 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBi-objective Optimization in Role Mining
Mar 25, 2024



Role mining is a technique used to derive a role-based authorization policy from an existing policy. Given a set of users $U$, a set of permissions $P$ and a user-permission authorization relation $\mahtit{UPA}\subseteq U\times P$, a role mining algorithm seeks to compute a set of roles $R$, a user-role authorization relation $\mathit{UA}\subseteq U\times R$ and a permission-role authorization relation $\mathit{PA}\subseteq R\times P$, such that the composition of $\mathit{UA}$ and $\mathit{PA}$ is close (in some appropriate sense) to $\mathit{UPA}$. In this paper, we first introduce the Generalized Noise Role Mining problem (GNRM) -- a generalization of the MinNoise Role Mining problem -- which we believe has considerable practical relevance. Extending work of Fomin et al., we show that GNRM is fixed parameter tractable, with parameter $r + k$, where $r$ is the number of roles in the solution and $k$ is the number of discrepancies between $\mathit{UPA}$ and the relation defined by the composition of $\mathit{UA}$ and $\mathit{PA}$. We further introduce a bi-objective optimization variant of GNRM, where we wish to minimize both $r$ and $k$ subject to upper bounds $r\le \bar{r}$ and $k\le \bar{k}$, where $\bar{r}$ and $\bar{k}$ are constants. We show that the Pareto front of this bi-objective optimization problem (BO-GNRM) can be computed in fixed-parameter tractable time with parameter $\bar{r}+\bar{k}$. We then report the results of our experimental work using the integer programming solver Gurobi to solve instances of BO-GNRM. Our key findings are that (a) we obtained strong support that Gurobi's performance is fixed-parameter tractable, (b) our results suggest that our techniques may be useful for role mining in practice, based on our experiments in the context of three well-known real-world authorization policies.
Exploitation Strategies in Conditional Markov Chain Search: A case study on the three-index assignment problem
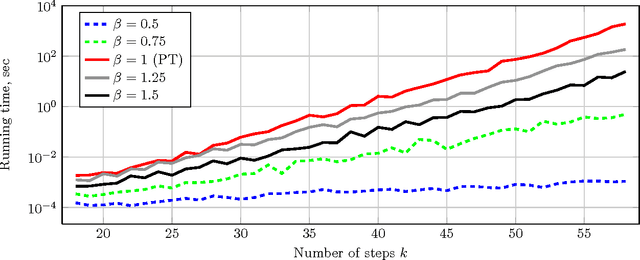
Jan 30, 2024The Conditional Markov Chain Search (CMCS) is a framework for automated design of metaheuristics for discrete combinatorial optimisation problems. Given a set of algorithmic components such as hill climbers and mutations, CMCS decides in which order to apply those components. The decisions are dictated by the CMCS configuration that can be learnt offline. CMCS does not have an acceptance criterion; any moves are accepted by the framework. As a result, it is particularly good in exploration but is not as good at exploitation. In this study, we explore several extensions of the framework to improve its exploitation abilities. To perform a computational study, we applied the framework to the three-index assignment problem. The results of our experiments showed that a two-stage CMCS is indeed superior to a single-stage CMCS.
