 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePIVOTS: Aligning unseen Structures using Preoperative to Intraoperative Volume-To-Surface Registration for Liver Navigation
Jul 27, 2025
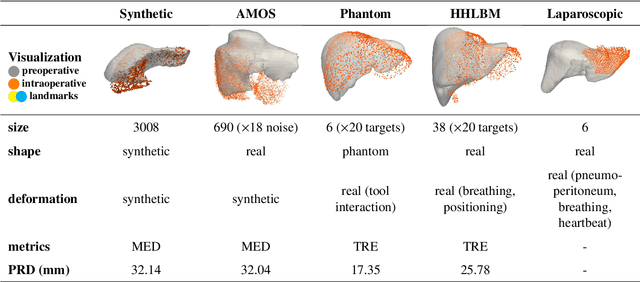


Non-rigid registration is essential for Augmented Reality guided laparoscopic liver surgery by fusing preoperative information, such as tumor location and vascular structures, into the limited intraoperative view, thereby enhancing surgical navigation. A prerequisite is the accurate prediction of intraoperative liver deformation which remains highly challenging due to factors such as large deformation caused by pneumoperitoneum, respiration and tool interaction as well as noisy intraoperative data, and limited field of view due to occlusion and constrained camera movement. To address these challenges, we introduce PIVOTS, a Preoperative to Intraoperative VOlume-To-Surface registration neural network that directly takes point clouds as input for deformation prediction. The geometric feature extraction encoder allows multi-resolution feature extraction, and the decoder, comprising novel deformation aware cross attention modules, enables pre- and intraoperative information interaction and accurate multi-level displacement prediction. We train the neural network on synthetic data simulated from a biomechanical simulation pipeline and validate its performance on both synthetic and real datasets. Results demonstrate superior registration performance of our method compared to baseline methods, exhibiting strong robustness against high amounts of noise, large deformation, and various levels of intraoperative visibility. We publish the training and test sets as evaluation benchmarks and call for a fair comparison of liver registration methods with volume-to-surface data. Code and datasets are available here https://github.com/pengliu-nct/PIVOTS.
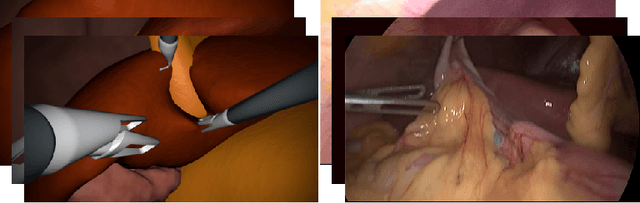
Long-Term Temporally Consistent Unpaired Video Translation from Simulated Surgical 3D Data
Mar 31, 2021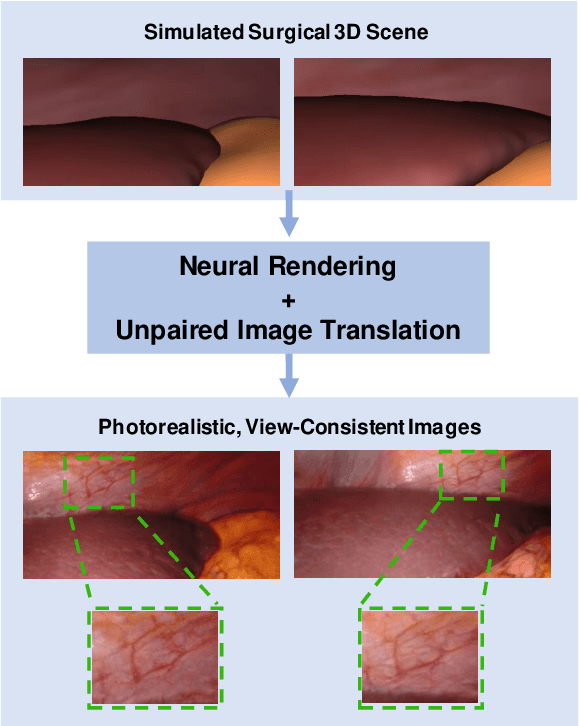
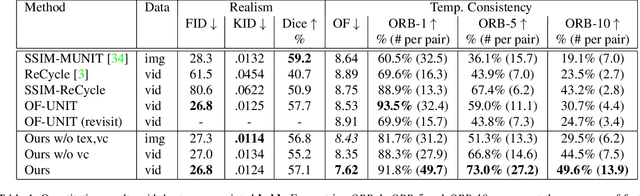
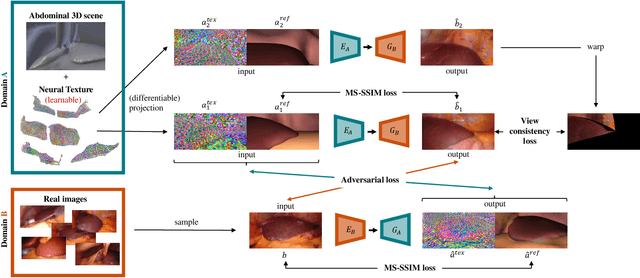
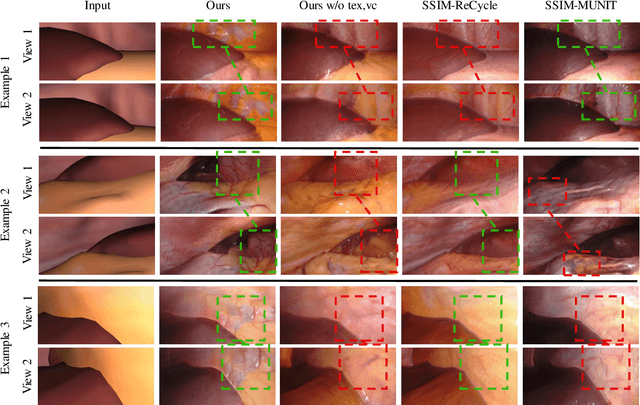
