 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Matrix Factorization for Binary Response
Mar 22, 2012


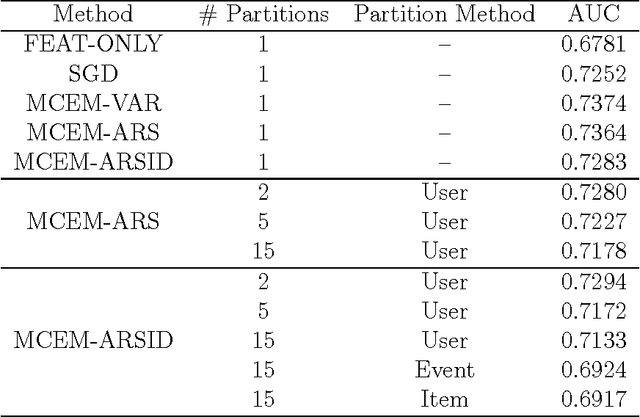
Predicting user affinity to items is an important problem in applications like content optimization, computational advertising, and many more. While bilinear random effect models (matrix factorization) provide state-of-the-art performance when minimizing RMSE through a Gaussian response model on explicit ratings data, applying it to imbalanced binary response data presents additional challenges that we carefully study in this paper. Data in many applications usually consist of users' implicit response that are often binary -- clicking an item or not; the goal is to predict click rates, which is often combined with other measures to calculate utilities to rank items at runtime of the recommender systems. Because of the implicit nature, such data are usually much larger than explicit rating data and often have an imbalanced distribution with a small fraction of click events, making accurate click rate prediction difficult. In this paper, we address two problems. First, we show previous techniques to estimate bilinear random effect models with binary data are less accurate compared to our new approach based on adaptive rejection sampling, especially for imbalanced response. Second, we develop a parallel bilinear random effect model fitting framework using Map-Reduce paradigm that scales to massive datasets. Our parallel algorithm is based on a "divide and conquer" strategy coupled with an ensemble approach. Through experiments on the benchmark MovieLens data, a small Yahoo! Front Page data set, and a large Yahoo! Front Page data set that contains 8M users and 1B binary observations, we show that careful handling of binary response as well as identifiability issues are needed to achieve good performance for click rate prediction, and that the proposed adaptive rejection sampler and the partitioning as well as ensemble techniques significantly improve model performance.