Solving the Workflow Satisfiability Problem using General Purpose Solvers
May 07, 2021

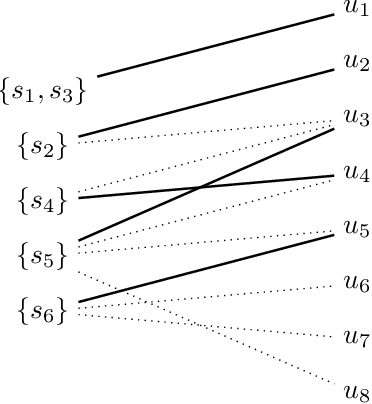
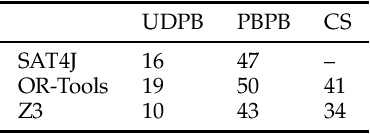
The workflow satisfiability problem (WSP) is a well-studied problem in access control seeking allocation of authorised users to every step of the workflow, subject to workflow specification constraints. It was noticed that the number $k$ of steps is typically small compared to the number of users in the real-world instances of WSP; therefore $k$ is considered as the parameter in WSP parametrised complexity research. While WSP in general was shown to be W[1]-hard, WSP restricted to a special case of user-independent (UI) constraints is fixed-parameter tractable (FPT). However, restriction to the UI constraints might be impractical. To efficiently handle non-UI constraints, we introduce the notion of branching factor of a constraint. As long as the branching factors of the constraints are relatively small and the number of non-UI constraints is reasonable, WSP can be solved in FPT time. Extending the results from Karapetyan et al. (2019), we demonstrate that general-purpose solvers are capable of achieving FPT-like performance on WSP with arbitrary constraints when used with appropriate formulations. This enables one to tackle most of practical WSP instances. While important on its own, we hope that this result will also motivate researchers to look for FPT-aware formulations of other FPT problems.
Conditional Markov Chain Search for the Generalised Travelling Salesman Problem for Warehouse Order Picking
Aug 09, 2019
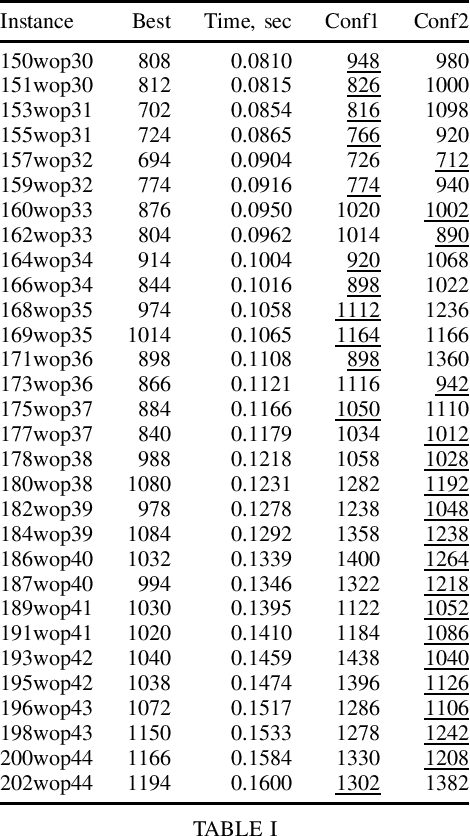
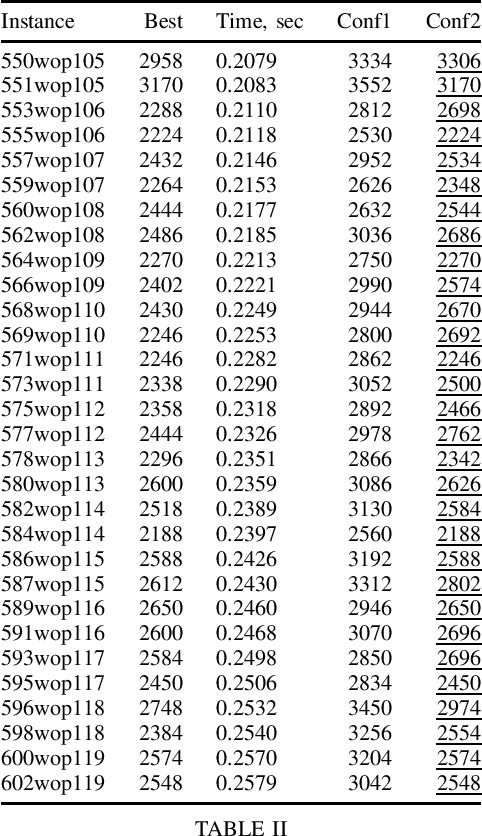
The Generalised Travelling Salesman Problem (GTSP) is a well-known problem that, among other applications, arises in warehouse order picking, where each stock is distributed between several locations -- a typical approach in large modern warehouses. However, the instances commonly used in the literature have a completely different structure, and the methods are designed with those instances in mind. In this paper, we give a new pseudo-random instance generator that reflects the warehouse order picking and publish new benchmark testbeds. We also use the Conditional Markov Chain Search framework to automatically generate new GTSP metaheuristics trained specifically for warehouse order picking. Finally, we report the computational results of our metaheuristics to enable further competition between solvers.
