 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesizing Multi-Class Surgical Datasets with Anatomy-Aware Diffusion Models
Oct 10, 2024In computer-assisted surgery, automatically recognizing anatomical organs is crucial for understanding the surgical scene and providing intraoperative assistance. While machine learning models can identify such structures, their deployment is hindered by the need for labeled, diverse surgical datasets with anatomical annotations. Labeling multiple classes (i.e., organs) in a surgical scene is time-intensive, requiring medical experts. Although synthetically generated images can enhance segmentation performance, maintaining both organ structure and texture during generation is challenging. We introduce a multi-stage approach using diffusion models to generate multi-class surgical datasets with annotations. Our framework improves anatomy awareness by training organ specific models with an inpainting objective guided by binary segmentation masks. The organs are generated with an inference pipeline using pre-trained ControlNet to maintain the organ structure. The synthetic multi-class datasets are constructed through an image composition step, ensuring structural and textural consistency. This versatile approach allows the generation of multi-class datasets from real binary datasets and simulated surgical masks. We thoroughly evaluate the generated datasets on image quality and downstream segmentation, achieving a $15\%$ improvement in segmentation scores when combined with real images. Our codebase https://gitlab.com/nct_tso_public/muli-class-image-synthesis
PitVis-2023 Challenge: Workflow Recognition in videos of Endoscopic Pituitary Surgery
Sep 02, 2024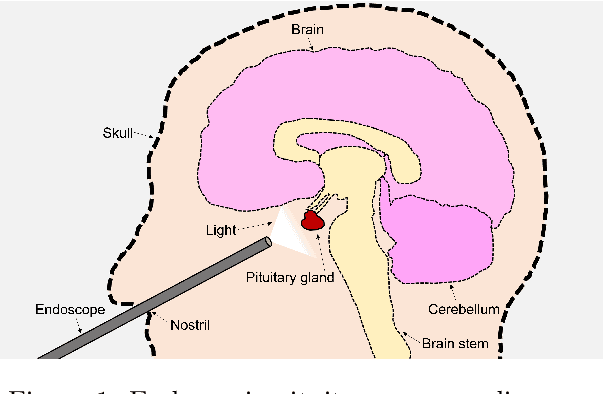

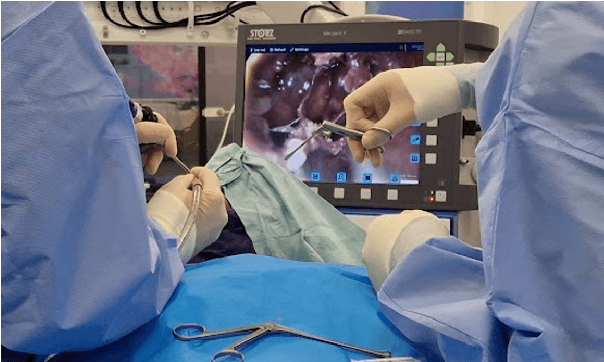
The field of computer vision applied to videos of minimally invasive surgery is ever-growing. Workflow recognition pertains to the automated recognition of various aspects of a surgery: including which surgical steps are performed; and which surgical instruments are used. This information can later be used to assist clinicians when learning the surgery; during live surgery; and when writing operation notes. The Pituitary Vision (PitVis) 2023 Challenge tasks the community to step and instrument recognition in videos of endoscopic pituitary surgery. This is a unique task when compared to other minimally invasive surgeries due to the smaller working space, which limits and distorts vision; and higher frequency of instrument and step switching, which requires more precise model predictions. Participants were provided with 25-videos, with results presented at the MICCAI-2023 conference as part of the Endoscopic Vision 2023 Challenge in Vancouver, Canada, on 08-Oct-2023. There were 18-submissions from 9-teams across 6-countries, using a variety of deep learning models. A commonality between the top performing models was incorporating spatio-temporal and multi-task methods, with greater than 50% and 10% macro-F1-score improvement over purely spacial single-task models in step and instrument recognition respectively. The PitVis-2023 Challenge therefore demonstrates state-of-the-art computer vision models in minimally invasive surgery are transferable to a new dataset, with surgery specific techniques used to enhance performance, progressing the field further. Benchmark results are provided in the paper, and the dataset is publicly available at: https://doi.org/10.5522/04/26531686.
