 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrior-guided Fusion of Multimodal Features for Change Detection from Optical-SAR Images
Apr 07, 2026Multimodal change detection (MMCD) identifies changed areas in multimodal remote sensing (RS) data, demonstrating significant application value in land use monitoring, disaster assessment, and urban sustainable development. However, literature MMCD approaches exhibit limitations in cross-modal interaction and exploiting modality-specific characteristics. This leads to insufficient modeling of fine-grained change information, thus hindering the precise detection of semantic changes in multimodal data. To address the above problems, we propose STSF-Net, a framework designed for MMCD between optical and SAR images. STSF-Net jointly models modality-specific and spatio-temporal common features to enhance change representations. Specifically, modality-specific features are exploited to capture genuine semantic change signals, while spatio-temporal common features are embedded to suppress pseudo-changes caused by differences in imaging mechanisms. Furthermore, we introduce an optical and SAR feature fusion strategy that adaptively adjusts feature importance based on semantic priors obtained from pre-trained foundational models, enabling semantic-guided adaptive fusion of multi-modal information. In addition, we introduce the Delta-SN6 dataset, the first openly-accessible multiclass MMCD benchmark consisting of very-high-resolution (VHR) fully polarimetric SAR and optical images. Experimental results on Delta-SN6, BRIGHT, and Wuhan-Het datasets demonstrate that our method outperforms the state-of-the-art (SOTA) by 3.21%, 1.08%, and 1.32% in mIoU, respectively. The associated code and Delta-SN6 dataset will be released at: https://github.com/liuxuanguang/STSF-Net.
DuInNet: Dual-Modality Feature Interaction for Point Cloud Completion
Jul 10, 2024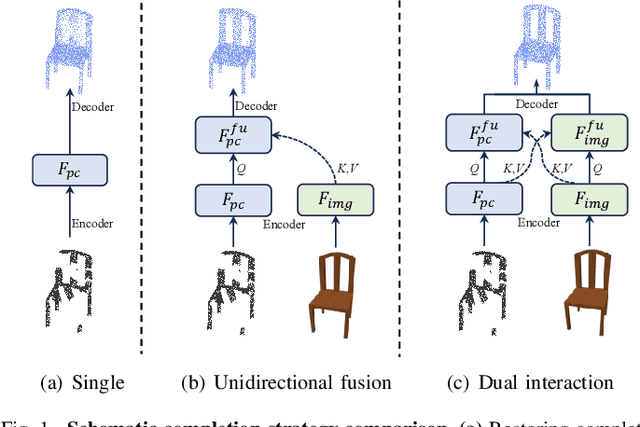
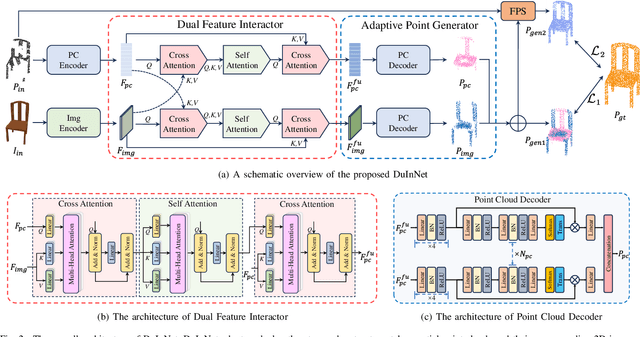
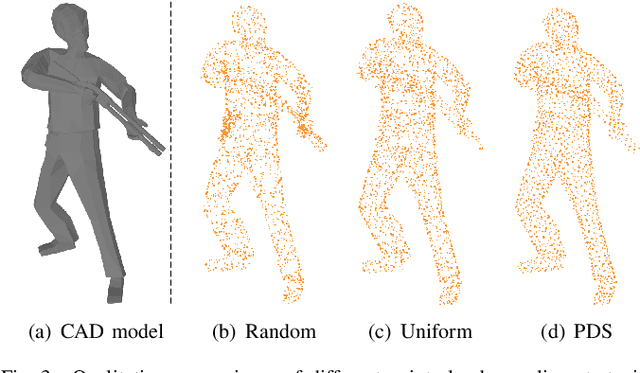
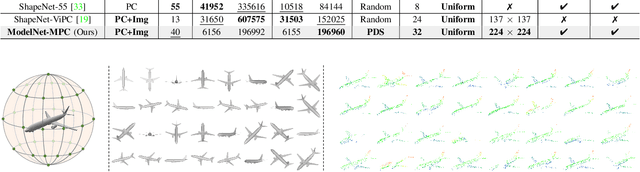
To further promote the development of multimodal point cloud completion, we contribute a large-scale multimodal point cloud completion benchmark ModelNet-MPC with richer shape categories and more diverse test data, which contains nearly 400,000 pairs of high-quality point clouds and rendered images of 40 categories. Besides the fully supervised point cloud completion task, two additional tasks including denoising completion and zero-shot learning completion are proposed in ModelNet-MPC, to simulate real-world scenarios and verify the robustness to noise and the transfer ability across categories of current methods. Meanwhile, considering that existing multimodal completion pipelines usually adopt a unidirectional fusion mechanism and ignore the shape prior contained in the image modality, we propose a Dual-Modality Feature Interaction Network (DuInNet) in this paper. DuInNet iteratively interacts features between point clouds and images to learn both geometric and texture characteristics of shapes with the dual feature interactor. To adapt to specific tasks such as fully supervised, denoising, and zero-shot learning point cloud completions, an adaptive point generator is proposed to generate complete point clouds in blocks with different weights for these two modalities. Extensive experiments on the ShapeNet-ViPC and ModelNet-MPC benchmarks demonstrate that DuInNet exhibits superiority, robustness and transfer ability in all completion tasks over state-of-the-art methods. The code and dataset will be available soon.