Hyperparameter Optimisation with Early Termination of Poor Performers
Aug 06, 2019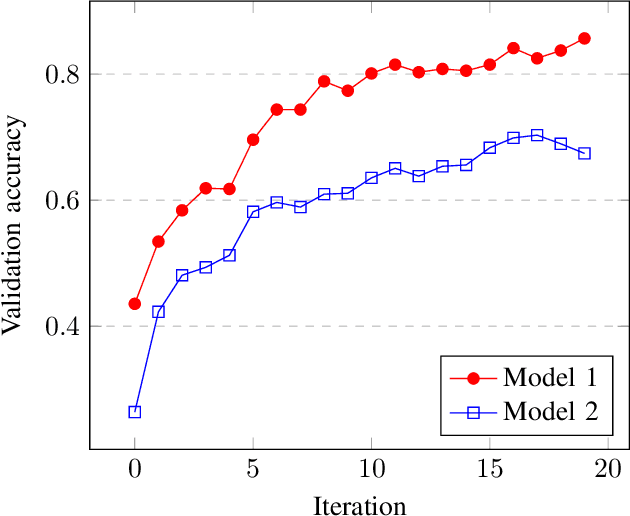
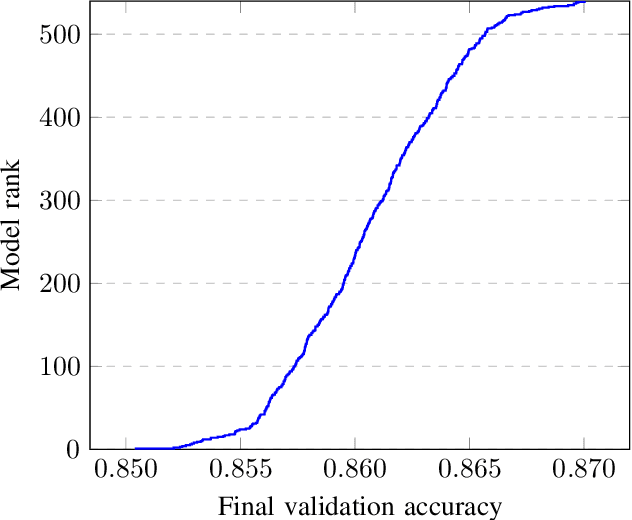
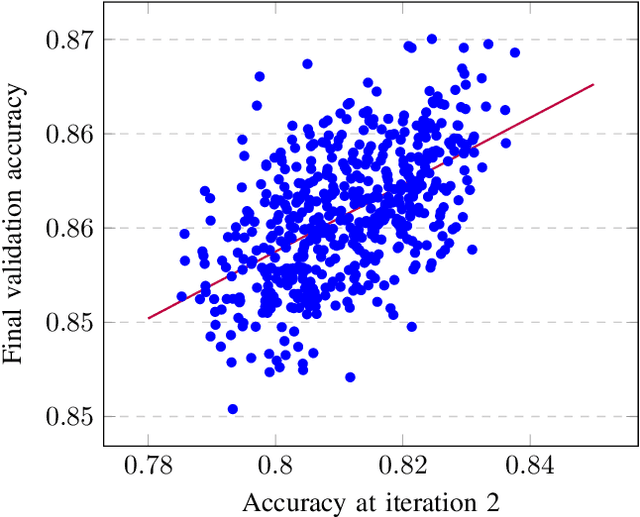
It is typical for a machine learning system to have numerous hyperparameters that affect its learning rate and prediction quality. Finding a good combination of the hyperparameters is, however, a challenging job. This is mainly because evaluation of each combination is extremely expensive computationally; indeed, training a machine learning system on real data with just a single combination of hyperparameters usually takes hours or even days. In this paper, we address this challenge by trying to predict the performance of the machine learning system with a given combination of hyperparameters without completing the expensive learning process. Instead, we terminate the training process at an early stage, collect the model performance data and use it to predict which of the combinations of hyperparameters is most promising. Our preliminary experiments show that such a prediction improves the performance of the commonly used random search approach.
