 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenCP: Towards Generative Modeling Paradigm of Coupled Physics
Jan 27, 2026Real-world physical systems are inherently complex, often involving the coupling of multiple physics, making their simulation both highly valuable and challenging. Many mainstream approaches face challenges when dealing with decoupled data. Besides, they also suffer from low efficiency and fidelity in strongly coupled spatio-temporal physical systems. Here we propose GenCP, a novel and elegant generative paradigm for coupled multiphysics simulation. By formulating coupled-physics modeling as a probability modeling problem, our key innovation is to integrate probability density evolution in generative modeling with iterative multiphysics coupling, thereby enabling training on data from decoupled simulation and inferring coupled physics during sampling. We also utilize operator-splitting theory in the space of probability evolution to establish error controllability guarantees for this "conditional-to-joint" sampling scheme. We evaluate our paradigm on a synthetic setting and three challenging multi-physics scenarios to demonstrate both principled insight and superior application performance of GenCP. Code is available at this repo: github.com/AI4Science-WestlakeU/GenCP.
RealPDEBench: A Benchmark for Complex Physical Systems with Real-World Data
Jan 05, 2026Predicting the evolution of complex physical systems remains a central problem in science and engineering. Despite rapid progress in scientific Machine Learning (ML) models, a critical bottleneck is the lack of expensive real-world data, resulting in most current models being trained and validated on simulated data. Beyond limiting the development and evaluation of scientific ML, this gap also hinders research into essential tasks such as sim-to-real transfer. We introduce RealPDEBench, the first benchmark for scientific ML that integrates real-world measurements with paired numerical simulations. RealPDEBench consists of five datasets, three tasks, eight metrics, and ten baselines. We first present five real-world measured datasets with paired simulated datasets across different complex physical systems. We further define three tasks, which allow comparisons between real-world and simulated data, and facilitate the development of methods to bridge the two. Moreover, we design eight evaluation metrics, spanning data-oriented and physics-oriented metrics, and finally benchmark ten representative baselines, including state-of-the-art models, pretrained PDE foundation models, and a traditional method. Experiments reveal significant discrepancies between simulated and real-world data, while showing that pretraining with simulated data consistently improves both accuracy and convergence. In this work, we hope to provide insights from real-world data, advancing scientific ML toward bridging the sim-to-real gap and real-world deployment. Our benchmark, datasets, and instructions are available at https://realpdebench.github.io/.
From Uncertain to Safe: Conformal Fine-Tuning of Diffusion Models for Safe PDE Control
Feb 04, 2025



The application of deep learning for partial differential equation (PDE)-constrained control is gaining increasing attention. However, existing methods rarely consider safety requirements crucial in real-world applications. To address this limitation, we propose Safe Diffusion Models for PDE Control (SafeDiffCon), which introduce the uncertainty quantile as model uncertainty quantification to achieve optimal control under safety constraints through both post-training and inference phases. Firstly, our approach post-trains a pre-trained diffusion model to generate control sequences that better satisfy safety constraints while achieving improved control objectives via a reweighted diffusion loss, which incorporates the uncertainty quantile estimated using conformal prediction. Secondly, during inference, the diffusion model dynamically adjusts both its generation process and parameters through iterative guidance and fine-tuning, conditioned on control targets while simultaneously integrating the estimated uncertainty quantile. We evaluate SafeDiffCon on three control tasks: 1D Burgers' equation, 2D incompressible fluid, and controlled nuclear fusion problem. Results demonstrate that SafeDiffCon is the only method that satisfies all safety constraints, whereas other classical and deep learning baselines fail. Furthermore, while adhering to safety constraints, SafeDiffCon achieves the best control performance.
How to Re-enable PDE Loss for Physical Systems Modeling Under Partial Observation
Dec 12, 2024In science and engineering, machine learning techniques are increasingly successful in physical systems modeling (predicting future states of physical systems). Effectively integrating PDE loss as a constraint of system transition can improve the model's prediction by overcoming generalization issues due to data scarcity, especially when data acquisition is costly. However, in many real-world scenarios, due to sensor limitations, the data we can obtain is often only partial observation, making the calculation of PDE loss seem to be infeasible, as the PDE loss heavily relies on high-resolution states. We carefully study this problem and propose a novel framework named Re-enable PDE Loss under Partial Observation (RPLPO). The key idea is that although enabling PDE loss to constrain system transition solely is infeasible, we can re-enable PDE loss by reconstructing the learnable high-resolution state and constraining system transition simultaneously. Specifically, RPLPO combines an encoding module for reconstructing learnable high-resolution states with a transition module for predicting future states. The two modules are jointly trained by data and PDE loss. We conduct experiments in various physical systems to demonstrate that RPLPO has significant improvement in generalization, even when observation is sparse, irregular, noisy, and PDE is inaccurate. The code is available on GitHub: RPLPO.
