 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBi-objective Optimization in Role Mining
Mar 25, 2024



Role mining is a technique used to derive a role-based authorization policy from an existing policy. Given a set of users $U$, a set of permissions $P$ and a user-permission authorization relation $\mahtit{UPA}\subseteq U\times P$, a role mining algorithm seeks to compute a set of roles $R$, a user-role authorization relation $\mathit{UA}\subseteq U\times R$ and a permission-role authorization relation $\mathit{PA}\subseteq R\times P$, such that the composition of $\mathit{UA}$ and $\mathit{PA}$ is close (in some appropriate sense) to $\mathit{UPA}$. In this paper, we first introduce the Generalized Noise Role Mining problem (GNRM) -- a generalization of the MinNoise Role Mining problem -- which we believe has considerable practical relevance. Extending work of Fomin et al., we show that GNRM is fixed parameter tractable, with parameter $r + k$, where $r$ is the number of roles in the solution and $k$ is the number of discrepancies between $\mathit{UPA}$ and the relation defined by the composition of $\mathit{UA}$ and $\mathit{PA}$. We further introduce a bi-objective optimization variant of GNRM, where we wish to minimize both $r$ and $k$ subject to upper bounds $r\le \bar{r}$ and $k\le \bar{k}$, where $\bar{r}$ and $\bar{k}$ are constants. We show that the Pareto front of this bi-objective optimization problem (BO-GNRM) can be computed in fixed-parameter tractable time with parameter $\bar{r}+\bar{k}$. We then report the results of our experimental work using the integer programming solver Gurobi to solve instances of BO-GNRM. Our key findings are that (a) we obtained strong support that Gurobi's performance is fixed-parameter tractable, (b) our results suggest that our techniques may be useful for role mining in practice, based on our experiments in the context of three well-known real-world authorization policies.
The Parameterized Complexity of Coordinated Motion Planning
Dec 16, 2023



In Coordinated Motion Planning (CMP), we are given a rectangular-grid on which $k$ robots occupy $k$ distinct starting gridpoints and need to reach $k$ distinct destination gridpoints. In each time step, any robot may move to a neighboring gridpoint or stay in its current gridpoint, provided that it does not collide with other robots. The goal is to compute a schedule for moving the $k$ robots to their destinations which minimizes a certain objective target - prominently the number of time steps in the schedule, i.e., the makespan, or the total length traveled by the robots. We refer to the problem arising from minimizing the former objective target as CMP-M and the latter as CMP-L. Both CMP-M and CMP-L are fundamental problems that were posed as the computational geometry challenge of SoCG 2021, and CMP also embodies the famous $(n^2-1)$-puzzle as a special case. In this paper, we settle the parameterized complexity of CMP-M and CMP-L with respect to their two most fundamental parameters: the number of robots, and the objective target. We develop a new approach to establish the fixed-parameter tractability of both problems under the former parameterization that relies on novel structural insights into optimal solutions to the problem. When parameterized by the objective target, we show that CMP-L remains fixed-parameter tractable while CMP-M becomes para-NP-hard. The latter result is noteworthy, not only because it improves the previously-known boundaries of intractability for the problem, but also because the underlying reduction allows us to establish - as a simpler case - the NP-hardness of the classical Vertex Disjoint and Edge Disjoint Paths problems with constant path-lengths on grids.