Algorithm Configuration: Learning policies for the quick termination of poor performers
Mar 26, 2018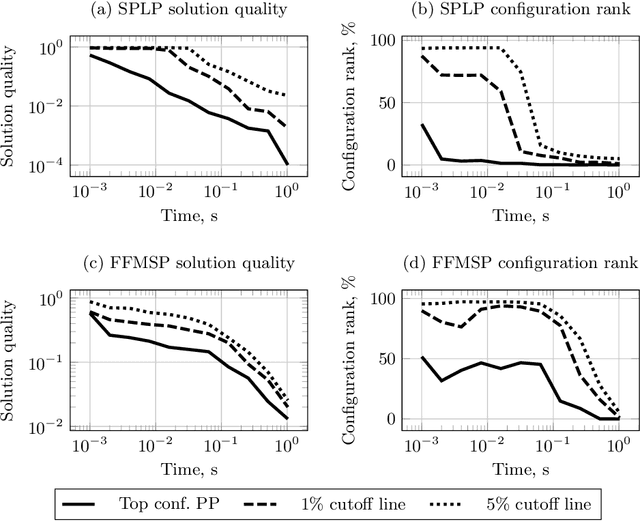
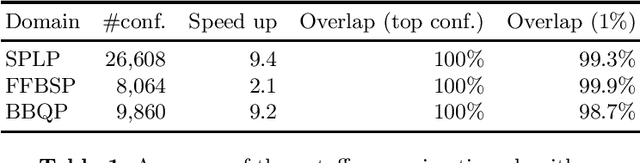
One way to speed up the algorithm configuration task is to use short runs instead of long runs as much as possible, but without discarding the configurations that eventually do well on the long runs. We consider the problem of selecting the top performing configurations of the Conditional Markov Chain Search (CMCS), a general algorithm schema that includes, for examples, VNS. We investigate how the structure of performance on short tests links with those on long tests, showing that significant differences arise between test domains. We propose a "performance envelope" method to exploit the links; that learns when runs should be terminated, but that automatically adapts to the domain.
Pattern-Based Approach to the Workflow Satisfiability Problem with User-Independent Constraints
Feb 22, 2018
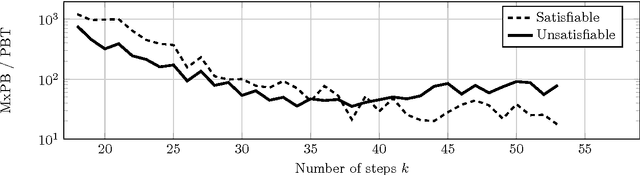
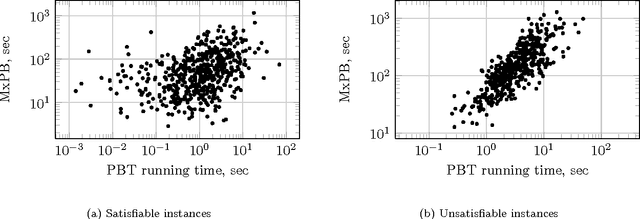
The fixed parameter tractable (FPT) approach is a powerful tool in tackling computationally hard problems. In this paper, we link FPT results to classic artificial intelligence (AI) techniques to show how they complement each other. Specifically, we consider the workflow satisfiability problem (WSP) which asks whether there exists an assignment of authorised users to the steps in a workflow specification, subject to certain constraints on the assignment. It was shown by Cohen et al. (JAIR 2014) that WSP restricted to the class of user-independent constraints (UI), covering many practical cases, admits FPT algorithms, i.e. can be solved in time exponential only in the number of steps $k$ and polynomial in the number of users $n$. Since usually $k \ll n$ in WSP, such FPT algorithms are of great practical interest as they significantly extend the size of the problem that can be routinely solved. We give a new view of the FPT nature of the WSP with UI constraints, showing that it decomposes the problem into two levels. Exploiting this two-level split, we develop a new FPT algorithm that is by many orders of magnitude faster than the previous state-of-the-art WSP algorithm; and it also has only polynomial space complexity whereas the old algorithm takes memory exponential in $k$, which limits its application. We also provide a new pseudo-boolean (PB) formulation of the WSP with UI constraints which exploits this new decomposition of the problem into two levels. Our experiments show that efficiency of solving this new PB formulation of the problem by a general purpose PB solver can be close to the bespoke FPT algorithm, which raises the potential of using general purpose solvers to tackle FPT problems efficiently. We also study the computational performance of various algorithms to complement the overly-pessimistic worst-case analysis that is usually done in FPT studies.