Research in unpaired video translation has mainly focused on short-term temporal consistency by conditioning on neighboring frames. However for transfer from simulated to photorealistic sequences, available information on the underlying geometry offers potential for achieving global consistency across views. We propose a novel approach which combines unpaired image translation with neural rendering to transfer simulated to photorealistic surgical abdominal scenes. By introducing global learnable textures and a lighting-invariant view-consistency loss, our method produces consistent translations of arbitrary views and thus enables long-term consistent video synthesis. We design and test our model to generate video sequences from minimally-invasive surgical abdominal scenes. Because labeled data is often limited in this domain, photorealistic data where ground truth information from the simulated domain is preserved is especially relevant. By extending existing image-based methods to view-consistent videos, we aim to impact the applicability of simulated training and evaluation environments for surgical applications. Code and data will be made publicly available soon.
Non-Rigid Volume to Surface Registration using a Data-Driven Biomechanical Model
May 29, 2020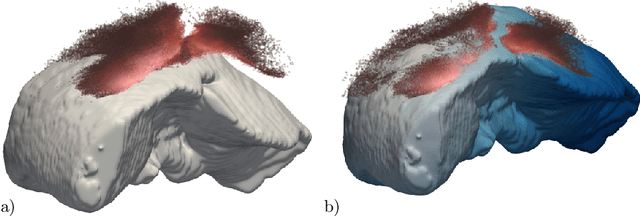

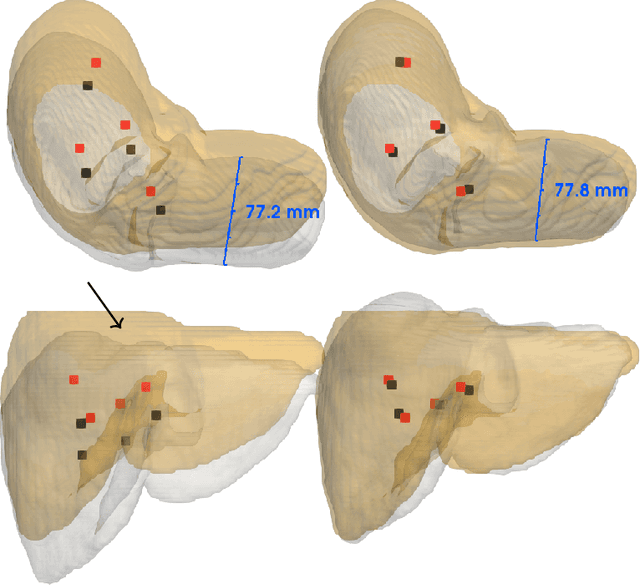
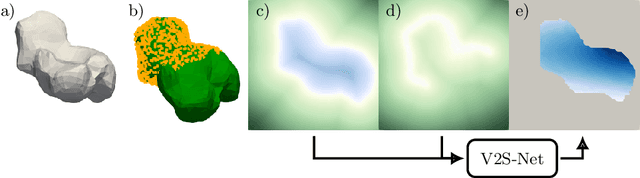
Non-rigid registration is a key component in soft-tissue navigation. We focus on laparoscopic liver surgery, where we register the organ model obtained from a preoperative CT scan to the intraoperative partial organ surface, reconstructed from the laparoscopic video. This is a challenging task due to sparse and noisy intraoperative data, real-time requirements and many unknowns - such as tissue properties and boundary conditions. Furthermore, establishing correspondences between pre- and intraoperative data can be extremely difficult since the liver usually lacks distinct surface features and the used imaging modalities suffer from very different types of noise. In this work, we train a convolutional neural network to perform both the search for surface correspondences as well as the non-rigid registration in one step. The network is trained on physically accurate biomechanical simulations of randomly generated, deforming organ-like structures. This enables the network to immediately