 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMILE-UHURA Challenge -- Small Vessel Segmentation at Mesoscopic Scale from Ultra-High Resolution 7T Magnetic Resonance Angiograms
Nov 14, 2024The human brain receives nutrients and oxygen through an intricate network of blood vessels. Pathology affecting small vessels, at the mesoscopic scale, represents a critical vulnerability within the cerebral blood supply and can lead to severe conditions, such as Cerebral Small Vessel Diseases. The advent of 7 Tesla MRI systems has enabled the acquisition of higher spatial resolution images, making it possible to visualise such vessels in the brain. However, the lack of publicly available annotated datasets has impeded the development of robust, machine learning-driven segmentation algorithms. To address this, the SMILE-UHURA challenge was organised. This challenge, held in conjunction with the ISBI 2023, in Cartagena de Indias, Colombia, aimed to provide a platform for researchers working on related topics. The SMILE-UHURA challenge addresses the gap in publicly available annotated datasets by providing an annotated dataset of Time-of-Flight angiography acquired with 7T MRI. This dataset was created through a combination of automated pre-segmentation and extensive manual refinement. In this manuscript, sixteen submitted methods and two baseline methods are compared both quantitatively and qualitatively on two different datasets: held-out test MRAs from the same dataset as the training data (with labels kept secret) and a separate 7T ToF MRA dataset where both input volumes and labels are kept secret. The results demonstrate that most of the submitted deep learning methods, trained on the provided training dataset, achieved reliable segmentation performance. Dice scores reached up to 0.838 $\pm$ 0.066 and 0.716 $\pm$ 0.125 on the respective datasets, with an average performance of up to 0.804 $\pm$ 0.15.
Automated MRI Quality Assessment of Brain T1-weighted MRI in Clinical Data Warehouses: A Transfer Learning Approach Relying on Artefact Simulation
Jun 18, 2024



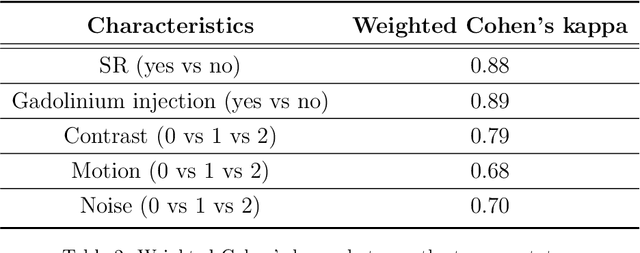
The emergence of clinical data warehouses (CDWs), which contain the medical data of millions of patients, has paved the way for vast data sharing for research. The quality of MRIs gathered in CDWs differs greatly from what is observed in research settings and reflects a certain clinical reality. Consequently, a significant proportion of these images turns out to be unusable due to their poor quality. Given the massive volume of MRIs contained in CDWs, the manual rating of image quality is impossible. Thus, it is necessary to develop an automated solution capable of effectively identifying corrupted images in CDWs. This study presents an innovative transfer learning method for automated quality control of 3D gradient echo T1-weighted brain MRIs within a CDW, leveraging artefact simulation. We first intentionally corrupt images from research datasets by inducing poorer contrast, adding noise and introducing motion artefacts. Subsequently, three artefact-specific models are pre-trained using these corrupted images to detect distinct types of artefacts. Finally, the models are generalised to routine clinical data through a transfer learning technique, utilising 3660 manually annotated images. The overall image quality is inferred from the results of the three models, each designed to detect a specific type of artefact. Our method was validated on an independent test set of 385 3D gradient echo T1-weighted MRIs. Our proposed approach achieved excellent results for the detection of bad quality MRIs, with a balanced accuracy of over 87%, surpassing our previous approach by 3.5 percent points. Additionally, we achieved a satisfactory balanced accuracy of 79% for the detection of moderate quality MRIs, outperforming our previous performance by 5 percent points. Our framework provides a valuable tool for exploiting the potential of MRIs in CDWs.