SurgicaL-CD: Generating Surgical Images via Unpaired Image Translation with Latent Consistency Diffusion Models
Aug 19, 2024Computer-assisted surgery (CAS) systems are designed to assist surgeons during procedures, thereby reducing complications and enhancing patient care. Training machine learning models for these systems requires a large corpus of annotated datasets, which is challenging to obtain in the surgical domain due to patient privacy concerns and the significant labeling effort required from doctors. Previous methods have explored unpaired image translation using generative models to create realistic surgical images from simulations. However, these approaches have struggled to produce high-quality, diverse surgical images. In this work, we introduce \emph{SurgicaL-CD}, a consistency-distilled diffusion method to generate realistic surgical images with only a few sampling steps without paired data. We evaluate our approach on three datasets, assessing the generated images in terms of quality and utility as downstream training datasets. Our results demonstrate that our method outperforms GANs and diffusion-based approaches. Our code is available at \url{https://gitlab.com/nct_tso_public/gan2diffusion}.
Exploring Semantic Consistency in Unpaired Image Translation to Generate Data for Surgical Applications
Sep 11, 2023In surgical computer vision applications, obtaining labeled training data is challenging due to data-privacy concerns and the need for expert annotation. Unpaired image-to-image translation techniques have been explored to automatically generate large annotated datasets by translating synthetic images to the realistic domain. However, preserving the structure and semantic consistency between the input and translated images presents significant challenges, mainly when there is a distributional mismatch in the semantic characteristics of the domains. This study empirically investigates unpaired image translation methods for generating suitable data in surgical applications, explicitly focusing on semantic consistency. We extensively evaluate various state-of-the-art image translation models on two challenging surgical datasets and downstream semantic segmentation tasks. We find that a simple combination of structural-similarity loss and contrastive learning yields the most promising results. Quantitatively, we show that the data generated with this approach yields higher semantic consistency and can be used more effectively as training data.
TUNeS: A Temporal U-Net with Self-Attention for Video-based Surgical Phase Recognition
Jul 19, 2023



To enable context-aware computer assistance in the operating room of the future, cognitive systems need to understand automatically which surgical phase is being performed by the medical team. The primary source of information for surgical phase recognition is typically video, which presents two challenges: extracting meaningful features from the video stream and effectively modeling temporal information in the sequence of visual features. For temporal modeling, attention mechanisms have gained popularity due to their ability to capture long-range dependencies. In this paper, we explore design choices for attention in existing temporal models for surgical phase recognition and propose a novel approach that does not resort to local attention or regularization of attention weights: TUNeS is an efficient and simple temporal model that incorporates self-attention at the coarsest stage of a U-Net-like structure. In addition, we propose to train the feature extractor, a standard CNN, together with an LSTM on preferably long video segments, i.e., with long temporal context. In our experiments, all temporal models performed better on top of feature extractors that were trained with longer temporal context. On top of these contextualized features, TUNeS achieves state-of-the-art results on Cholec80.
