 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Parameterized Theory of PAC Learning
Apr 27, 2023Probably Approximately Correct (i.e., PAC) learning is a core concept of sample complexity theory, and efficient PAC learnability is often seen as a natural counterpart to the class P in classical computational complexity. But while the nascent theory of parameterized complexity has allowed us to push beyond the P-NP ``dichotomy'' in classical computational complexity and identify the exact boundaries of tractability for numerous problems, there is no analogue in the domain of sample complexity that could push beyond efficient PAC learnability. As our core contribution, we fill this gap by developing a theory of parameterized PAC learning which allows us to shed new light on several recent PAC learning results that incorporated elements of parameterized complexity. Within the theory, we identify not one but two notions of fixed-parameter learnability that both form distinct counterparts to the class FPT -- the core concept at the center of the parameterized complexity paradigm -- and develop the machinery required to exclude fixed-parameter learnability. We then showcase the applications of this theory to identify refined boundaries of tractability for CNF and DNF learning as well as for a range of learning problems on graphs.
How to Find a Good Explanation for Clustering?
Dec 16, 2021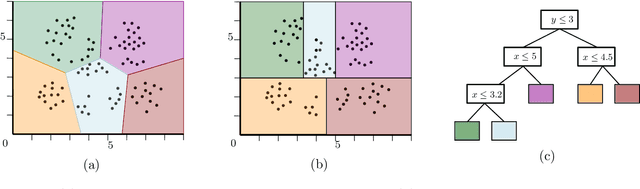

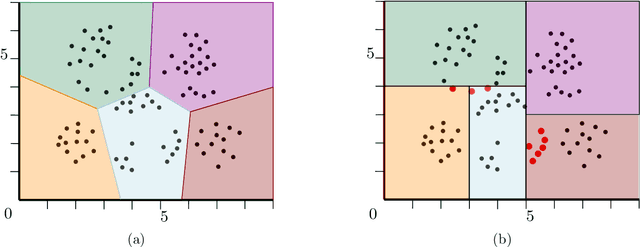
$k$-means and $k$-median clustering are powerful unsupervised machine learning techniques. However, due to complicated dependences on all the features, it is challenging to interpret the resulting cluster assignments. Moshkovitz, Dasgupta, Rashtchian, and Frost [ICML 2020] proposed an elegant model of explainable $k$-means and $k$-median clustering. In this model, a decision tree with $k$ leaves provides a straightforward characterization of the data set into clusters. We study two natural algorithmic questions about explainable clustering. (1) For a given clustering, how to find the "best explanation" by using a decision tree with $k$ leaves? (2) For a given set of points, how to find a decision tree with $k$ leaves minimizing the $k$-means/median objective of the resulting explainable clustering? To address the first question, we introduce a new model of explainable clustering. Our model, inspired by the notion of outliers in robust statistics, is the following. We are seeking a small number of points (outliers) whose removal makes the existing clustering well-explainable. For addressing the second question, we initiate the study of the model of Moshkovitz et al. from the perspective of multivariate complexity. Our rigorous algorithmic analysis sheds some light on the influence of parameters like the input size, dimension of the data, the number of outliers, the number of clusters, and the approximation ratio, on the computational complexity of explainable clustering.
EPTAS for $k$-means Clustering of Affine Subspaces
Oct 19, 2020We consider a generalization of the fundamental $k$-means clustering for data with incomplete or corrupted entries. When data objects are represented by points in $\mathbb{R}^d$, a data point is said to be incomplete when some of its entries are missing or unspecified. An incomplete data point with at most $\Delta$ unspecified entries corresponds to an axis-parallel affine subspace of dimension at most $\Delta$, called a $\Delta$-point. Thus we seek a partition of $n$ input $\Delta$-points into $k$ clusters minimizing the $k$-means objective. For $\Delta=0$, when all coordinates of each point are specified, this is the usual $k$-means clustering. We give an algorithm that finds an $(1+ \epsilon)$-approximate solution in time $f(k,\epsilon, \Delta) \cdot n^2 \cdot d$ for some function $f$ of $k,\epsilon$, and $\Delta$ only.