* Accepted for publication at the Journal of Machine Learning for Biomedical Imaging (MELBA) https://melba-journal.org/2024:012
Frequency Disentangled Learning for Segmentation of Midbrain Structures from Quantitative Susceptibility Mapping Data
Feb 25, 2023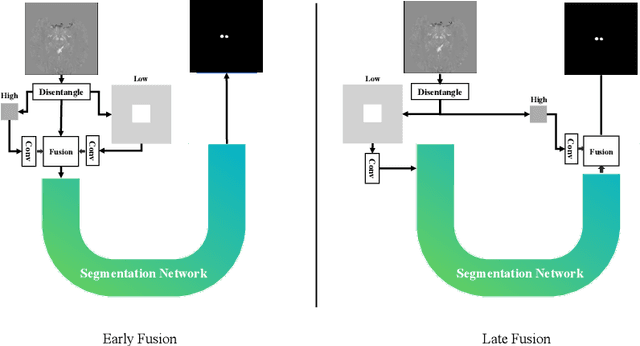

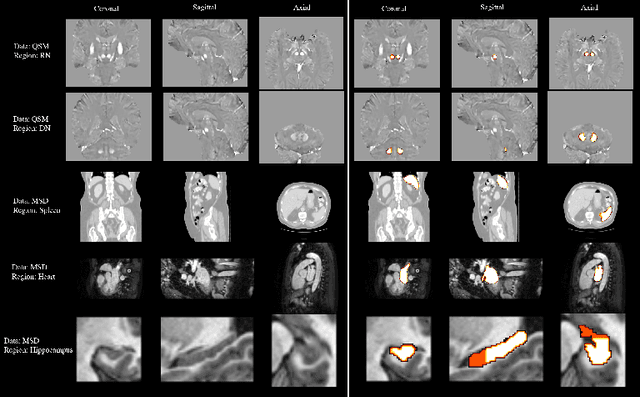
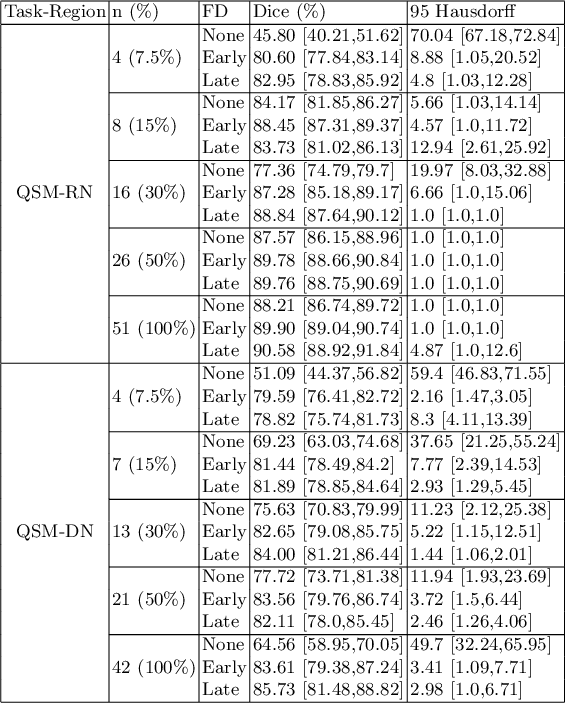
One often lacks sufficient annotated samples for training deep segmentation models. This is in particular the case for less common imaging modalities such as Quantitative Susceptibility Mapping (QSM). It has been shown that deep models tend to fit the target function from low to high frequencies. One may hypothesize that such property can be leveraged for better training of deep learning models. In this paper, we exploit this property to propose a new training method based on frequency-domain disentanglement. It consists of two main steps: i) disentangling the image into high- and low-frequency parts and feature learning; ii) frequency-domain fusion to complete the task. The approach can be used with any backbone segmentation network. We apply the approach to the segmentation of the red and dentate nuclei from QSM data which is particularly relevant for the study of parkinsonian syndromes. We demonstrate that the proposed method provides considerable performance improvements for these tasks. We further applied it to three public datasets from the Medical Segmentation Decathlon (MSD) challenge. For two MSD tasks, it provided smaller but still substantial improvements (up to 7 points of Dice), especially under small training set situations.