Metrics Matter in Surgical Phase Recognition
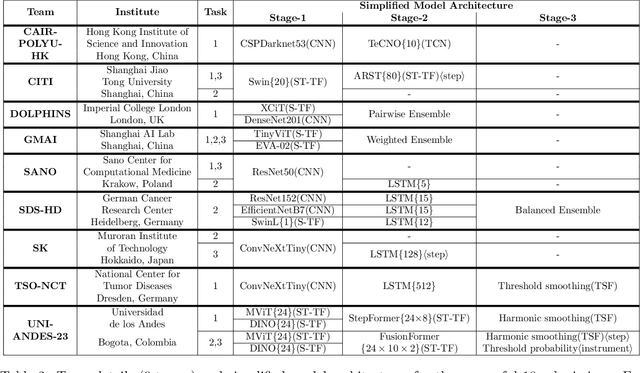
May 23, 2023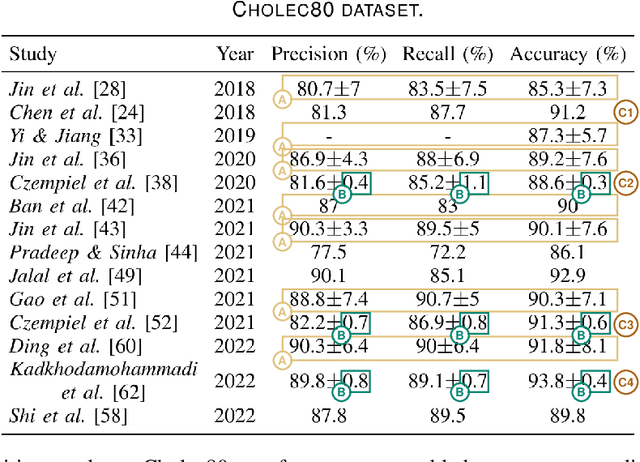



Surgical phase recognition is a basic component for different context-aware applications in computer- and robot-assisted surgery. In recent years, several methods for automatic surgical phase recognition have been proposed, showing promising results. However, a meaningful comparison of these methods is difficult due to differences in the evaluation process and incomplete reporting of evaluation details. In particular, the details of metric computation can vary widely between different studies. To raise awareness of potential inconsistencies, this paper summarizes common deviations in the evaluation of phase recognition algorithms on the Cholec80 benchmark. In addition, a structured overview of previously reported evaluation results on Cholec80 is provided, taking known differences in evaluation protocols into account. Greater attention to evaluation details could help achieve more consistent and comparable results on the surgical phase recognition task, leading to more reliable conclusions about advancements in the field and, finally, translation into clinical practice.
On the Pitfalls of Batch Normalization for End-to-End Video Learning: A Study on Surgical Workflow Analysis
Mar 15, 2022


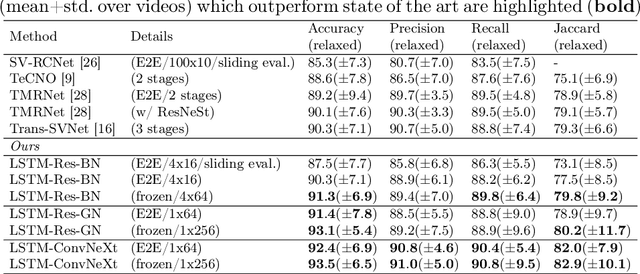
Batch Normalization's (BN) unique property of depending on other samples in a batch is known to cause problems in several tasks, including sequential modeling, and has led to the use of alternatives in these fields. In video learning, however, these problems are less studied, despite the ubiquitous use of BN in CNNs for visual feature extraction. We argue that BN's properties create major obstacles for training CNNs and temporal models end to end in video tasks. Yet, end-to-end learning seems preferable in specialized domains such as surgical workflow analysis, which lack well-pretrained feature extractors. While previous work in surgical workflow analysis has avoided BN-related issues through complex, multi-stage learning procedures, we show that even simple, end-to-end CNN-LSTMs can outperform the state of the art when CNNs without BN are used. Moreover, we analyze in detail when BN-related issues occur, including a "cheating" phenomenon in surgical anticipation tasks. We hope that a deeper understanding of BN's limitations and a reconsideration of end-to-end approaches can be beneficial for future research in surgical workflow analysis and general video learning.
