 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Virtual Environments to Real-World Trials: Emerging Trends in Autonomous Driving
Mar 18, 2026Autonomous driving technologies have achieved significant advances in recent years, yet their real-world deployment remains constrained by data scarcity, safety requirements, and the need for generalization across diverse environments. In response, synthetic data and virtual environments have emerged as powerful enablers, offering scalable, controllable, and richly annotated scenarios for training and evaluation. This survey presents a comprehensive review of recent developments at the intersection of autonomous driving, simulation technologies, and synthetic datasets. We organize the landscape across three core dimensions: (i) the use of synthetic data for perception and planning, (ii) digital twin-based simulation for system validation, and (iii) domain adaptation strategies bridging synthetic and real-world data. We also highlight the role of vision-language models and simulation realism in enhancing scene understanding and generalization. A detailed taxonomy of datasets, tools, and simulation platforms is provided, alongside an analysis of trends in benchmark design. Finally, we discuss critical challenges and open research directions, including Sim2Real transfer, scalable safety validation, cooperative autonomy, and simulation-driven policy learning, that must be addressed to accelerate the path toward safe, generalizable, and globally deployable autonomous driving systems.
Intelligent experiments through real-time AI: Fast Data Processing and Autonomous Detector Control for sPHENIX and future EIC detectors
Jan 08, 2025This R\&D project, initiated by the DOE Nuclear Physics AI-Machine Learning initiative in 2022, leverages AI to address data processing challenges in high-energy nuclear experiments (RHIC, LHC, and future EIC). Our focus is on developing a demonstrator for real-time processing of high-rate data streams from sPHENIX experiment tracking detectors. The limitations of a 15 kHz maximum trigger rate imposed by the calorimeters can be negated by intelligent use of streaming technology in the tracking system. The approach efficiently identifies low momentum rare heavy flavor events in high-rate p+p collisions (3MHz), using Graph Neural Network (GNN) and High Level Synthesis for Machine Learning (hls4ml). Success at sPHENIX promises immediate benefits, minimizing resources and accelerating the heavy-flavor measurements. The approach is transferable to other fields. For the EIC, we develop a DIS-electron tagger using Artificial Intelligence - Machine Learning (AI-ML) algorithms for real-time identification, showcasing the transformative potential of AI and FPGA technologies in high-energy nuclear and particle experiments real-time data processing pipelines.
DeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
Foresee and Act Ahead: Task Prediction and Pre-Scheduling Enabled Efficient Robotic Warehousing
Dec 09, 2024In warehousing systems, to enhance logistical efficiency amid surging demand volumes, much focus is placed on how to reasonably allocate tasks to robots. However, the robots labor is still inevitably wasted to some extent. In response to this, we propose a pre-scheduling enhanced warehousing framework that predicts task flow and acts in advance. It consists of task flow prediction and hybrid tasks allocation. For task prediction, we notice that it is possible to provide a spatio-temporal representation of task flow, so we introduce a periodicity-decoupled mechanism tailored for the generation patterns of aggregated orders, and then further extract spatial features of task distribution with novel combination of graph structures. In hybrid tasks allocation, we consider the known tasks and predicted future tasks simultaneously and optimize the allocation dynamically. In addition, we consider factors such as predicted task uncertainty and sector-level efficiency evaluation in warehousing to realize more balanced and rational allocations. We validate our task prediction model across actual datasets derived from real factories, achieving SOTA performance. Furthermore, we implement our compelte scheduling system in a real-world robotic warehouse for months of lifelong validation, demonstrating large improvements in key metrics of warehousing, such as empty running rate, by more than 50%.