Deep Semantic Graph Matching for Large-scale Outdoor Point Clouds Registration
Aug 10, 2023The current point cloud registration methods are mainly based on geometric information and usually ignore the semantic information in the point clouds. In this paper, we treat the point cloud registration problem as semantic instance matching and registration task, and propose a deep semantic graph matching method for large-scale outdoor point cloud registration. Firstly, the semantic category labels of 3D point clouds are obtained by utilizing large-scale point cloud semantic segmentation network. The adjacent points with the same category labels are then clustered together by using Euclidean clustering algorithm to obtain the semantic instances. Secondly, the semantic adjacency graph is constructed based on the spatial adjacency relation of semantic instances. Three kinds of high-dimensional features including geometric shape features, semantic categorical features and spatial distribution features are learned through graph convolutional network, and enhanced based on attention mechanism. Thirdly, the semantic instance matching problem is modeled as an optimal transport problem, and solved through an optimal matching layer. Finally, according to the matched semantic instances, the geometric transformation matrix between two point clouds is first obtained by SVD algorithm and then refined by ICP algorithm. The experiments are cconducted on the KITTI Odometry dataset, and the average relative translation error and average relative rotation error of the proposed method are 6.6cm and 0.229{\deg} respectively.
3DAC: Learning Attribute Compression for Point Clouds
Mar 17, 2022
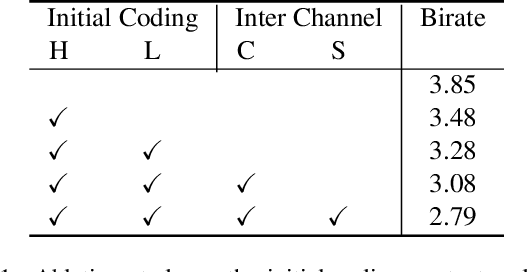
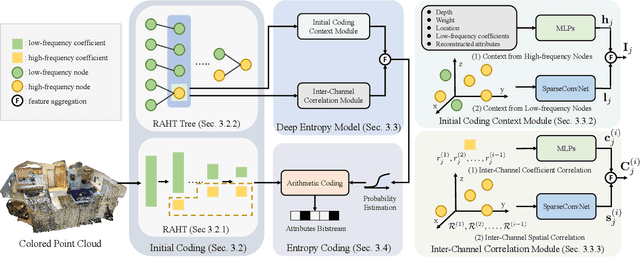
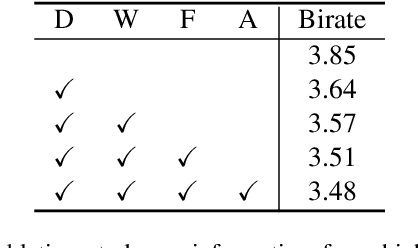
We study the problem of attribute compression for large-scale unstructured 3D point clouds. Through an in-depth exploration of the relationships between different encoding steps and different attribute channels, we introduce a deep compression network, termed 3DAC, to explicitly compress the attributes of 3D point clouds and reduce storage usage in this paper. Specifically, the point cloud attributes such as color and reflectance are firstly converted to transform coefficients. We then propose a deep entropy model to model the probabilities of these coefficients by considering information hidden in attribute transforms and previous encoded attributes. Finally, the estimated probabilities are used to further compress these transform coefficients to a final attributes bitstream. Extensive experiments conducted on both indoor and outdoor large-scale open point cloud datasets, including ScanNet and SemanticKITTI, demonstrated the superior compression rates and reconstruction quality of the proposed 3DAC.
