 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcess In-Context Learning: Enhancing Mathematical Reasoning via Dynamic Demonstration Insertion
Jan 17, 2026In-context learning (ICL) has proven highly effective across diverse large language model (LLM) tasks. However, its potential for enhancing tasks that demand step-by-step logical deduction, such as mathematical reasoning, remains underexplored. A core limitation of existing ICL approaches is their static use of demonstrations: examples are pre-selected before inference and remain fixed, failing to adapt to the dynamic confusion points that often arise during multi-step reasoning such as ambiguous calculations or logical gaps. These unresolved confusion points can lead to cascading errors that degrade final accuracy. To tackle this issue, we propose Process In-Context Learning (PICL), a dynamic demonstration integration framework designed to boost mathematical reasoning by responding to real-time inference needs. PICL operates in two stages: 1)~it identifies potential confusion points by analyzing semantics and entropy in the reasoning process and summarizes their core characteristics; 2)~upon encountering these points, it retrieves relevant demonstrations from the demonstration pool that match the confusion context and inserts them directly into the ongoing reasoning process to guide subsequent steps. Experiments show that PICL outperforms baseline methods by mitigating mid-inference confusion, highlighting the value of adaptive demonstration insertion in complex mathematical reasoning.
Revisiting Chain-of-Thought Prompting: Zero-shot Can Be Stronger than Few-shot
Jun 17, 2025In-Context Learning (ICL) is an essential emergent ability of Large Language Models (LLMs), and recent studies introduce Chain-of-Thought (CoT) to exemplars of ICL to enhance the reasoning capability, especially in mathematics tasks. However, given the continuous advancement of model capabilities, it remains unclear whether CoT exemplars still benefit recent, stronger models in such tasks. Through systematic experiments, we find that for recent strong models such as the Qwen2.5 series, adding traditional CoT exemplars does not improve reasoning performance compared to Zero-Shot CoT. Instead, their primary function is to align the output format with human expectations. We further investigate the effectiveness of enhanced CoT exemplars, constructed using answers from advanced models such as \texttt{Qwen2.5-Max} and \texttt{DeepSeek-R1}. Experimental results indicate that these enhanced exemplars still fail to improve the model's reasoning performance. Further analysis reveals that models tend to ignore the exemplars and focus primarily on the instructions, leading to no observable gain in reasoning ability. Overall, our findings highlight the limitations of the current ICL+CoT framework in mathematical reasoning, calling for a re-examination of the ICL paradigm and the definition of exemplars.
Towards a Unified Language Model for Knowledge-Intensive Tasks Utilizing External Corpus
Feb 02, 2024The advent of large language models (LLMs) has showcased their efficacy across various domains, yet they often hallucinate, especially in knowledge-intensive tasks that require external knowledge sources. To improve factual accuracy of language models, retrieval-augmented generation (RAG) has emerged as a popular solution. However, traditional retrieval modules often rely on large-scale document indexes, which can be disconnected from generative tasks. Through generative retrieval (GR) approach, language models can achieve superior retrieval performance by directly generating relevant document identifiers (DocIDs). However, the relationship between GR and downstream tasks, as well as the potential of LLMs in GR, remains unexplored. In this paper, we present a unified language model that utilizes external corpus to handle various knowledge-intensive tasks by seamlessly integrating generative retrieval, closed-book generation, and RAG. In order to achieve effective retrieval and generation through a unified continuous decoding process, we introduce the following mechanisms: (1) a ranking-oriented DocID decoding strategy, which improves ranking ability by directly learning from a DocID ranking list; (2) a continuous generation strategy to facilitate effective and efficient RAG; (3) well-designed auxiliary DocID understanding tasks to enhance the model's comprehension of DocIDs and their relevance to downstream tasks. Our approach is evaluated on the widely used KILT benchmark using two variants of backbone models: an encoder-decoder T5 model and a decoder-only LLM, Llama2. Experimental results showcase the superior performance of our models in both retrieval and downstream knowledge-intensive tasks.
Pre-training to Match for Unified Low-shot Relation Extraction
Mar 23, 2022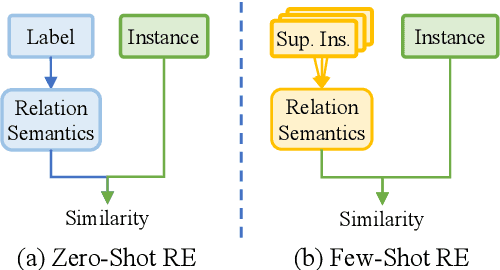
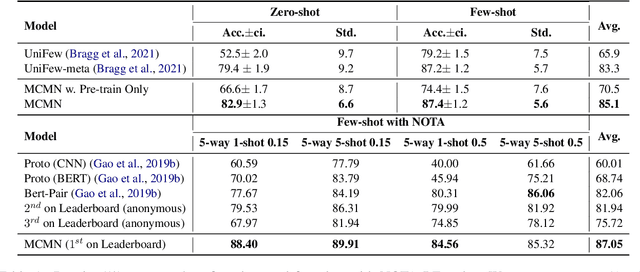
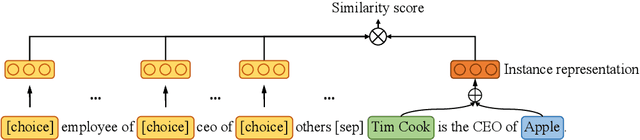