Conditional Markov Chain Search for the Simple Plant Location Problem improves upper bounds on twelve Körkel-Ghosh instances
Nov 16, 2017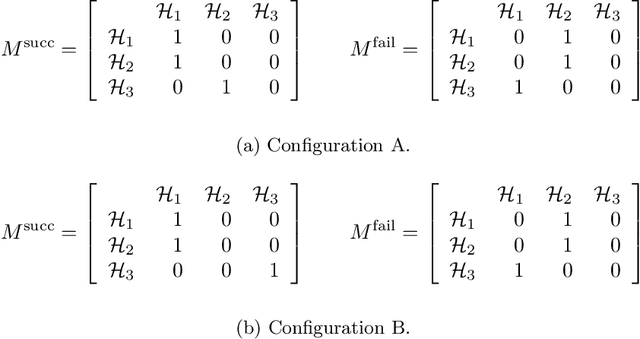

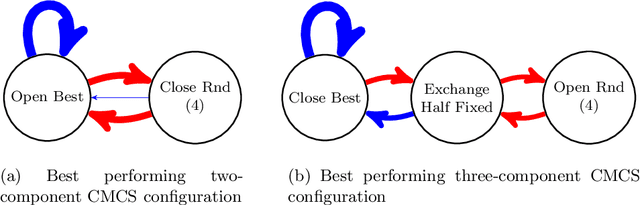
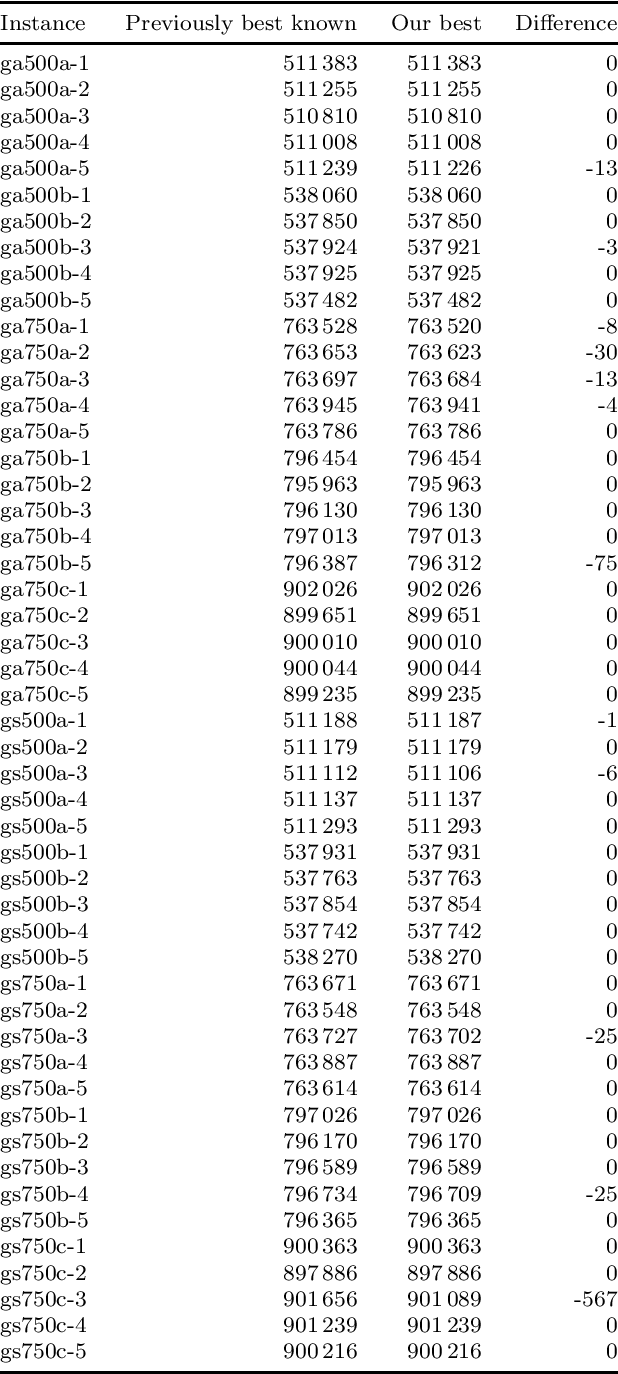
We address a family of hard benchmark instances for the Simple Plant Location Problem (also known as the Uncapacitated Facility Location Problem). The recent attempt by Fischetti et al. to tackle the K\"orkel-Ghosh instances resulted in seven new optimal solutions and 22 improved upper bounds. We use automated generation of heuristics to obtain a new algorithm for the Simple Plant Location Problem. In our experiments, our new algorithm matched all the previous best known and optimal solutions, and further improved 12 upper bounds, all within shorter time budgets compared to the previous efforts. Our algorithm design process is split into two phases: (i) development of algorithmic components such as local search procedures and mutation operators, and (ii) composition of a metaheuristic from the available components. Phase (i) requires human expertise and often can be completed by implementing several simple domain-specific routines known from the literature. Phase (ii) is entirely automated by employing the Conditional Markov Chain Search (CMCS) framework. In CMCS, a metaheuristic is flexibly defined by a set of parameters, called configuration. Then the process of composition of a metaheuristic from the algorithmic components is reduced to an optimisation problem seeking the best performing CMCS configuration. We discuss the problem of comparing configurations, and propose a new efficient technique to select the best performing configuration from a large set. To employ this method, we restrict the original CMCS to a simple deterministic case that leaves us with a finite and manageable number of meaningful configurations.