On Coresets for Fair Clustering in Metric and Euclidean Spaces and Their Applications
Jul 20, 2020



Fair clustering is a constrained variant of clustering where the goal is to partition a set of colored points, such that the fraction of points of any color in every cluster is more or less equal to the fraction of points of this color in the dataset. This variant was recently introduced by Chierichetti et al. [NeurIPS, 2017] in a seminal work and became widely popular in the clustering literature. In this paper, we propose a new construction of coresets for fair clustering based on random sampling. The new construction allows us to obtain the first coreset for fair clustering in general metric spaces. For Euclidean spaces, we obtain the first coreset whose size does not depend exponentially on the dimension. Our coreset results solve open questions proposed by Schmidt et al. [WAOA, 2019] and Huang et al. [NeurIPS, 2019]. The new coreset construction helps to design several new approximation and streaming algorithms. In particular, we obtain the first true constant-approximation algorithm for metric fair clustering, whose running time is fixed-parameter tractable (FPT). In the Euclidean case, we derive the first $(1+\epsilon)$-approximation algorithm for fair clustering whose time complexity is near-linear and does not depend exponentially on the dimension of the space. Besides, our coreset construction scheme is fairly general and gives rise to coresets for a wide range of constrained clustering problems. This leads to improved constant-approximations for these problems in general metrics and near-linear time $(1+\epsilon)$-approximations in the Euclidean metric.
Refined Complexity of PCA with Outliers
May 10, 2019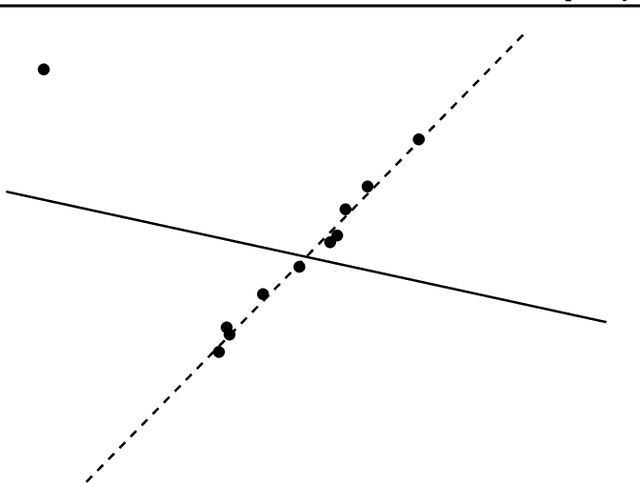
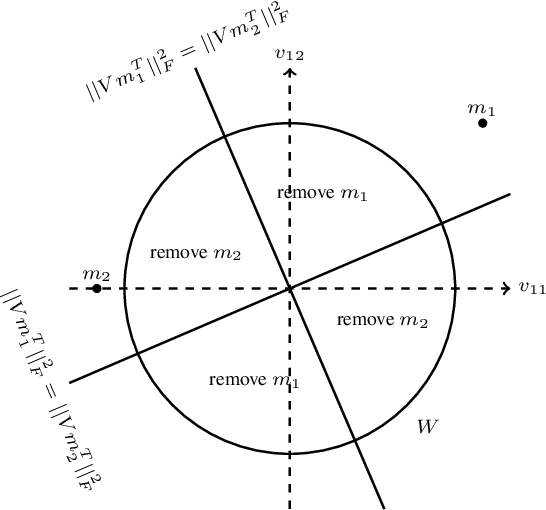
Principal component analysis (PCA) is one of the most fundamental procedures in exploratory data analysis and is the basic step in applications ranging from quantitative finance and bioinformatics to image analysis and neuroscience. However, it is well-documented that the applicability of PCA in many real scenarios could be constrained by an "immune deficiency" to outliers such as corrupted observations. We consider the following algorithmic question about the PCA with outliers. For a set of $n$ points in $\mathbb{R}^{d}$, how to learn a subset of points, say 1% of the total number of points, such that the remaining part of the points is best fit into some unknown $r$-dimensional subspace? We provide a rigorous algorithmic analysis of the problem. We show that the problem is solvable in time $n^{O(d^2)}$. In particular, for constant dimension the problem is solvable in polynomial time. We complement the algorithmic result by the lower bound, showing that unless Exponential Time Hypothesis fails, in time $f(d)n^{o(d)}$, for any function $f$ of $d$, it is impossible not only to solve the problem exactly but even to approximate it within a constant factor.