 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelayGR: Scaling Long-Sequence Generative Recommendation via Cross-Stage Relay-Race Inference
Jan 05, 2026Real-time recommender systems execute multi-stage cascades (retrieval, pre-processing, fine-grained ranking) under strict tail-latency SLOs, leaving only tens of milliseconds for ranking. Generative recommendation (GR) models can improve quality by consuming long user-behavior sequences, but in production their online sequence length is tightly capped by the ranking-stage P99 budget. We observe that the majority of GR tokens encode user behaviors that are independent of the item candidates, suggesting an opportunity to pre-infer a user-behavior prefix once and reuse it during ranking rather than recomputing it on the critical path. Realizing this idea at industrial scale is non-trivial: the prefix cache must survive across multiple pipeline stages before the final ranking instance is determined, the user population implies cache footprints far beyond a single device, and indiscriminate pre-inference would overload shared resources under high QPS. We present RelayGR, a production system that enables in-HBM relay-race inference for GR. RelayGR selectively pre-infers long-term user prefixes, keeps their KV caches resident in HBM over the request lifecycle, and ensures the subsequent ranking can consume them without remote fetches. RelayGR combines three techniques: 1) a sequence-aware trigger that admits only at-risk requests under a bounded cache footprint and pre-inference load, 2) an affinity-aware router that co-locates cache production and consumption by routing both the auxiliary pre-infer signal and the ranking request to the same instance, and 3) a memory-aware expander that uses server-local DRAM to capture short-term cross-request reuse while avoiding redundant reloads. We implement RelayGR on Huawei Ascend NPUs and evaluate it with real queries. Under a fixed P99 SLO, RelayGR supports up to 1.5$\times$ longer sequences and improves SLO-compliant throughput by up to 3.6$\times$.
P/D-Device: Disaggregated Large Language Model between Cloud and Devices
Aug 12, 2025Serving disaggregated large language models has been widely adopted in industrial practice for enhanced performance. However, too many tokens generated in decoding phase, i.e., occupying the resources for a long time, essentially hamper the cloud from achieving a higher throughput. Meanwhile, due to limited on-device resources, the time to first token (TTFT), i.e., the latency of prefill phase, increases dramatically with the growth on prompt length. In order to concur with such a bottleneck on resources, i.e., long occupation in cloud and limited on-device computing capacity, we propose to separate large language model between cloud and devices. That is, the cloud helps a portion of the content for each device, only in its prefill phase. Specifically, after receiving the first token from the cloud, decoupling with its own prefill, the device responds to the user immediately for a lower TTFT. Then, the following tokens from cloud are presented via a speed controller for smoothed TPOT (the time per output token), until the device catches up with the progress. On-device prefill is then amortized using received tokens while the resource usage in cloud is controlled. Moreover, during cloud prefill, the prompt can be refined, using those intermediate data already generated, to further speed up on-device inference. We implement such a scheme P/D-Device, and confirm its superiority over other alternatives. We further propose an algorithm to decide the best settings. Real-trace experiments show that TTFT decreases at least 60%, maximum TPOT is about tens of milliseconds, and cloud throughput increases by up to 15x.
SuperMapNet for Long-Range and High-Accuracy Vectorized HD Map Construction
May 20, 2025



Vectorized HD map is essential for autonomous driving. Remarkable work has been achieved in recent years, but there are still major issues: (1) in the generation of the BEV features, single modality-based methods are of limited perception capability, while direct concatenation-based multi-modal methods fail to capture synergies and disparities between different modalities, resulting in limited ranges with feature holes; (2) in the classification and localization of map elements, only point information is used without the consideration of element infor-mation and neglects the interaction between point information and element information, leading to erroneous shapes and element entanglement with low accuracy. To address above issues, we introduce SuperMapNet for long-range and high-accuracy vectorized HD map construction. It uses both camera images and LiDAR point clouds as input, and first tightly couple semantic information from camera images and geometric information from LiDAR point clouds by a cross-attention based synergy enhancement module and a flow-based disparity alignment module for long-range BEV feature generation. And then, local features from point queries and global features from element queries are tightly coupled by three-level interactions for high-accuracy classification and localization, where Point2Point interaction learns local geometric information between points of the same element and of each point, Element2Element interaction learns relation constraints between different elements and semantic information of each elements, and Point2Element interaction learns complement element information for its constituent points. Experiments on the nuScenes and Argoverse2 datasets demonstrate superior performances, surpassing SOTAs over 14.9/8.8 mAP and 18.5/3.1 mAP under hard/easy settings, respectively. The code is made publicly available1.