Long-Term Temporally Consistent Unpaired Video Translation from Simulated Surgical 3D Data
Mar 31, 2021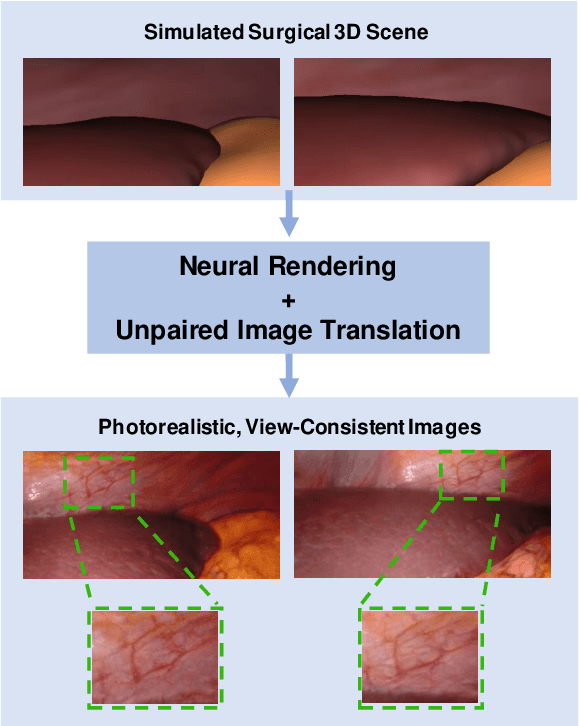
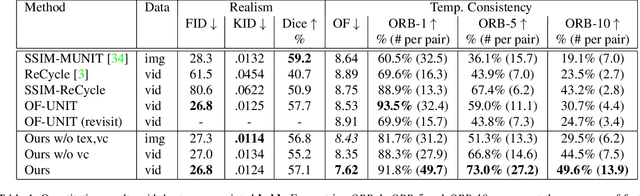
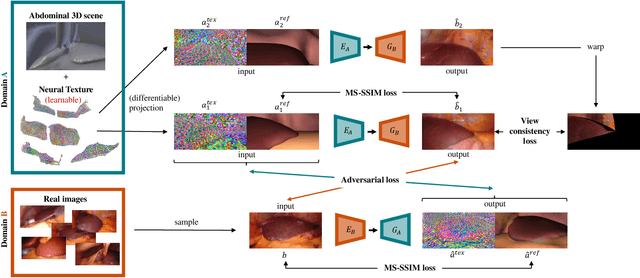
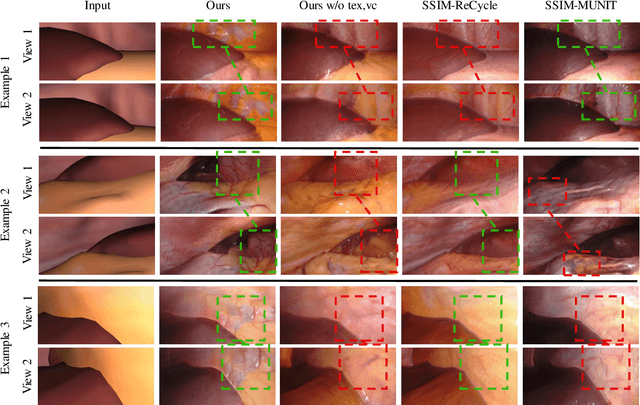
Research in unpaired video translation has mainly focused on short-term temporal consistency by conditioning on neighboring frames. However for transfer from simulated to photorealistic sequences, available information on the underlying geometry offers potential for achieving global consistency across views. We propose a novel approach which combines unpaired image translation with neural rendering to transfer simulated to photorealistic surgical abdominal scenes. By introducing global learnable textures and a lighting-invariant view-consistency loss, our method produces consistent translations of arbitrary views and thus enables long-term consistent video synthesis. We design and test our model to generate video sequences from minimally-invasive surgical abdominal scenes. Because labeled data is often limited in this domain, photorealistic data where ground truth information from the simulated domain is preserved is especially relevant. By extending existing image-based methods to view-consistent videos, we aim to impact the applicability of simulated training and evaluation environments for surgical applications. Code and data will be made publicly available soon.
