 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupport Tokens, Stability Margins, and a New Foundation for Robust LLMs
Feb 25, 2026Self-attention is usually described as a flexible, content-adaptive way to mix a token with information from its past. We re-interpret causal self-attention transformers, the backbone of modern foundation models, within a probabilistic framework, much like how classical PCA is extended to probabilistic PCA. However, this re-formulation reveals a surprising and deeper structural insight: due to a change-of-variables phenomenon, a barrier constraint emerges on the self-attention parameters. This induces a highly structured geometry on the token space, providing theoretical insights into the dynamics of LLM decoding. This reveals a boundary where attention becomes ill-conditioned, leading to a margin interpretation similar to classical support vector machines. Just like support vectors, this naturally gives rise to the concept of support tokens. Furthermore, we show that LLMs can be interpreted as a stochastic process over the power set of the token space, providing a rigorous probabilistic framework for sequence modeling. We propose a Bayesian framework and derive a MAP estimation objective that requires only a minimal modification to standard LLM training: the addition of a smooth log-barrier penalty to the usual cross-entropy loss. We demonstrate that this provides more robust models without sacrificing out-of-sample accuracy and that it is straightforward to incorporate in practice.
DeText: A Deep Text Ranking Framework with BERT
Aug 06, 2020

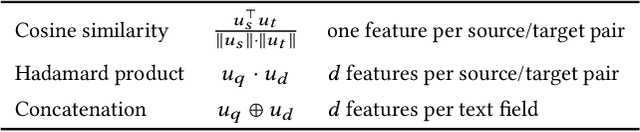
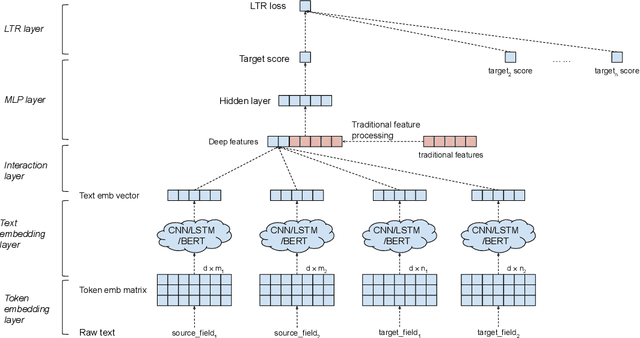
Ranking is the most important component in a search system. Mostsearch systems deal with large amounts of natural language data,hence an effective ranking system requires a deep understandingof text semantics. Recently, deep learning based natural languageprocessing (deep NLP) models have generated promising results onranking systems. BERT is one of the most successful models thatlearn contextual embedding, which has been applied to capturecomplex query-document relations for search ranking. However,this is generally done by exhaustively interacting each query wordwith each document word, which is inefficient for online servingin search product systems. In this paper, we investigate how tobuild an efficient BERT-based ranking model for industry use cases.The solution is further extended to a general ranking framework,DeText, that is open sourced and can be applied to various rankingproductions. Offline and online experiments of DeText on threereal-world search systems present significant improvement overstate-of-the-art approaches.
Scalable Assessment and Mitigation Strategies for Fairness in Rankings
Jun 19, 2020
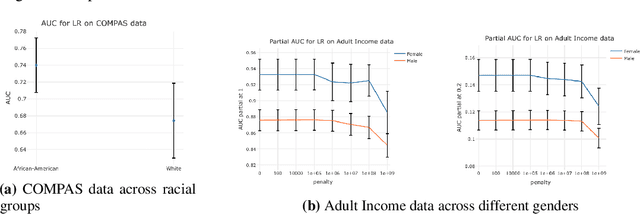
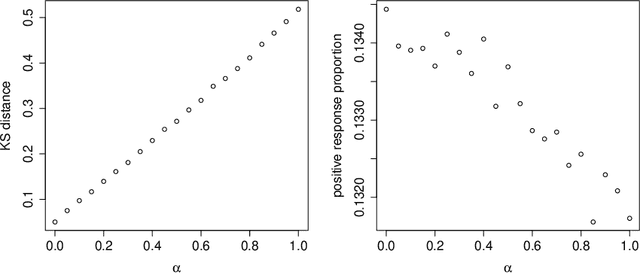
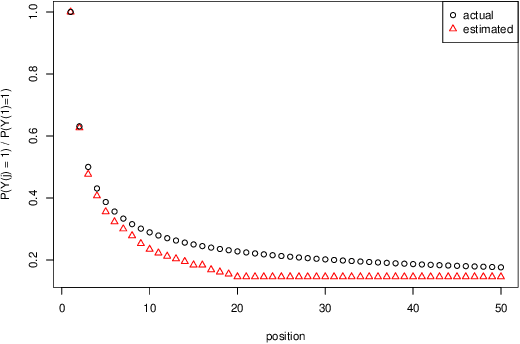
Motivated by industrial-scale applications, we consider two specific areas of fairness, one connected to the notion of equality of opportunity, and the other one generally tied to fair model performance. Throughout the paper, we consider only methods that can be scaled to Internet-industry size datasets. With this in mind, we propose a simple post-processing method to achieve equality of opportunity and discuss challenges and some solutions in the specific cases of recommendation systems and rankings. We then discuss a class of model performance fairness measures based on conditional ROC curves. We propose both scalable uncertainty assessment tools (that improve upon recent research) as well as scalable penalized methods to improve fairness with respect to these metrics. We provide fast algorithms with an emphasis on making few passes over the data when possible.
Bringing Salary Transparency to the World: Computing Robust Compensation Insights via LinkedIn Salary
Sep 01, 2017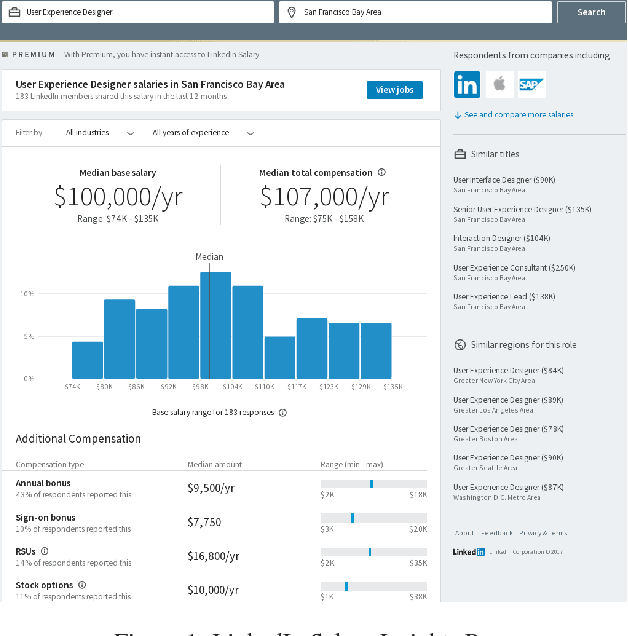