Deep Learning for 3D Point Clouds: A Survey
Dec 27, 2019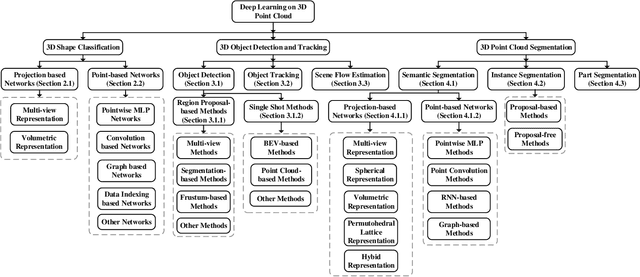
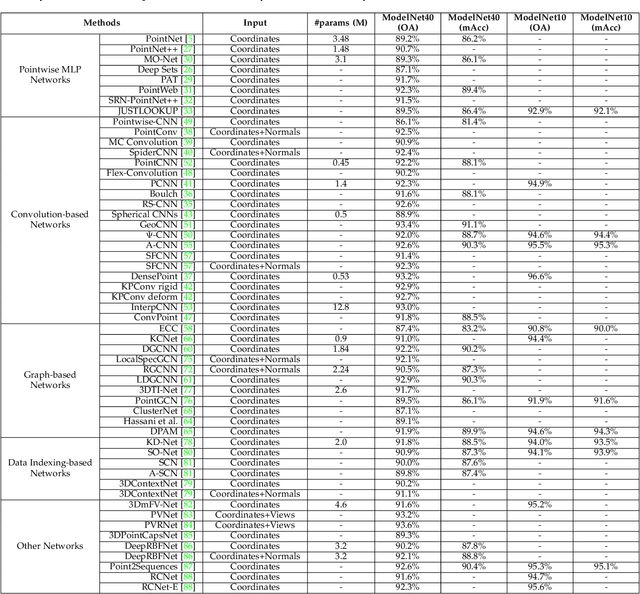
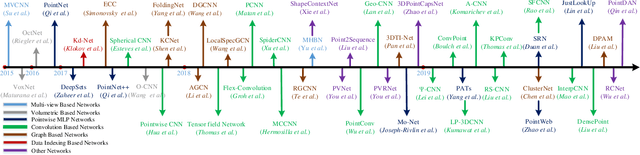
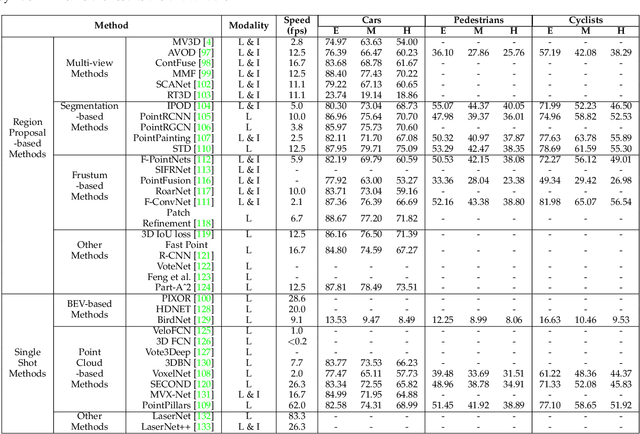
Point cloud learning has lately attracted increasing attention due to its wide applications in many areas, such as computer vision, autonomous driving, and robotics. As a dominating technique in AI, deep learning has been successfully used to solve various 2D vision problems. However, deep learning on point clouds is still in its infancy due to the unique challenges faced by the processing of point clouds with deep neural networks. Recently, deep learning on point clouds has become even thriving, with numerous methods being proposed to address different problems in this area. To stimulate future research, this paper presents a comprehensive review of recent progress in deep learning methods for point clouds. It covers three major tasks, including 3D shape classification, 3D object detection and tracking, and 3D point cloud segmentation. It also presents comparative results on several publicly available datasets, together with insightful observations and inspiring future research directions.