 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Common Operating Picture Framework Leveraging Data Fusion and Deep Learning
Jan 16, 2020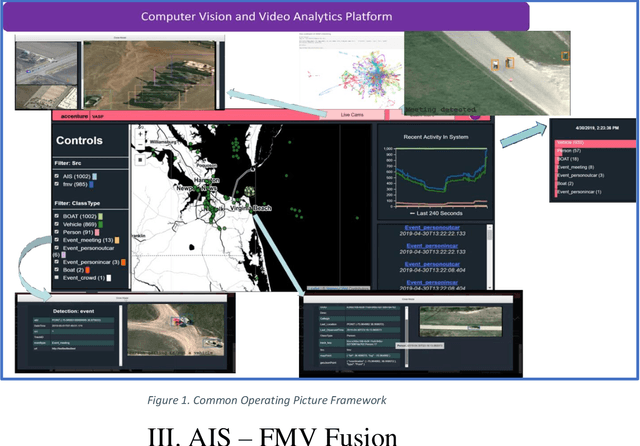
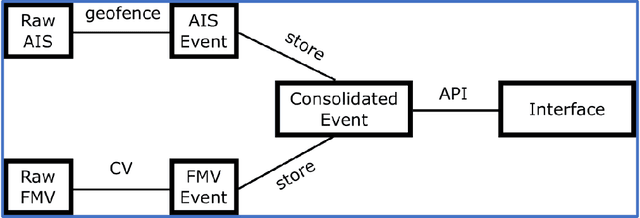
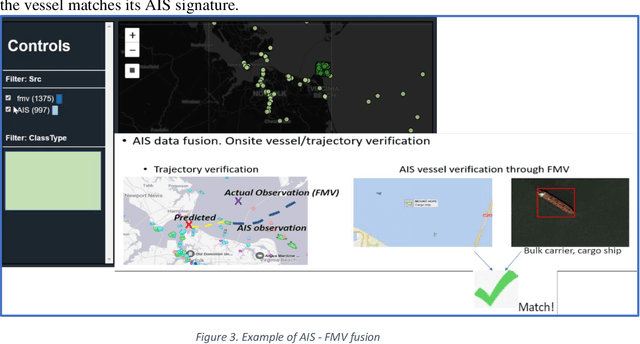