A Structural Complexity Analysis of Synchronous Dynamical Systems
Dec 12, 2023
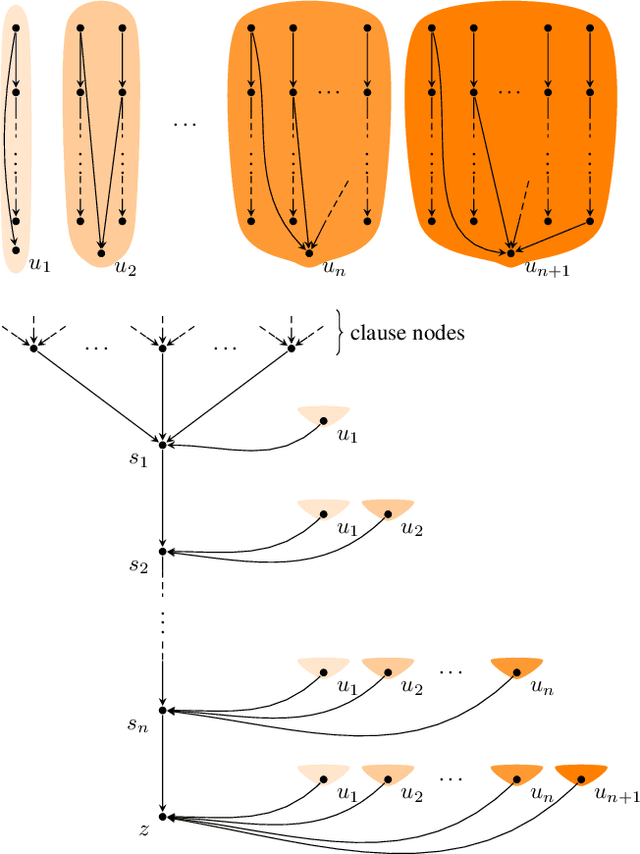
Synchronous dynamic systems are well-established models that have been used to capture a range of phenomena in networks, including opinion diffusion, spread of disease and product adoption. We study the three most notable problems in synchronous dynamic systems: whether the system will transition to a target configuration from a starting configuration, whether the system will reach convergence from a starting configuration, and whether the system is guaranteed to converge from every possible starting configuration. While all three problems were known to be intractable in the classical sense, we initiate the study of their exact boundaries of tractability from the perspective of structural parameters of the network by making use of the more fine-grained parameterized complexity paradigm. As our first result, we consider treewidth - as the most prominent and ubiquitous structural parameter - and show that all three problems remain intractable even on instances of constant treewidth. We complement this negative finding with fixed-parameter algorithms for the former two problems parameterized by treedepth, a well-studied restriction of treewidth. While it is possible to rule out a similar algorithm for convergence guarantee under treedepth, we conclude with a fixed-parameter algorithm for this last problem when parameterized by treedepth and the maximum in-degree.
The Complexity of Envy-Free Graph Cutting
Dec 12, 2023We consider the problem of fairly dividing a set of heterogeneous divisible resources among agents with different preferences. We focus on the setting where the resources correspond to the edges of a connected graph, every agent must be assigned a connected piece of this graph, and the fairness notion considered is the classical envy freeness. The problem is NP-complete, and we analyze its complexity with respect to two natural complexity measures: the number of agents and the number of edges in the graph. While the problem remains NP-hard even for instances with 2 agents, we provide a dichotomy characterizing the complexity of the problem when the number of agents is constant based on structural properties of the graph. For the latter case, we design a polynomial-time algorithm when the graph has a constant number of edges.
The Computational Complexity of Concise Hypersphere Classification
Dec 12, 2023Hypersphere classification is a classical and foundational method that can provide easy-to-process explanations for the classification of real-valued and binary data. However, obtaining an (ideally concise) explanation via hypersphere classification is much more difficult when dealing with binary data than real-valued data. In this paper, we perform the first complexity-theoretic study of the hypersphere classification problem for binary data. We use the fine-grained parameterized complexity paradigm to analyze the impact of structural properties that may be present in the input data as well as potential conciseness constraints. Our results include stronger lower bounds and new fixed-parameter algorithms for hypersphere classification of binary data, which can find an exact and concise explanation when one exists.
EPTAS for $k$-means Clustering of Affine Subspaces
Oct 19, 2020We consider a generalization of the fundamental $k$-means clustering for data with incomplete or corrupted entries. When data objects are represented by points in $\mathbb{R}^d$, a data point is said to be incomplete when some of its entries are missing or unspecified. An incomplete data point with at most $\Delta$ unspecified entries corresponds to an axis-parallel affine subspace of dimension at most $\Delta$, called a $\Delta$-point. Thus we seek a partition of $n$ input $\Delta$-points into $k$ clusters minimizing the $k$-means objective. For $\Delta=0$, when all coordinates of each point are specified, this is the usual $k$-means clustering. We give an algorithm that finds an $(1+ \epsilon)$-approximate solution in time $f(k,\epsilon, \Delta) \cdot n^2 \cdot d$ for some function $f$ of $k,\epsilon$, and $\Delta$ only.