Can Agents Spontaneously Form a Society? Introducing a Novel Architecture for Generative Multi-Agents to Elicit Social Emergence
Sep 10, 2024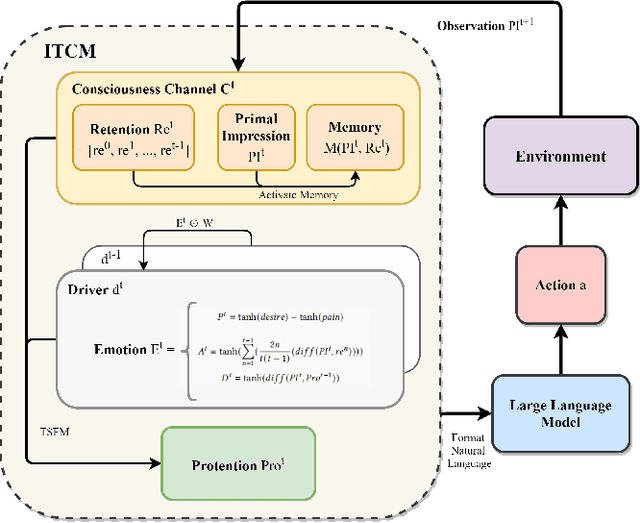
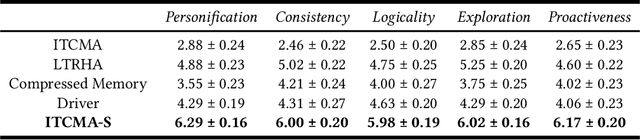
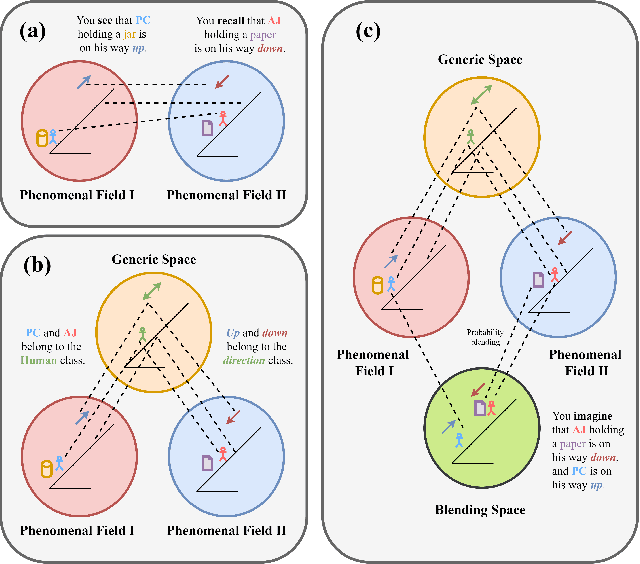
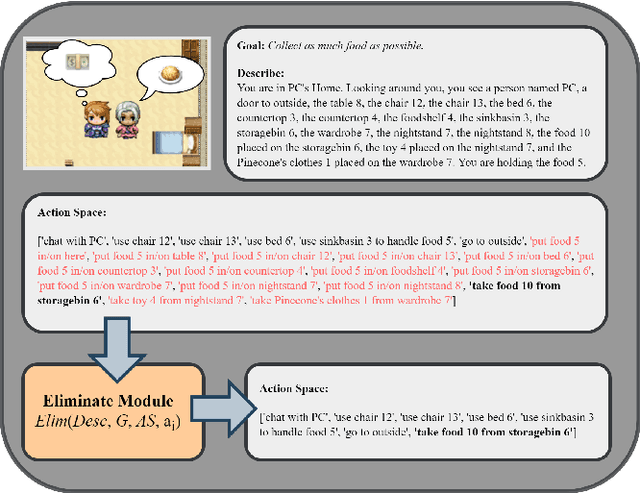
Generative agents have demonstrated impressive capabilities in specific tasks, but most of these frameworks focus on independent tasks and lack attention to social interactions. We introduce a generative agent architecture called ITCMA-S, which includes a basic framework for individual agents and a framework called LTRHA that supports social interactions among multi-agents. This architecture enables agents to identify and filter out behaviors that are detrimental to social interactions, guiding them to choose more favorable actions. We designed a sandbox environment to simulate the natural evolution of social relationships among multiple identity-less agents for experimental evaluation. The results showed that ITCMA-S performed well on multiple evaluation indicators, demonstrating its ability to actively explore the environment, recognize new agents, and acquire new information through continuous actions and dialogue. Observations show that as agents establish connections with each other, they spontaneously form cliques with internal hierarchies around a selected leader and organize collective activities.