Fourier Disentangled Multimodal Prior Knowledge Fusion for Red Nucleus Segmentation in Brain MRI
Nov 02, 2022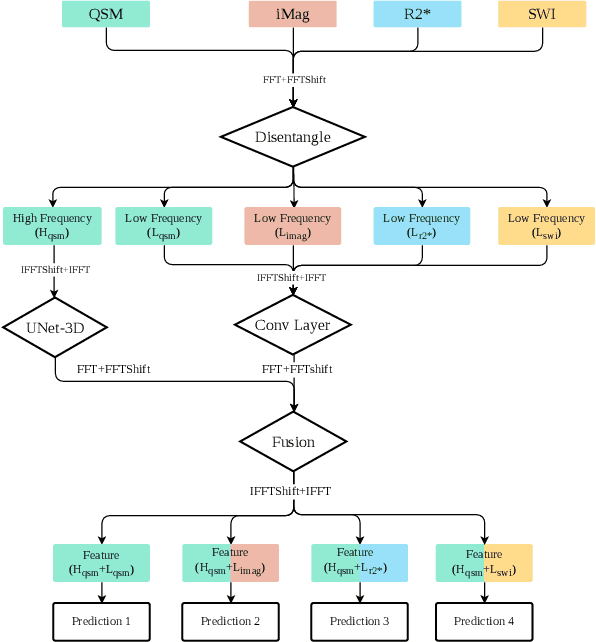
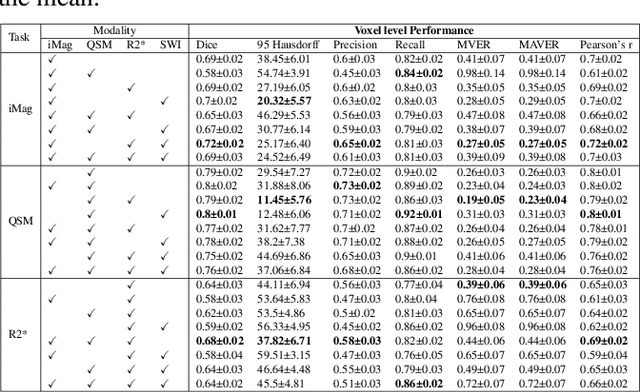

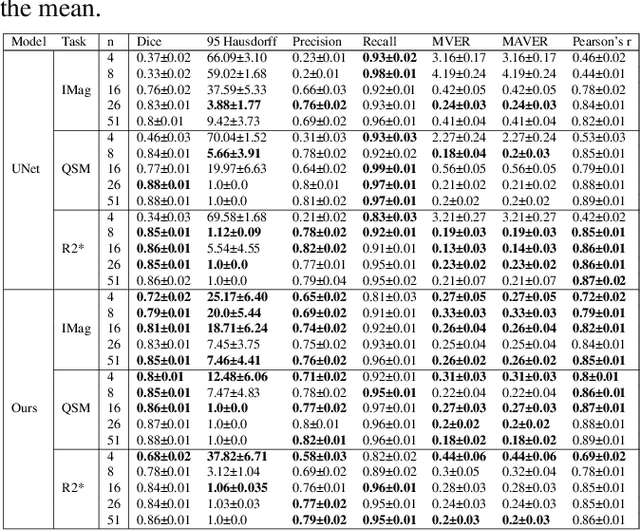
Early and accurate diagnosis of parkinsonian syndromes is critical to provide appropriate care to patients and for inclusion in therapeutic trials. The red nucleus is a structure of the midbrain that plays an important role in these disorders. It can be visualized using iron-sensitive magnetic resonance imaging (MRI) sequences. Different iron-sensitive contrasts can be produced with MRI. Combining such multimodal data has the potential to improve segmentation of the red nucleus. Current multimodal segmentation algorithms are computationally consuming, cannot deal with missing modalities and need annotations for all modalities. In this paper, we propose a new model that integrates prior knowledge from different contrasts for red nucleus segmentation. The method consists of three main stages. First, it disentangles the image into high-level information representing the brain structure, and low-frequency information representing the contrast. The high-frequency information is then fed into a network to learn anatomical features, while the list of multimodal low-frequency information is processed by another module. Finally, feature fusion is performed to complete the segmentation task. The proposed method was used with several iron-sensitive contrasts (iMag, QSM, R2*, SWI). Experiments demonstrate that our proposed model substantially outperforms a baseline UNet model when the training set size is very small.
