 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Find a Good Explanation for Clustering?
Dec 16, 2021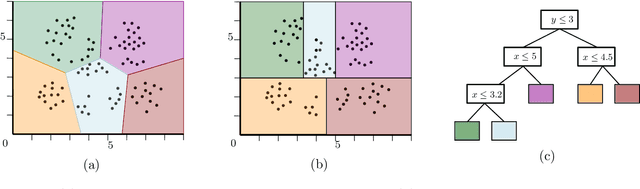

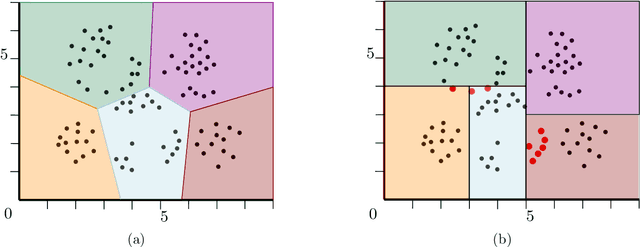
$k$-means and $k$-median clustering are powerful unsupervised machine learning techniques. However, due to complicated dependences on all the features, it is challenging to interpret the resulting cluster assignments. Moshkovitz, Dasgupta, Rashtchian, and Frost [ICML 2020] proposed an elegant model of explainable $k$-means and $k$-median clustering. In this model, a decision tree with $k$ leaves provides a straightforward characterization of the data set into clusters. We study two natural algorithmic questions about explainable clustering. (1) For a given clustering, how to find the "best explanation" by using a decision tree with $k$ leaves? (2) For a given set of points, how to find a decision tree with $k$ leaves minimizing the $k$-means/median objective of the resulting explainable clustering? To address the first question, we introduce a new model of explainable clustering. Our model, inspired by the notion of outliers in robust statistics, is the following. We are seeking a small number of points (outliers) whose removal makes the existing clustering well-explainable. For addressing the second question, we initiate the study of the model of Moshkovitz et al. from the perspective of multivariate complexity. Our rigorous algorithmic analysis sheds some light on the influence of parameters like the input size, dimension of the data, the number of outliers, the number of clusters, and the approximation ratio, on the computational complexity of explainable clustering.
EPTAS for $k$-means Clustering of Affine Subspaces
Oct 19, 2020We consider a generalization of the fundamental $k$-means clustering for data with incomplete or corrupted entries. When data objects are represented by points in $\mathbb{R}^d$, a data point is said to be incomplete when some of its entries are missing or unspecified. An incomplete data point with at most $\Delta$ unspecified entries corresponds to an axis-parallel affine subspace of dimension at most $\Delta$, called a $\Delta$-point. Thus we seek a partition of $n$ input $\Delta$-points into $k$ clusters minimizing the $k$-means objective. For $\Delta=0$, when all coordinates of each point are specified, this is the usual $k$-means clustering. We give an algorithm that finds an $(1+ \epsilon)$-approximate solution in time $f(k,\epsilon, \Delta) \cdot n^2 \cdot d$ for some function $f$ of $k,\epsilon$, and $\Delta$ only.