A Strategy Transfer and Decision Support Approach for Epidemic Control in Experience Shortage Scenarios
Apr 10, 2024
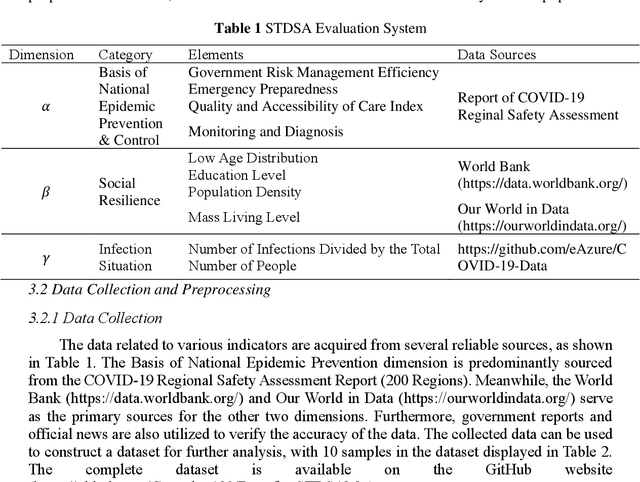


Epidemic outbreaks can cause critical health concerns and severe global economic crises. For countries or regions with new infectious disease outbreaks, it is essential to generate preventive strategies by learning lessons from others with similar risk profiles. A Strategy Transfer and Decision Support Approach (STDSA) is proposed based on the profile similarity evaluation. There are four steps in this method: (1) The similarity evaluation indicators are determined from three dimensions, i.e., the Basis of National Epidemic Prevention & Control, Social Resilience, and Infection Situation. (2) The data related to the indicators are collected and preprocessed. (3) The first round of screening on the preprocessed dataset is conducted through an improved collaborative filtering algorithm to calculate the preliminary similarity result from the perspective of the infection situation. (4) Finally, the K-Means model is used for the second round of screening to obtain the final similarity values. The approach will be applied to decision-making support in the context of COVID-19. Our results demonstrate that the recommendations generated by the STDSA model are more accurate and aligned better with the actual situation than those produced by pure K-means models. This study will provide new insights into preventing and controlling epidemics in regions that lack experience.
VCounselor: A Psychological Intervention Chat Agent Based on a Knowledge-Enhanced Large Language Model
Mar 20, 2024Conversational artificial intelligence can already independently engage in brief conversations with clients with psychological problems and provide evidence-based psychological interventions. The main objective of this study is to improve the effectiveness and credibility of the large language model in psychological intervention by creating a specialized agent, the VCounselor, to address the limitations observed in popular large language models such as ChatGPT in domain applications. We achieved this goal by proposing a new affective interaction structure and knowledge-enhancement structure. In order to evaluate VCounselor, this study compared the general large language model, the fine-tuned large language model, and VCounselor's knowledge-enhanced large language model. At the same time, the general large language model and the fine-tuned large language model will also be provided with an avatar to compare them as an agent with VCounselor. The comparison results indicated that the affective interaction structure and knowledge-enhancement structure of VCounselor significantly improved the effectiveness and credibility of the psychological intervention, and VCounselor significantly provided positive tendencies for clients' emotions. The conclusion of this study strongly supports that VConselor has a significant advantage in providing psychological support to clients by being able to analyze the patient's problems with relative accuracy and provide professional-level advice that enhances support for clients.