Automatic quality control of brain T1-weighted magnetic resonance images for a clinical data warehouse
Apr 16, 2021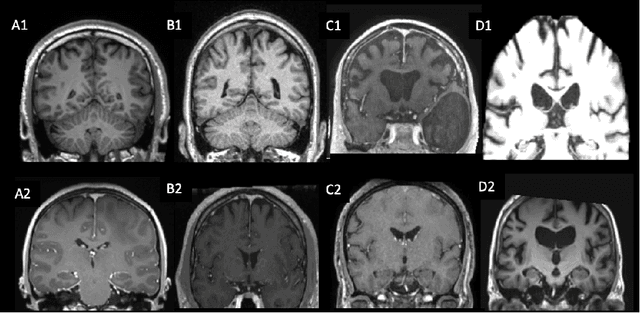
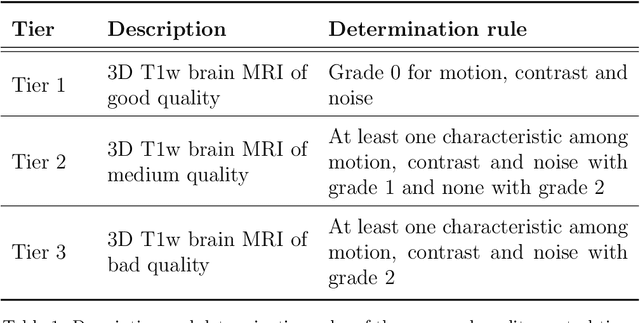
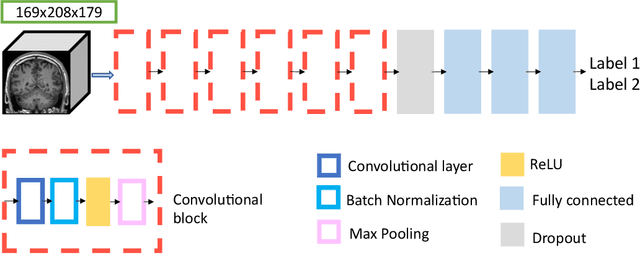
Many studies on machine learning (ML) for computer-aided diagnosis have so far been mostly restricted to high-quality research data. Clinical data warehouses, gathering routine examinations from hospitals, offer great promises for training and validation of ML models in a realistic setting. However, the use of such clinical data warehouses requires quality control (QC) tools. Visual QC by experts is time-consuming and does not scale to large datasets. In this paper, we propose a convolutional neural network (CNN) for the automatic QC of 3D T1-weighted brain MRI for a large heterogeneous clinical data warehouse. To that purpose, we used the data warehouse of the hospitals of the Greater Paris area (Assistance Publique-H\^opitaux de Paris [AP-HP]). Specifically, the objectives were: 1) to identify images which are not proper T1-weighted brain MRIs; 2) to identify acquisitions for which gadolinium was injected; 3) to rate the overall image quality. We used 5000 images for training and validation and a separate set of 500 images for testing. In order to train/validate the CNN, the data were annotated by two trained raters according to a visual QC protocol that we specifically designed for application in the setting of a data warehouse. For objectives 1 and 2, our approach achieved excellent accuracy (balanced accuracy and F1-score \textgreater 90\%), similar to the human raters. For objective 3, the performance was good but substantially lower than that of human raters. Nevertheless, the automatic approach accurately identified (balanced accuracy and F1-score \textgreater 80\%) low quality images, which would typically need to be excluded. Overall, our approach shall be useful for exploiting hospital data warehouses in medical image computing.