Organizations are starting to realize of the combined power of data and data-driven algorithmic models to gain insights, situational awareness, and advance their mission. A common challenge to gaining insights is connecting inherently different datasets. These datasets (e.g. geocoded features, video streams, raw text, social network data, etc.) per separate they provide very narrow answers; however collectively they can provide new capabilities. In this work, we present a data fusion framework for accelerating solutions for Processing, Exploitation, and Dissemination (PED). Our platform is a collection of services that extract information from several data sources (per separate) by leveraging deep learning and other means of processing. This information is fused by a set of analytical engines that perform data correlations, searches, and other modeling operations to combine information from the disparate data sources. As a result, events of interest are detected, geolocated, logged, and presented into a common operating picture. This common operating picture allows the user to visualize in real time all the data sources, per separate and their collective cooperation. In addition, forensic activities have been implemented and made available through the framework. Users can review archived results and compare them to the most recent snapshot of the operational environment. In our first iteration we have focused on visual data (FMV, WAMI, CCTV/PTZ-Cameras, open source video, etc.) and AIS data streams (satellite and terrestrial sources). As a proof-of-concept, in our experiments we show how FMV detections can be combined with vessel tracking signals from AIS sources to confirm identity, tip-and-cue aerial reconnaissance, and monitor vessel activity in an area.
Contextual Sense Making by Fusing Scene Classification, Detections, and Events in Full Motion Video
Jan 16, 2020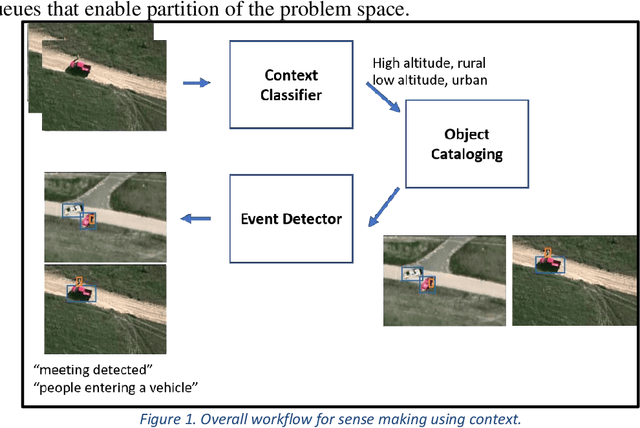
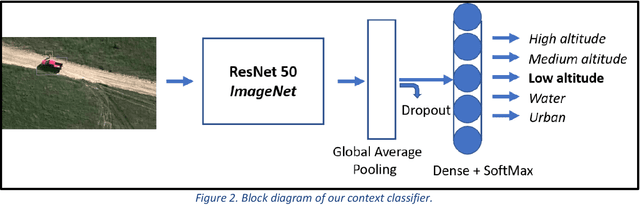
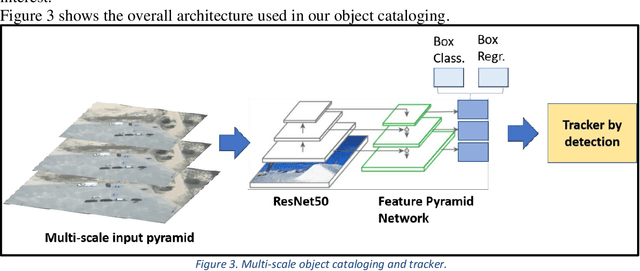

With the proliferation of imaging sensors, the volume of multi-modal imagery far exceeds the ability of human analysts to adequately consume and exploit it. Full motion video (FMV) possesses the extra challenge of containing large amounts of redundant temporal data. We aim to address the needs of human analysts to consume and exploit data given aerial FMV. We have investigated and designed a system capable of detecting events and activities of interest that deviate from the baseline patterns of observation given FMV feeds. We have divided the problem into three tasks: (1) Context awareness, (2) object cataloging, and (3) event detection. The goal of context awareness is to constraint the problem of visual search and detection in video data. A custom image classifier categorizes the scene with one or multiple labels to identify the operating context and environment. This step helps reducing the semantic search space of downstream tasks in order to increase their accuracy. The second step is object cataloging, where an ensemble of object detectors locates and labels any known objects found in the scene (people, vehicles, boats, planes, buildings, etc.). Finally, context information and detections are sent to the event detection engine to monitor for certain behaviors. A series of analytics monitor the scene by tracking object counts, and object interactions. If these object interactions are not declared to be commonly observed in the current scene, the system will report, geolocate, and log the event. Events of interest include identifying a gathering of people as a meeting and/or a crowd, alerting when there are boats on a beach unloading cargo, increased count of people entering a building, people getting in and/or out of vehicles of interest, etc. We have applied our methods on data from different sensors at different resolutions in a variety of geographical areas.
SpaceNet MVOI: a Multi-View Overhead Imagery Dataset
Mar 28, 2019
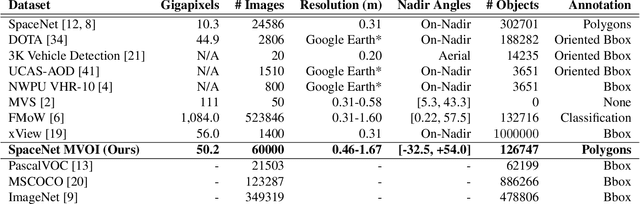
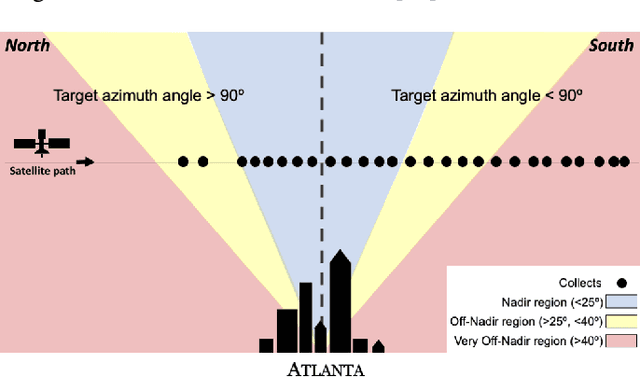