Interpretable Symbolic Regression for Data Science: Analysis of the 2022 Competition
Apr 06, 2023


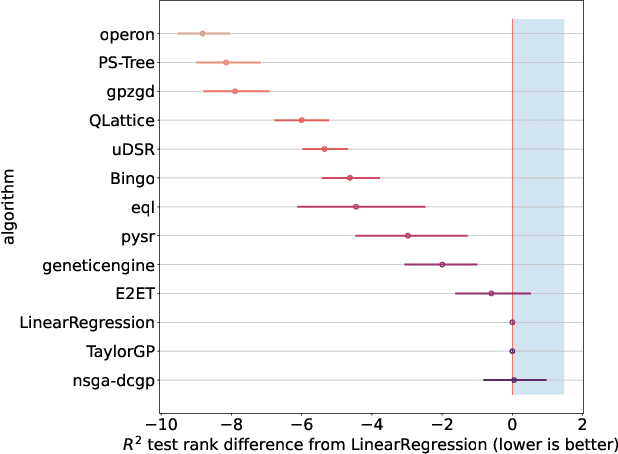
Symbolic regression searches for analytic expressions that accurately describe studied phenomena. The main attraction of this approach is that it returns an interpretable model that can be insightful to users. Historically, the majority of algorithms for symbolic regression have been based on evolutionary algorithms. However, there has been a recent surge of new proposals that instead utilize approaches such as enumeration algorithms, mixed linear integer programming, neural networks, and Bayesian optimization. In order to assess how well these new approaches behave on a set of common challenges often faced in real-world data, we hosted a competition at the 2022 Genetic and Evolutionary Computation Conference consisting of different synthetic and real-world datasets which were blind to entrants. For the real-world track, we assessed interpretability in a realistic way by using a domain expert to judge the trustworthiness of candidate models.We present an in-depth analysis of the results obtained in this competition, discuss current challenges of symbolic regression algorithms and highlight possible improvements for future competitions.
Proceedings of the third "international Traveling Workshop on Interactions between Sparse models and Technology"
Sep 14, 2016
The third edition of the "international - Traveling Workshop on Interactions between Sparse models and Technology" (iTWIST) took place in Aalborg, the 4th largest city in Denmark situated beautifully in the northern part of the country, from the 24th to 26th of August 2016. The workshop venue was at the Aalborg University campus. One implicit objective of this biennial workshop is to foster collaboration between international scientific teams by disseminating ideas through both specific oral/poster presentations and free discussions. For this third edition, iTWIST'16 gathered about 50 international participants and features 8 invited talks, 12 oral presentations, and 12 posters on the following themes, all related to the theory, application and generalization of the "sparsity paradigm": Sparsity-driven data sensing and processing (e.g., optics, computer vision, genomics, biomedical, digital communication, channel estimation, astronomy); Application of sparse models in non-convex/non-linear inverse problems (e.g., phase retrieval, blind deconvolution, self calibration); Approximate probabilistic inference for sparse problems; Sparse machine learning and inference; "Blind" inverse problems and dictionary learning; Optimization for sparse modelling; Information theory, geometry and randomness; Sparsity? What's next? (Discrete-valued signals; Union of low-dimensional spaces, Cosparsity, mixed/group norm, model-based, low-complexity models, ...); Matrix/manifold sensing/processing (graph, low-rank approximation, ...); Complexity/accuracy tradeoffs in numerical methods/optimization; Electronic/optical compressive sensors (hardware).