Accuracy of MRI Classification Algorithms in a Tertiary Memory Center Clinical Routine Cohort
Mar 19, 2020
BACKGROUND:Automated volumetry software (AVS) has recently become widely available to neuroradiologists. MRI volumetry with AVS may support the diagnosis of dementias by identifying regional atrophy. Moreover, automatic classifiers using machine learning techniques have recently emerged as promising approaches to assist diagnosis. However, the performance of both AVS and automatic classifiers has been evaluated mostly in the artificial setting of research datasets.OBJECTIVE:Our aim was to evaluate the performance of two AVS and an automatic classifier in the clinical routine condition of a memory clinic.METHODS:We studied 239 patients with cognitive troubles from a single memory center cohort. Using clinical routine T1-weighted MRI, we evaluated the classification performance of: 1) univariate volumetry using two AVS (volBrain and Neuroreader$^{TM}$); 2) Support Vector Machine (SVM) automatic classifier, using either the AVS volumes (SVM-AVS), or whole gray matter (SVM-WGM); 3) reading by two neuroradiologists. The performance measure was the balanced diagnostic accuracy. The reference standard was consensus diagnosis by three neurologists using clinical, biological (cerebrospinal fluid) and imaging data and following international criteria.RESULTS:Univariate AVS volumetry provided only moderate accuracies (46% to 71% with hippocampal volume). The accuracy improved when using SVM-AVS classifier (52% to 85%), becoming close to that of SVM-WGM (52 to 90%). Visual classification by neuroradiologists ranged between SVM-AVS and SVM-WGM.CONCLUSION:In the routine practice of a memory clinic, the use of volumetric measures provided by AVS yields only moderate accuracy. Automatic classifiers can improve accuracy and could be a useful tool to assist diagnosis.
Visualization approach to assess the robustness of neural networks for medical image classification
Dec 23, 2019
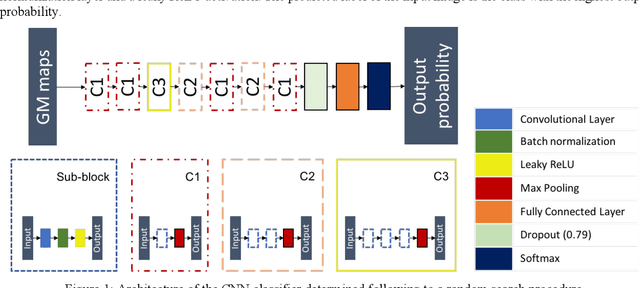
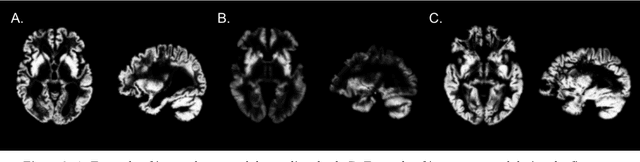

The use of neural networks for diagnosis classification is becoming more and more prevalent in the medical imaging community. However, deep learning method outputs remain hard to explain. Another difficulty is to choose among the large number of techniques developed to analyze how networks learn, as all present different limitations. In this paper, we extended the framework of Fong and Vedaldi [IEEE International Conference on Computer Vision (ICCV), 2017] to visualize the training of convolutional neural networks (CNNs) on 3D quantitative neuroimaging data. Our application focuses on the detection of Alzheimer's disease with gray matter probability maps extracted from structural MRI. We first assessed the robustness of the visualization method by studying the coherence of the longitudinal patterns and regions identified by the network. We then studied the stability of the CNN training by computing visualization-based similarity indexes between different re-runs of the CNN. We demonstrated that the areas identified by the CNN were consistent with what is known of Alzheimer's disease and that the visualization approach extract coherent longitudinal patterns. We also showed that the CNN training is not stable and that the areas identified mainly depend on the initialization and the training process. This issue may exist in many other medical studies using deep learning methods on datasets in which the number of samples is too small and the data dimension is high. This means that it may not be possible to rely on deep learning to detect stable regions of interest in this field yet.