Markov Chain methods for the bipartite Boolean quadratic programming problem
Oct 24, 2016
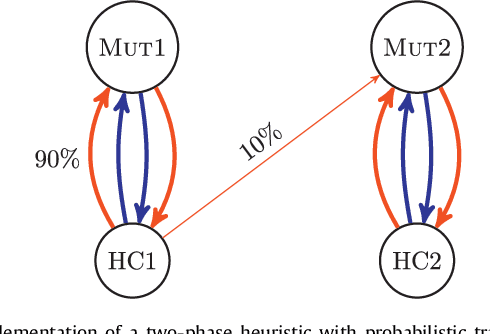
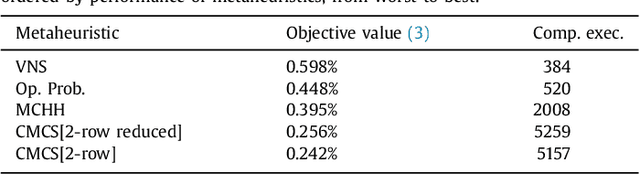
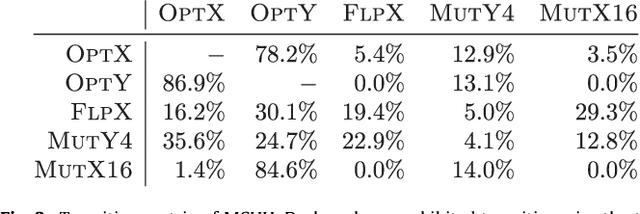
We study the Bipartite Boolean Quadratic Programming Problem (BBQP) which is an extension of the well known Boolean Quadratic Programming Problem (BQP). Applications of the BBQP include mining discrete patterns from binary data, approximating matrices by rank-one binary matrices, computing the cut-norm of a matrix, and solving optimisation problems such as maximum weight biclique, bipartite maximum weight cut, maximum weight induced sub-graph of a bipartite graph, etc. For the BBQP, we first present several algorithmic components, specifically, hill climbers and mutations, and then show how to combine them in a high-performance metaheuristic. Instead of hand-tuning a standard metaheuristic to test the efficiency of the hybrid of the components, we chose to use an automated generation of a multi-component metaheuristic to save human time, and also improve objectivity in the analysis and comparisons of components. For this we designed a new metaheuristic schema which we call Conditional Markov Chain Search (CMCS). We show that CMCS is flexible enough to model several standard metaheuristics; this flexibility is controlled by multiple numeric parameters, and so is convenient for automated generation. We study the configurations revealed by our approach and show that the best of them outperforms the previous state-of-the-art BBQP algorithm by several orders of magnitude. In our experiments we use benchmark instances introduced in the preliminary version of this paper and described here, which have already become the de facto standard in the BBQP literature.