Rethinking Anticipation Tasks: Uncertainty-aware Anticipation of Sparse Surgical Instrument Usage for Context-aware Assistance
Jul 16, 2020
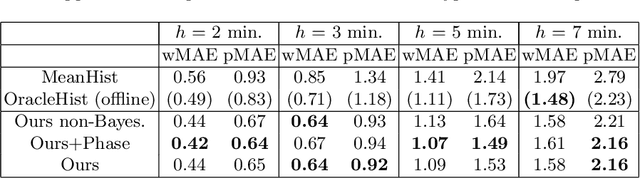
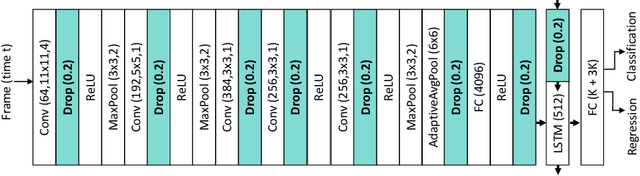
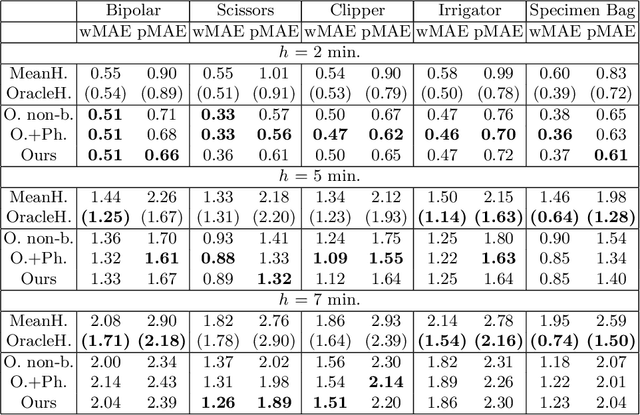
Intra-operative anticipation of instrument usage is a necessary component for context-aware assistance in surgery, e.g. for instrument preparation or semi-automation of robotic tasks. However, the sparsity of instrument occurrences in long videos poses a challenge. Current approaches are limited as they assume knowledge on the timing of future actions or require dense temporal segmentations during training and inference. We propose a novel learning task for anticipation of instrument usage in laparoscopic videos that overcomes these limitations. During training, only sparse instrument annotations are required and inference is done solely on image data. We train a probabilistic model to address the uncertainty associated with future events. Our approach outperforms several baselines and is competitive to a variant using richer annotations. We demonstrate the model's ability to quantify task-relevant uncertainties. To the best of our knowledge, we are the first to propose a method for anticipating instruments in surgery.
Unsupervised Temporal Video Segmentation as an Auxiliary Task for Predicting the Remaining Surgery Duration
Feb 26, 2020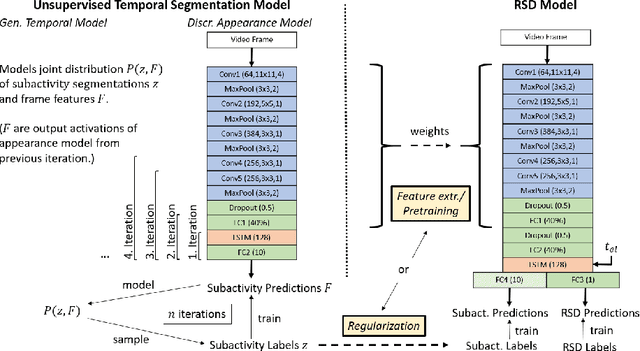
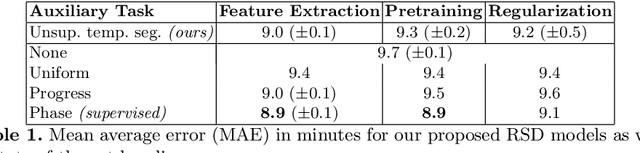

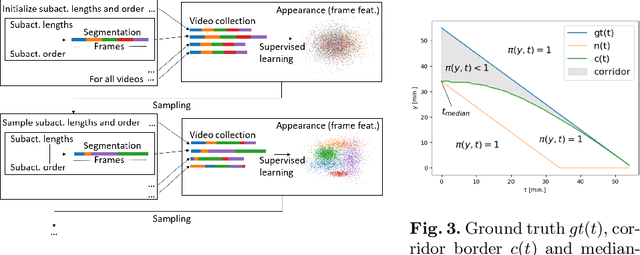
Estimating the remaining surgery duration (RSD) during surgical procedures can be useful for OR planning and anesthesia dose estimation. With the recent success of deep learning-based methods in computer vision, several neural network approaches have been proposed for fully automatic RSD prediction based solely on visual data from the endoscopic camera. We investigate whether RSD prediction can be improved using unsupervised temporal video segmentation as an auxiliary learning task. As opposed to previous work, which presented supervised surgical phase recognition as auxiliary task, we avoid the need for manual annotations by proposing a similar but unsupervised learning objective which clusters video sequences into temporally coherent segments. In multiple experimental setups, results obtained by learning the auxiliary task are incorporated into a deep RSD model through feature extraction, pretraining or regularization. Further, we propose a novel loss function for RSD training which attempts to counteract unfavorable characteristics of the RSD ground truth. Using our unsupervised method as an auxiliary task for RSD training, we outperform other self-supervised methods and are comparable to the supervised state-of-the-art. Combined with the novel RSD loss, we slightly outperform the supervised approach.