 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDuInNet: Dual-Modality Feature Interaction for Point Cloud Completion
Paper and Code
Jul 10, 2024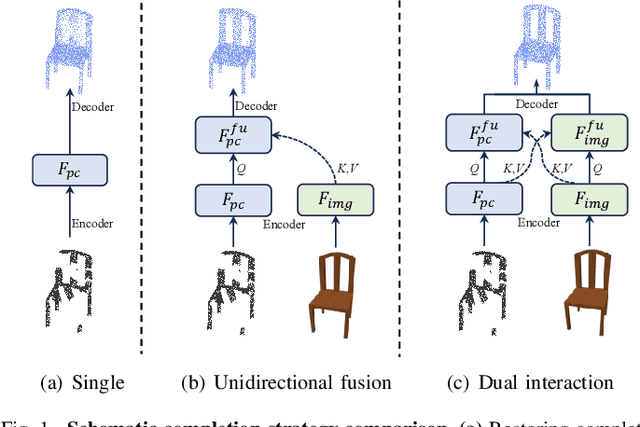
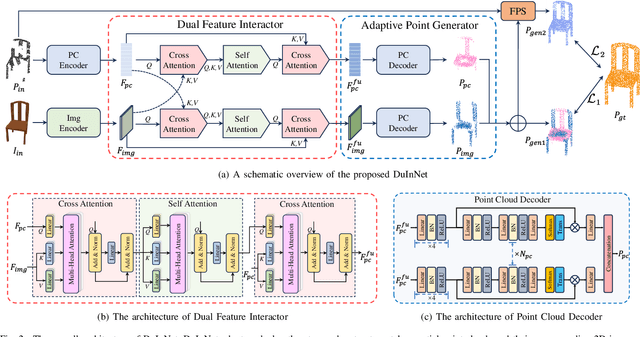
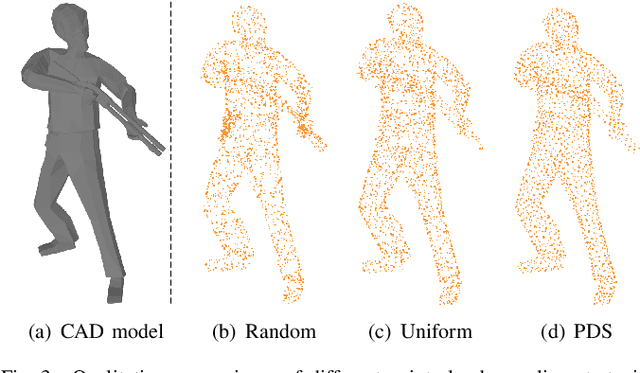
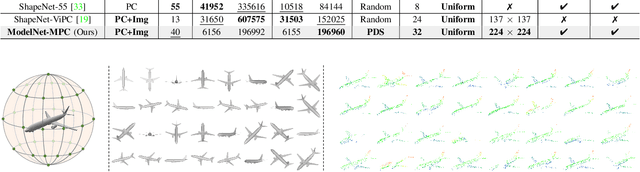
To further promote the development of multimodal point cloud completion, we contribute a large-scale multimodal point cloud completion benchmark ModelNet-MPC with richer shape categories and more diverse test data, which contains nearly 400,000 pairs of high-quality point clouds and rendered images of 40 categories. Besides the fully supervised point cloud completion task, two additional tasks including denoising completion and zero-shot learning completion are proposed in ModelNet-MPC, to simulate real-world scenarios and verify the robustness to noise and the transfer ability across categories of current methods. Meanwhile, considering that existing multimodal completion pipelines usually adopt a unidirectional fusion mechanism and ignore the shape prior contained in the image modality, we propose a Dual-Modality Feature Interaction Network (DuInNet) in this paper. DuInNet iteratively interacts features between point clouds and images to learn both geometric and texture characteristics of shapes with the dual feature interactor. To adapt to specific tasks such as fully supervised, denoising, and zero-shot learning point cloud completions, an adaptive point generator is proposed to generate complete point clouds in blocks with different weights for these two modalities. Extensive experiments on the ShapeNet-ViPC and ModelNet-MPC benchmarks demonstrate that DuInNet exhibits superiority, robustness and transfer ability in all completion tasks over state-of-the-art methods. The code and dataset will be available soon.