generalize to a new patient organ without the need to re-train. We add various amounts of noise to the intraoperative surfaces during training, making the network robust to noisy intraoperative data. During inference, the network outputs the displacement field which matches the preoperative volume to the partial intraoperative surface. In multiple experiments, we show that the network translates well to real data while maintaining a high inference speed. Our code is made available online.
Generating large labeled data sets for laparoscopic image processing tasks using unpaired image-to-image translation
Jul 05, 2019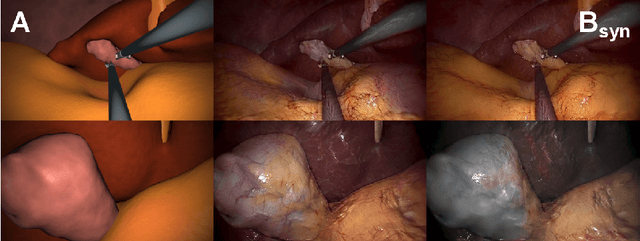
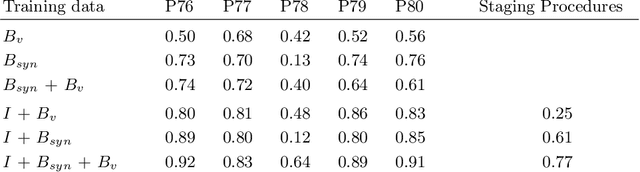
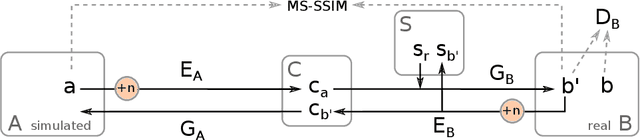
In the medical domain, the lack of large training data sets and benchmarks is often a limiting factor for training deep neural networks. In contrast to expensive manual labeling, computer simulations can generate large and fully labeled data sets with a minimum of manual effort. However, models that are trained on simulated data usually do not translate well to real scenarios. To bridge the domain gap between simulated and real laparoscopic images, we exploit recent advances in unpaired image-to-image translation. We extent an image-to-image translation method to generate a diverse multitude of realistically looking synthetic images based on images from a simple laparoscopy simulation. By incorporating means to ensure that the image content is preserved during the translation process, we ensure that the labels given for the simulated images remain valid for their realistically looking translations. This way, we are able to generate a large, fully labeled synthetic data set of laparoscopic images with realistic appearance. We show that this data set can be used to train models for the task of liver segmentation of laparoscopic images. We achieve average dice scores of up to 0.89 in some patients without manually labeling a single laparoscopic image and show that using our synthetic data to pre-train models can greatly improve their performance. The synthetic data set will be made publicly available, fully labeled with segmentation maps, depth maps, normal maps, and positions of tools and camera (http://opencas.dkfz.de/image2image).