaches difficult: (1) high variance, low volume data, (2) low variance, high volume data, (3) noisy/corrupt/missing data, and (4) restricted data with physics-based limitations. For each of these four data characteristics, we discuss applications where these data characteristics arise and show how current chemical engineering research is extending the fields of data science and machine learning to incorporate these challenges. Finally, we identify several challenges for future research.
Multi-Objective Constrained Optimization for Energy Applications via Tree Ensembles
Nov 04, 2021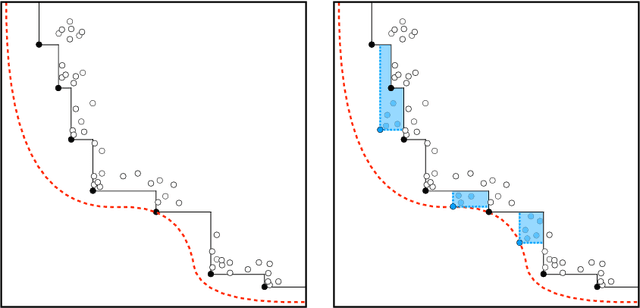

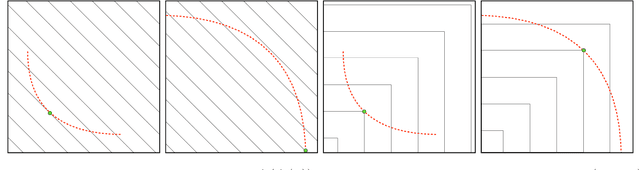

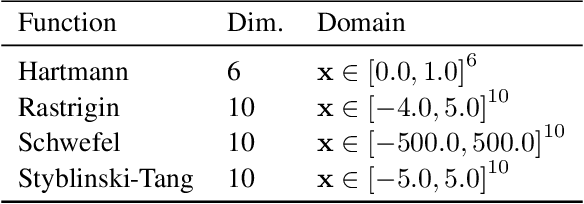
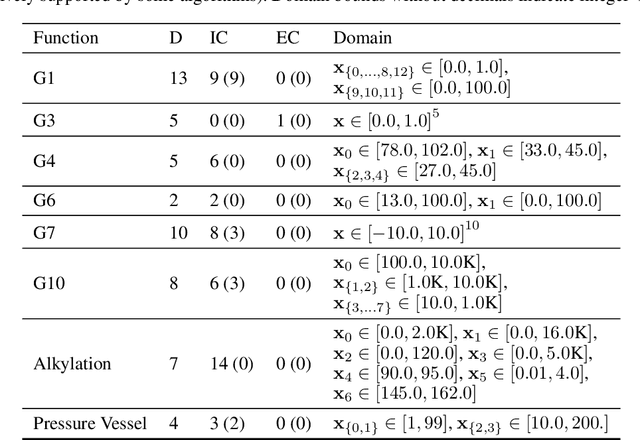
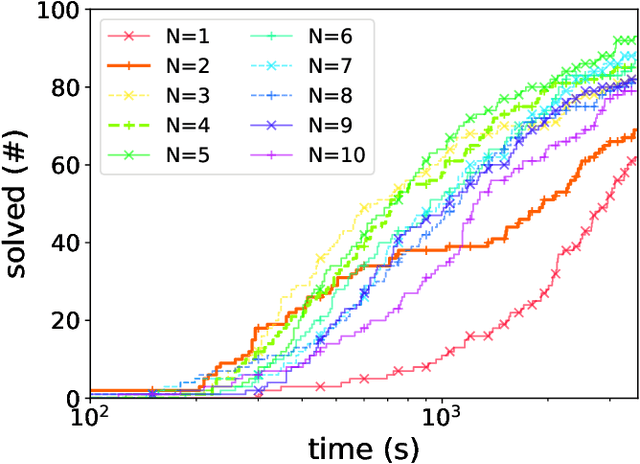
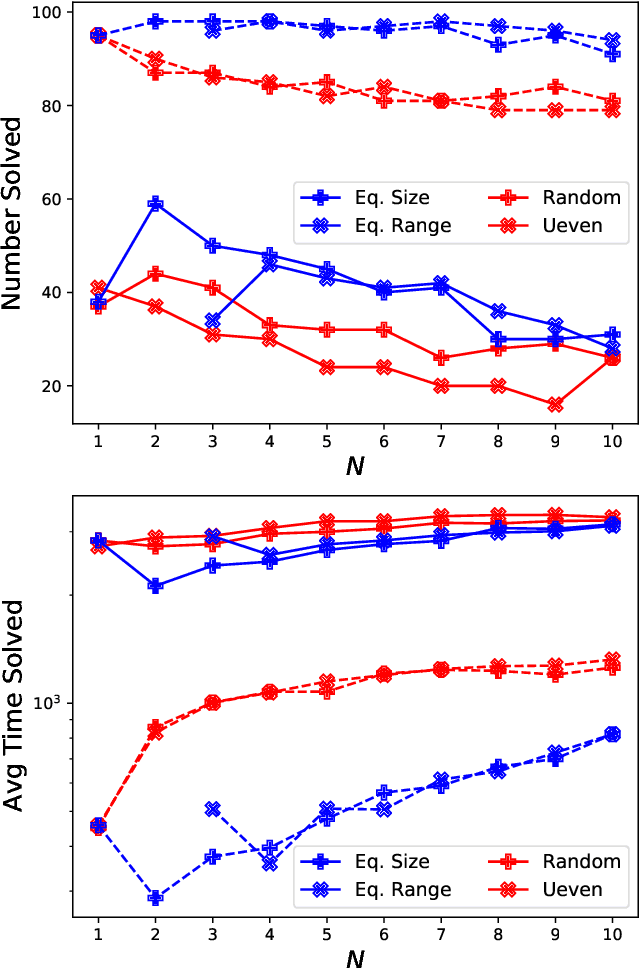
Energy systems optimization problems are complex due to strongly non-linear system behavior and multiple competing objectives, e.g. economic gain vs. environmental impact. Moreover, a large number of input variables and different variable types, e.g. continuous and categorical, are challenges commonly present in real-world applications. In some cases, proposed optimal solutions need to obey explicit input constraints related to physical properties or safety-critical operating conditions. This paper proposes a novel data-driven strategy using tree ensembles for constrained multi-objective optimization of black-box problems with heterogeneous variable spaces for which underlying system dynamics are either too complex to model or unknown. In an extensive case study comprised of synthetic benchmarks and relevant energy applications we demonstrate the competitive performance and sampling efficiency of the proposed algorithm compared to other state-of-the-art tools, making it a useful all-in-one solution for real-world applications with limited evaluation budgets.
Partition-based formulations for mixed-integer optimization of trained ReLU neural networks
Feb 08, 2021