Wavelet Diffusion Neural Operator
Dec 06, 2024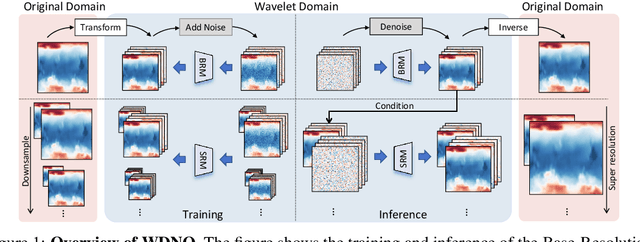
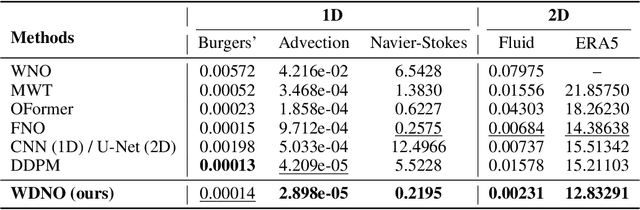
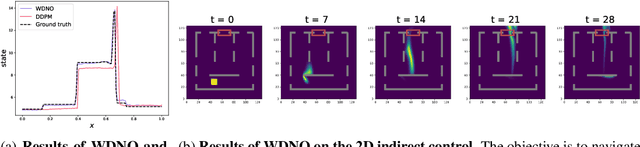
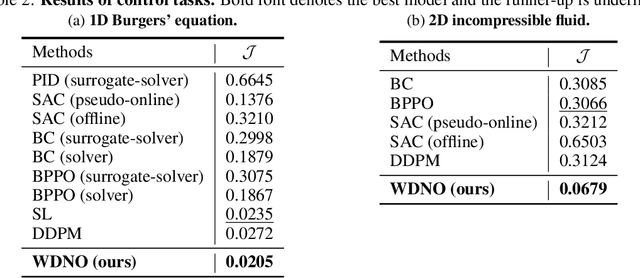
Simulating and controlling physical systems described by partial differential equations (PDEs) are crucial tasks across science and engineering. Recently, diffusion generative models have emerged as a competitive class of methods for these tasks due to their ability to capture long-term dependencies and model high-dimensional states. However, diffusion models typically struggle with handling system states with abrupt changes and generalizing to higher resolutions. In this work, we propose Wavelet Diffusion Neural Operator (WDNO), a novel PDE simulation and control framework that enhances the handling of these complexities. WDNO comprises two key innovations. Firstly, WDNO performs diffusion-based generative modeling in the wavelet domain for the entire trajectory to handle abrupt changes and long-term dependencies effectively. Secondly, to address the issue of poor generalization across different resolutions, which is one of the fundamental tasks in modeling physical systems, we introduce multi-resolution training. We validate WDNO on five physical systems, including 1D advection equation, three challenging physical systems with abrupt changes (1D Burgers' equation, 1D compressible Navier-Stokes equation and 2D incompressible fluid), and a real-world dataset ERA5, which demonstrates superior performance on both simulation and control tasks over state-of-the-art methods, with significant improvements in long-term and detail prediction accuracy. Remarkably, in the challenging context of the 2D high-dimensional and indirect control task aimed at reducing smoke leakage, WDNO reduces the leakage by 33.2% compared to the second-best baseline.
Multimodal Policies with Physics-informed Representations
Oct 20, 2024



In the control problems of the PDE systems, observation is important to make the decision. However, the observation is generally sparse and missing in practice due to the limitation and fault of sensors. The above challenges cause observations with uncertain quantities and modalities. Therefore, how to leverage the uncertain observations as the states in control problems of the PDE systems has become a scientific problem. The dynamics of PDE systems rely on the initial conditions, boundary conditions, and PDE formula. Given the above three elements, PINNs can be used to solve the PDE systems. In this work, we discover that the neural network can also be used to identify and represent the PDE systems using PDE loss and sparse data loss. Inspired by the above discovery, we propose a Physics-Informed Representation (PIR) algorithm for multimodal policies in PDE systems' control. It leverages PDE loss to fit the neural network and data loss calculated on the observations with random quantities and modalities to propagate the information of initial conditions and boundary conditions into the inputs. The inputs can be the learnable parameters or the output of the encoders. Then, under the environments of the PDE systems, such inputs are the representation of the current state. In our experiments, the PIR illustrates the superior consistency with the features of the ground truth compared with baselines, even when there are missing modalities. Furthermore, PIR has been successfully applied in the downstream control tasks where the robot leverages the learned state by PIR faster and more accurately, passing through the complex vortex street from a random starting location to reach a random target.