Low-shot relation extraction~(RE) aims to recognize novel relations with very few or even no samples, which is critical in real scenario application. Few-shot and zero-shot RE are two representative low-shot RE tasks, which seem to be with similar target but require totally different underlying abilities. In this paper, we propose Multi-Choice Matching Networks to unify low-shot relation extraction. To fill in the gap between zero-shot and few-shot RE, we propose the triplet-paraphrase meta-training, which leverages triplet paraphrase to pre-train zero-shot label matching ability and uses meta-learning paradigm to learn few-shot instance summarizing ability. Experimental results on three different low-shot RE tasks show that the proposed method outperforms strong baselines by a large margin, and achieve the best performance on few-shot RE leaderboard.
Can Prompt Probe Pretrained Language Models? Understanding the Invisible Risks from a Causal View
Mar 23, 2022



Prompt-based probing has been widely used in evaluating the abilities of pretrained language models (PLMs). Unfortunately, recent studies have discovered such an evaluation may be inaccurate, inconsistent and unreliable. Furthermore, the lack of understanding its inner workings, combined with its wide applicability, has the potential to lead to unforeseen risks for evaluating and applying PLMs in real-world applications. To discover, understand and quantify the risks, this paper investigates the prompt-based probing from a causal view, highlights three critical biases which could induce biased results and conclusions, and proposes to conduct debiasing via causal intervention. This paper provides valuable insights for the design of unbiased datasets, better probing frameworks and more reliable evaluations of pretrained language models. Furthermore, our conclusions also echo that we need to rethink the criteria for identifying better pretrained language models. We openly released the source code and data at https://github.com/c-box/causalEval.
Element Intervention for Open Relation Extraction
Jun 17, 2021



Open relation extraction aims to cluster relation instances referring to the same underlying relation, which is a critical step for general relation extraction. Current OpenRE models are commonly trained on the datasets generated from distant supervision, which often results in instability and makes the model easily collapsed. In this paper, we revisit the procedure of OpenRE from a causal view. By formulating OpenRE using a structural causal model, we identify that the above-mentioned problems stem from the spurious correlations from entities and context to the relation type. To address this issue, we conduct \emph{Element Intervention}, which intervenes on the context and entities respectively to obtain the underlying causal effects of them. We also provide two specific implementations of the interventions based on entity ranking and context contrasting. Experimental results on unsupervised relation extraction datasets show that our methods outperform previous state-of-the-art methods and are robust across different datasets.
From Bag of Sentences to Document: Distantly Supervised Relation Extraction via Machine Reading Comprehension
Dec 09, 2020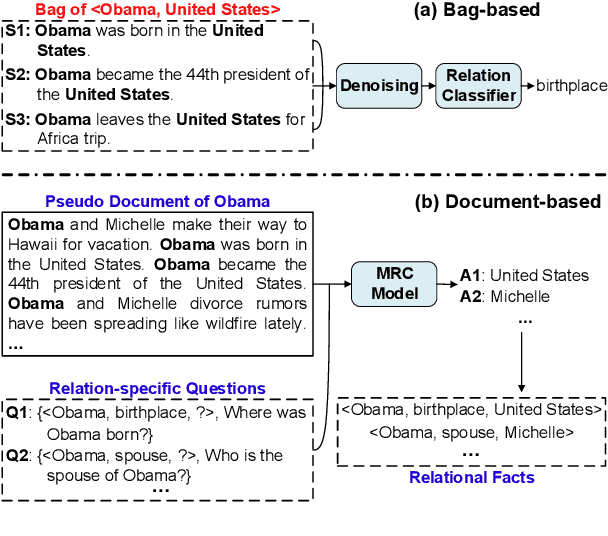

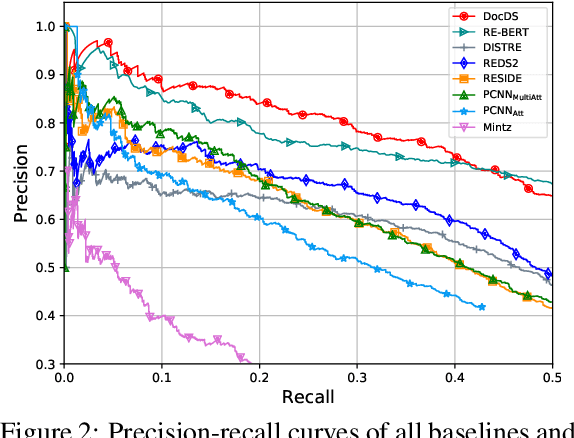
Distant supervision (DS) is a promising approach for relation extraction but often suffers from the noisy label problem. Traditional DS methods usually represent an entity pair as a bag of sentences and denoise labels using multi-instance learning techniques. The bag-based paradigm, however, fails to leverage the inter-sentence-level and the entity-level evidence for relation extraction, and their denoising algorithms are often specialized and complicated. In this paper, we propose a new DS paradigm--document-based distant supervision, which models relation extraction as a document-based machine reading comprehension (MRC) task. By re-organizing all sentences about an entity as a document and extracting relations via querying the document with relation-specific questions, the document-based DS paradigm can simultaneously encode and exploit all sentence-level, inter-sentence-level, and entity-level evidence. Furthermore, we design a new loss function--DSLoss (distant supervision loss), which can effectively train MRC models using only $\langle$document, question, answer$\rangle$ tuples, therefore noisy label problem can be inherently resolved. Experiments show that our method achieves new state-of-the-art DS performance.