Large-Scale Paralleled Sparse Principal Component Analysis
Dec 21, 2013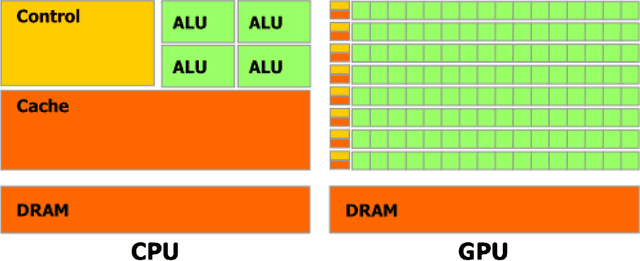
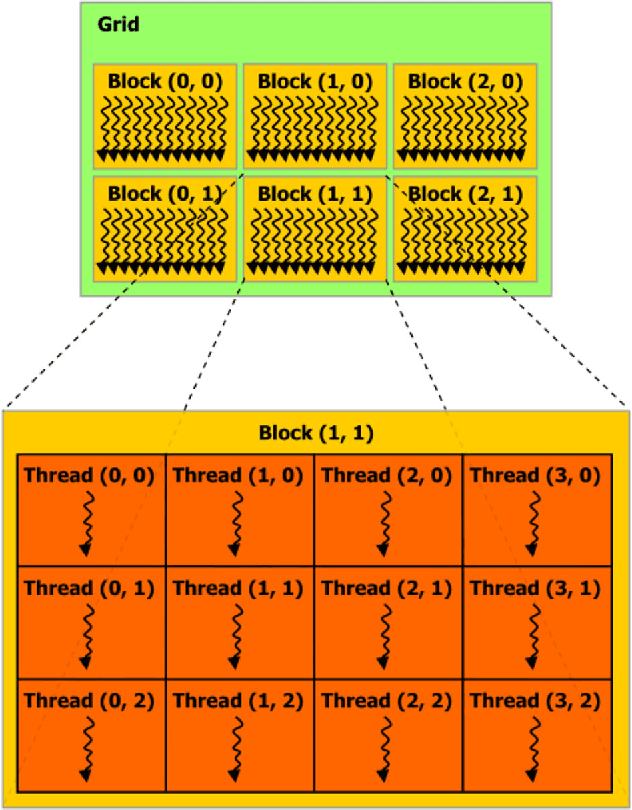
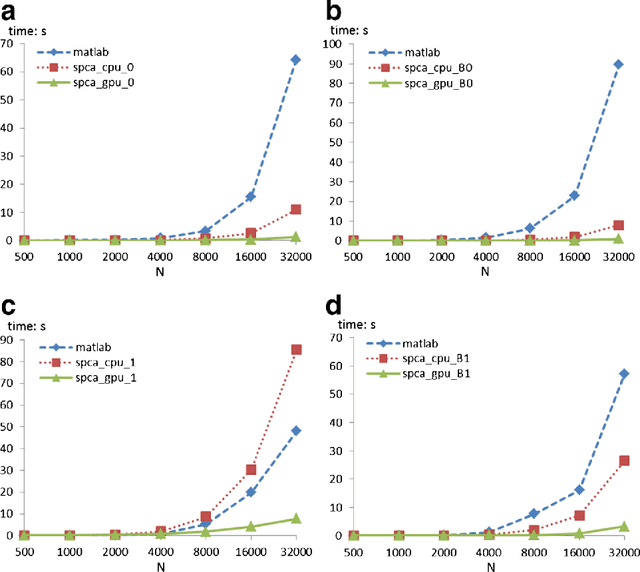

Principal component analysis (PCA) is a statistical technique commonly used in multivariate data analysis. However, PCA can be difficult to interpret and explain since the principal components (PCs) are linear combinations of the original variables. Sparse PCA (SPCA) aims to balance statistical fidelity and interpretability by approximating sparse PCs whose projections capture the maximal variance of original data. In this paper we present an efficient and paralleled method of SPCA using graphics processing units (GPUs), which can process large blocks of data in parallel. Specifically, we construct parallel implementations of the four optimization formulations of the generalized power method of SPCA (GP-SPCA), one of the most efficient and effective SPCA approaches, on a GPU. The parallel GPU implementation of GP-SPCA (using CUBLAS) is up to eleven times faster than the corresponding CPU implementation (using CBLAS), and up to 107 times faster than a MatLab implementation. Extensive comparative experiments in several real-world datasets confirm that SPCA offers a practical advantage.