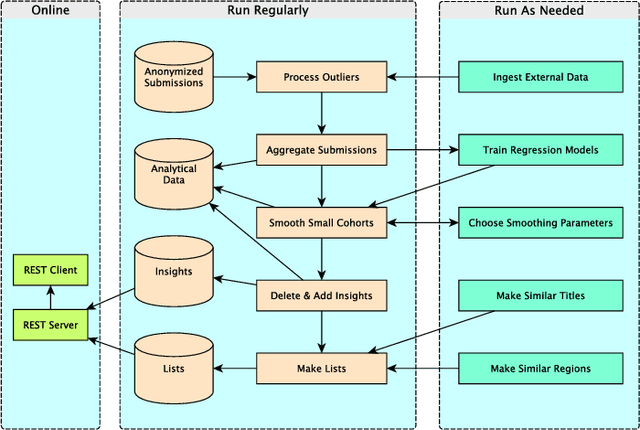

The recently launched LinkedIn Salary product has been designed with the goal of providing compensation insights to the world's professionals and thereby helping them optimize their earning potential. We describe the overall design and architecture of the statistical modeling system underlying this product. We focus on the unique data mining challenges while designing and implementing the system, and describe the modeling components such as Bayesian hierarchical smoothing that help to compute and present robust compensation insights to users. We report on extensive evaluation with nearly one year of de-identified compensation data collected from over one million LinkedIn users, thereby demonstrating the efficacy of the statistical models. We also highlight the lessons learned through the deployment of our system at LinkedIn.
Parallel Matrix Factorization for Binary Response
Mar 22, 2012


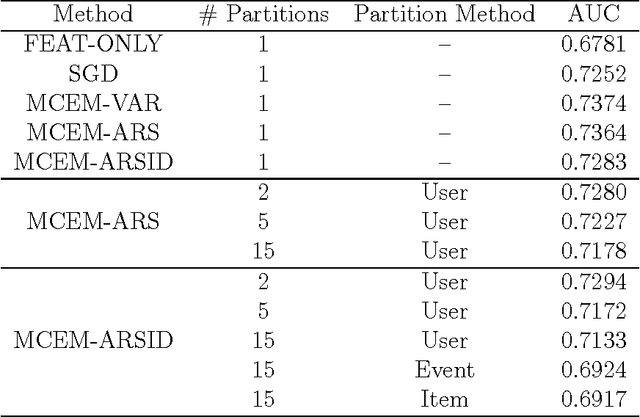
Predicting user affinity to items is an important problem in applications like content optimization, computational advertising, and many more. While bilinear random effect models (matrix factorization) provide state-of-the-art performance when minimizing RMSE through a Gaussian response model on explicit ratings data, applying it to imbalanced binary response data presents additional challenges that we carefully study in this paper. Data in many applications usually consist of users' implicit response that are often binary -- clicking an item or not; the goal is to predict click rates, which is often combined with other measures to calculate utilities to rank items at runtime of the recommender systems. Because of the implicit nature, such data are usually much larger than explicit rating data and often have an imbalanced distribution with a small fraction of click events, making accurate click rate prediction difficult. In this paper, we address two problems. First, we show previous techniques to estimate bilinear random effect models with binary data are less accurate compared to our new approach based on adaptive rejection sampling, especially for imbalanced response. Second, we develop a parallel bilinear random effect model fitting framework using Map-Reduce paradigm that scales to massive datasets. Our parallel algorithm is based on a "divide and conquer" strategy coupled with an ensemble approach. Through experiments on the benchmark MovieLens data, a small Yahoo! Front Page data set, and a large Yahoo! Front Page data set that contains 8M users and 1B binary observations, we show that careful handling of binary response as well as identifiability issues are needed to achieve good performance for click rate prediction, and that the proposed adaptive rejection sampler and the partitioning as well as ensemble techniques significantly improve model performance.