Detection and segmentation of objects in overheard imagery is a challenging task. The variable density, random orientation, small size, and instance-to-instance heterogeneity of objects in overhead imagery calls for approaches distinct from existing models designed for natural scene datasets. Though new overhead imagery datasets are being developed, they almost universally comprise a single view taken from directly overhead ("at nadir"), failing to address one critical variable: look angle. By contrast, views vary in real-world overhead imagery, particularly in dynamic scenarios such as natural disasters where first looks are often over 40 degrees off-nadir. This represents an important challenge to computer vision methods, as changing view angle adds distortions, alters resolution, and changes lighting. At present, the impact of these perturbations for algorithmic detection and segmentation of objects is untested. To address this problem, we introduce the SpaceNet Multi-View Overhead Imagery (MVOI) Dataset, an extension of the SpaceNet open source remote sensing dataset. MVOI comprises 27 unique looks from a broad range of viewing angles (-32 to 54 degrees). Each of these images cover the same geography and are annotated with 126,747 building footprint labels, enabling direct assessment of the impact of viewpoint perturbation on model performance. We benchmark multiple leading segmentation and object detection models on: (1) building detection, (2) generalization to unseen viewing angles and resolutions, and (3) sensitivity of building footprint extraction to changes in resolution. We find that segmentation and object detection models struggle to identify buildings in off-nadir imagery and generalize poorly to unseen views, presenting an important benchmark to explore the broadly relevant challenge of detecting small, heterogeneous target objects in visually dynamic contexts.
DeepGlobe 2018: A Challenge to Parse the Earth through Satellite Images
May 17, 2018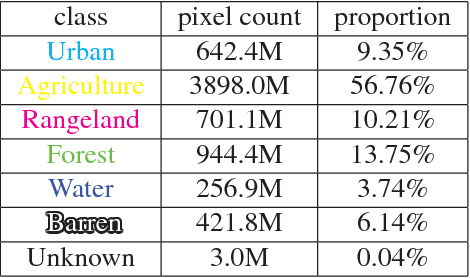

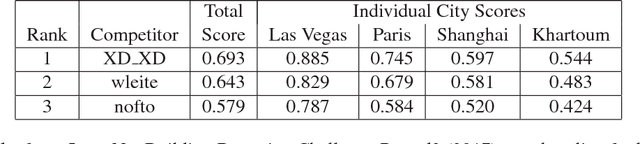

We present the DeepGlobe 2018 Satellite Image Understanding Challenge, which includes three public competitions for segmentation, detection, and classification tasks on satellite images. Similar to other challenges in computer vision domain such as DAVIS and COCO, DeepGlobe proposes three datasets and corresponding evaluation methodologies, coherently bundled in three competitions with a dedicated workshop co-located with CVPR 2018. We observed that satellite imagery is a rich and structured source of information, yet it is less investigated than everyday images by computer vision researchers. However, bridging modern computer vision with remote sensing data analysis could have critical impact to the way we understand our environment and lead to major breakthroughs in global urban planning or climate change research. Keeping such bridging objective in mind, DeepGlobe aims to bring together researchers from different domains to raise awareness of remote sensing in the computer vision community and vice-versa. We aim to improve and evaluate state-of-the-art satellite image understanding approaches, which can hopefully serve as reference benchmarks for future research in the same topic. In this paper, we analyze characteristics of each dataset, define the evaluation criteria of the competitions, and provide baselines for each task.