 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximizing information from chemical engineering data sets: Applications to machine learning
Paper and Code
Jan 25, 2022
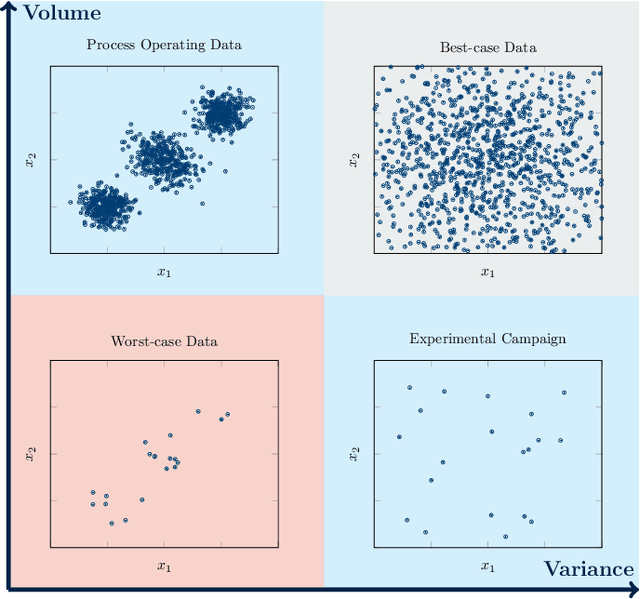
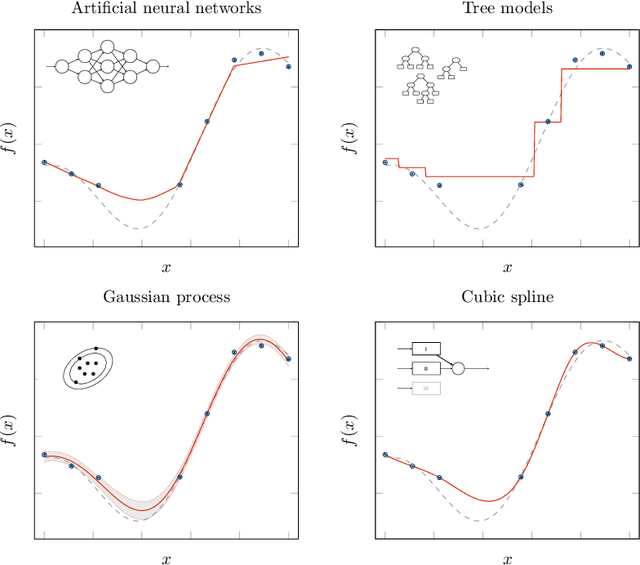
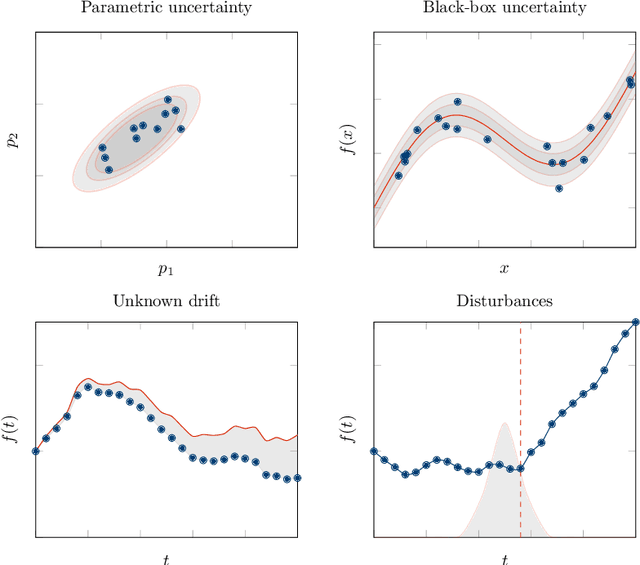
It is well-documented how artificial intelligence can have (and already is having) a big impact on chemical engineering. But classical machine learning approaches may be weak for many chemical engineering applications. This review discusses how challenging data characteristics arise in chemical engineering applications. We identify four characteristics of data arising in chemical engineering applications that make applying classical artificial intelligence approaches difficult: (1) high variance, low volume data, (2) low variance, high volume data, (3) noisy/corrupt/missing data, and (4) restricted data with physics-based limitations. For each of these four data characteristics, we discuss applications where these data characteristics arise and show how current chemical engineering research is extending the fields of data science and machine learning to incorporate these challenges. Finally, we identify several challenges for future research.