Combining Monte-Carlo and Hyper-heuristic methods for the Multi-mode Resource-constrained Multi-project Scheduling Problem
Sep 08, 2016
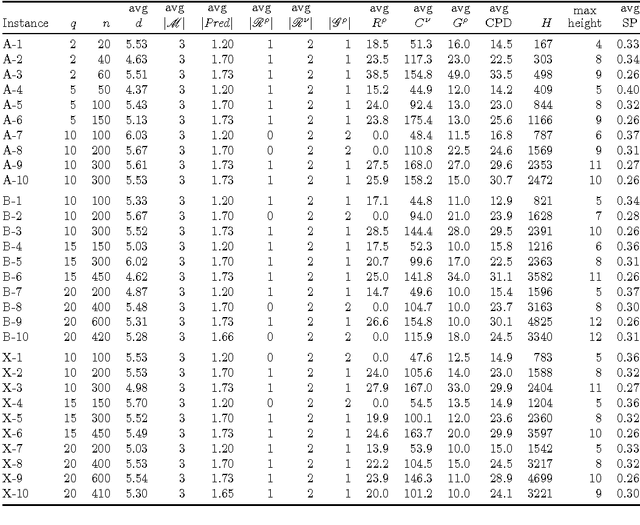
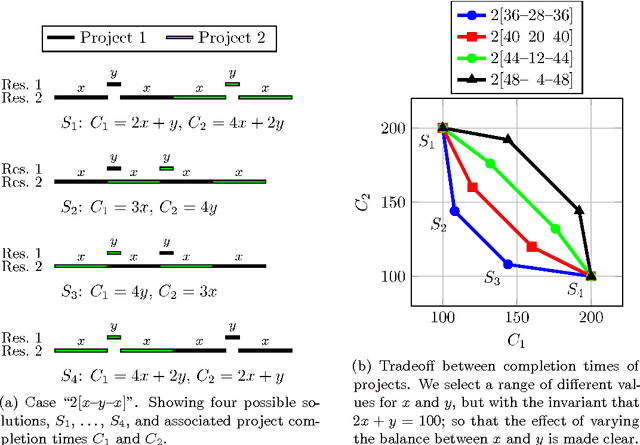

Multi-mode resource and precedence-constrained project scheduling is a well-known challenging real-world optimisation problem. An important variant of the problem requires scheduling of activities for multiple projects considering availability of local and global resources while respecting a range of constraints. A critical aspect of the benchmarks addressed in this paper is that the primary objective is to minimise the sum of the project completion times, with the usual makespan minimisation as a secondary objective. We observe that this leads to an expected different overall structure of good solutions and discuss the effects this has on the algorithm design. This paper presents a carefully designed hybrid of Monte-Carlo tree search, novel neighbourhood moves, memetic algorithms, and hyper-heuristic methods. The implementation is also engineered to increase the speed with which iterations are performed, and to exploit the computing power of multicore machines. Empirical evaluation shows that the resulting information-sharing multi-component algorithm significantly outperforms other solvers on a set of "hidden" instances, i.e. instances not available at the algorithm design phase.