This paper introduces a class of mixed-integer formulations for trained ReLU neural networks. The approach balances model size and tightness by partitioning node inputs into a number of groups and forming the convex hull over the partitions via disjunctive programming. At one extreme, one partition per input recovers the convex hull of a node, i.e., the tightest possible formulation for each node. For fewer partitions, we develop smaller relaxations that approximate the convex hull, and show that they outperform existing formulations. Specifically, we propose strategies for partitioning variables based on theoretical motivations and validate these strategies using extensive computational experiments. Furthermore, the proposed scheme complements known algorithmic approaches, e.g., optimization-based bound tightening captures dependencies within a partition.
ENTMOOT: A Framework for Optimization over Ensemble Tree Models
Mar 10, 2020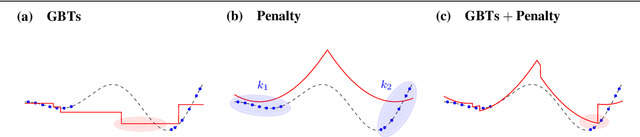
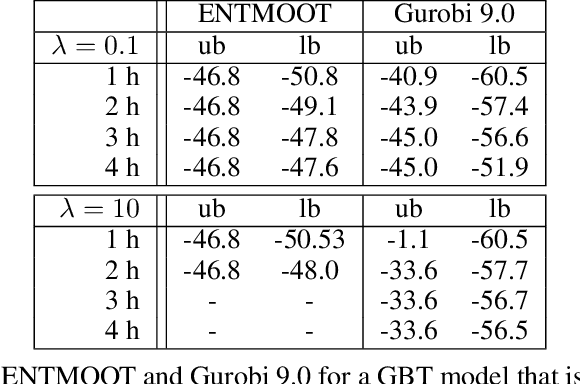


Gradient boosted trees and other regression tree models perform well in a wide range of real-world, industrial applications. These tree models (i) offer insight into important prediction features, (ii) effectively manage sparse data, and (iii) have excellent prediction capabilities. Despite their advantages, they are generally unpopular for decision-making tasks and black-box optimization, which is due to their difficult-to-optimize structure and the lack of a reliable uncertainty measure. ENTMOOT is our new framework for integrating (already trained) tree models into larger optimization problems. The contributions of ENTMOOT include: (i) explicitly introducing a reliable uncertainty measure that is compatible with tree models, (ii) solving the larger optimization problems that incorporate these uncertainty aware tree models, (iii) proving that the solutions are globally optimal, i.e. no better solution exists. In particular, we show how the ENTMOOT approach allows a simple integration of tree models into decision-making and black-box optimization, where it proves as a strong competitor to commonly-used frameworks.