Closed-loop Diffusion Control of Complex Physical Systems
Jul 31, 2024



The control problems of complex physical systems have wide applications in science and engineering. Several previous works have demonstrated that generative control methods based on diffusion models have significant advantages for solving these problems. However, existing generative control methods face challenges in handling closed-loop control, which is an inherent constraint for effective control of complex physical systems. In this paper, we propose a Closed-Loop Diffusion method for Physical systems Control (CL-DiffPhyCon). By adopting an asynchronous denoising schedule for different time steps, CL-DiffPhyCon generates control signals conditioned on real-time feedback from the environment. Thus, CL-DiffPhyCon is able to speed up diffusion control methods in a closed-loop framework. We evaluate CL-DiffPhyCon on the 1D Burgers' equation control and 2D incompressible fluid control tasks. The results demonstrate that CL-DiffPhyCon achieves notable control performance with significant sampling acceleration.
A Generative Approach to Control Complex Physical Systems
Jul 09, 2024



Controlling the evolution of complex physical systems is a fundamental task across science and engineering. Classical techniques suffer from limited applicability or huge computational costs. On the other hand, recent deep learning and reinforcement learning-based approaches often struggle to optimize long-term control sequences under the constraints of system dynamics. In this work, we introduce Diffusion Physical systems Control (DiffPhyCon), a new class of method to address the physical systems control problem. DiffPhyCon excels by simultaneously minimizing both the learned generative energy function and the predefined control objectives across the entire trajectory and control sequence. Thus, it can explore globally and identify near-optimal control sequences. Moreover, we enhance DiffPhyCon with prior reweighting, enabling the discovery of control sequences that significantly deviate from the training distribution. We test our method in 1D Burgers' equation and 2D jellyfish movement control in a fluid environment. Our method outperforms widely applied classical approaches and state-of-the-art deep learning and reinforcement learning methods. Notably, DiffPhyCon unveils an intriguing fast-close-slow-open pattern observed in the jellyfish, aligning with established findings in the field of fluid dynamics.
Efficient Navigation of a Robotic Fish Swimming Across the Vortical Flow Field
May 23, 2024Navigating efficiently across vortical flow fields presents a significant challenge in various robotic applications. The dynamic and unsteady nature of vortical flows often disturbs the control of underwater robots, complicating their operation in hydrodynamic environments. Conventional control methods, which depend on accurate modeling, fail in these settings due to the complexity of fluid-structure interactions (FSI) caused by unsteady hydrodynamics. This study proposes a deep reinforcement learning (DRL) algorithm, trained in a data-driven manner, to enable efficient navigation of a robotic fish swimming across vortical flows. Our proposed algorithm incorporates the LSTM architecture and uses several recent consecutive observations as the state to address the issue of partial observation, often due to sensor limitations. We present a numerical study of navigation within a Karman vortex street, created by placing a stationary cylinder in a uniform flow, utilizing the immersed boundary-lattice Boltzmann method (IB-LBM). The aim is to train the robotic fish to discover efficient navigation policies, enabling it to reach a designated target point across the Karman vortex street from various initial positions. After training, the fish demonstrates the ability to rapidly reach the target from different initial positions, showcasing the effectiveness and robustness of our proposed algorithm. Analysis of the results reveals that the robotic fish can leverage velocity gains and pressure differences induced by the vortices to reach the target, underscoring the potential of our proposed algorithm in enhancing navigation in complex hydrodynamic environments.
How to Control Hydrodynamic Force on Fluidic Pinball via Deep Reinforcement Learning
Apr 23, 2023Deep reinforcement learning (DRL) for fluidic pinball, three individually rotating cylinders in the uniform flow arranged in an equilaterally triangular configuration, can learn the efficient flow control strategies due to the validity of self-learning and data-driven state estimation for complex fluid dynamic problems. In this work, we present a DRL-based real-time feedback strategy to control the hydrodynamic force on fluidic pinball, i.e., force extremum and tracking, from cylinders' rotation. By adequately designing reward functions and encoding historical observations, and after automatic learning of thousands of iterations, the DRL-based control was shown to make reasonable and valid control decisions in nonparametric control parameter space, which is comparable to and even better than the optimal policy found through lengthy brute-force searching. Subsequently, one of these results was analyzed by a machine learning model that enabled us to shed light on the basis of decision-making and physical mechanisms of the force tracking process. The finding from this work can control hydrodynamic force on the operation of fluidic pinball system and potentially pave the way for exploring efficient active flow control strategies in other complex fluid dynamic problems.