P/D-Serve: Serving Disaggregated Large Language Model at Scale
Aug 15, 2024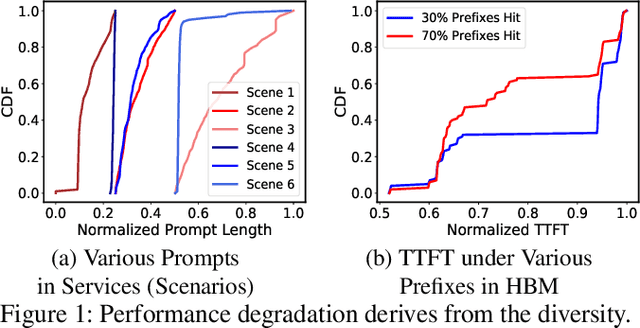
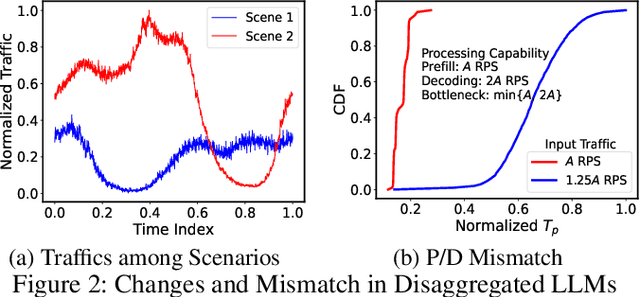
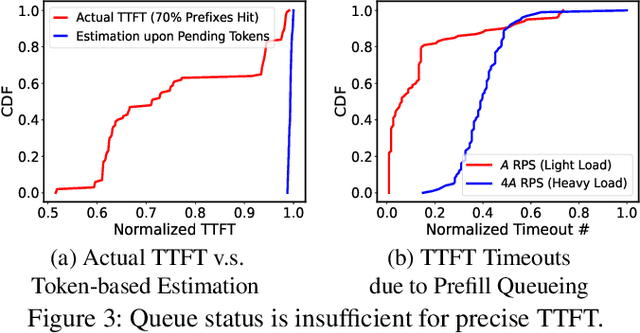
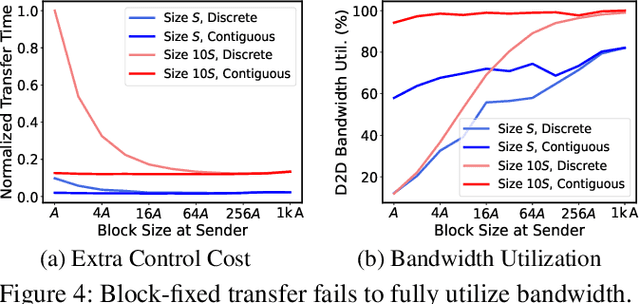
Serving disaggregated large language models (LLMs) over tens of thousands of xPU devices (GPUs or NPUs) with reliable performance faces multiple challenges. 1) Ignoring the diversity (various prefixes and tidal requests), treating all the prompts in a mixed pool is inadequate. To facilitate the similarity per scenario and minimize the inner mismatch on P/D (prefill and decoding) processing, fine-grained organization is required, dynamically adjusting P/D ratios for better performance. 2) Due to inaccurate estimation on workload (queue status or maintained connections), the global scheduler easily incurs unnecessary timeouts in prefill. 3) Block-fixed device-to-device (D2D) KVCache transfer over cluster-level RDMA (remote direct memory access) fails to achieve desired D2D utilization as expected. To overcome previous problems, this paper proposes an end-to-end system P/D-Serve, complying with the paradigm of MLOps (machine learning operations), which models end-to-end (E2E) P/D performance and enables: 1) fine-grained P/D organization, mapping the service with RoCE (RDMA over converged ethernet) as needed, to facilitate similar processing and dynamic adjustments on P/D ratios; 2) on-demand forwarding upon rejections for idle prefill, decoupling the scheduler from regular inaccurate reports and local queues, to avoid timeouts in prefill; and 3) efficient KVCache transfer via optimized D2D access. P/D-Serve is implemented upon Ascend and MindSpore, has been deployed over tens of thousands of NPUs for more than eight months in commercial use, and further achieves 60\%, 42\% and 46\% improvements on E2E throughput, time-to-first-token (TTFT) SLO (service level objective) and D2D transfer time. As the E2E system with optimizations, P/D-Serve achieves 6.7x increase on throughput, compared with aggregated LLMs.
Deep Semantic Graph Matching for Large-scale Outdoor Point Clouds Registration
Aug 10, 2023The current point cloud registration methods are mainly based on geometric information and usually ignore the semantic information in the point clouds. In this paper, we treat the point cloud registration problem as semantic instance matching and registration task, and propose a deep semantic graph matching method for large-scale outdoor point cloud registration. Firstly, the semantic category labels of 3D point clouds are obtained by utilizing large-scale point cloud semantic segmentation network. The adjacent points with the same category labels are then clustered together by using Euclidean clustering algorithm to obtain the semantic instances. Secondly, the semantic adjacency graph is constructed based on the spatial adjacency relation of semantic instances. Three kinds of high-dimensional features including geometric shape features, semantic categorical features and spatial distribution features are learned through graph convolutional network, and enhanced based on attention mechanism. Thirdly, the semantic instance matching problem is modeled as an optimal transport problem, and solved through an optimal matching layer. Finally, according to the matched semantic instances, the geometric transformation matrix between two point clouds is first obtained by SVD algorithm and then refined by ICP algorithm. The experiments are cconducted on the KITTI Odometry dataset, and the average relative translation error and average relative rotation error of the proposed method are 6.6cm and 0.229{\deg} respectively.