 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGamified AI Approch for Early Detection of Dementia
May 26, 2024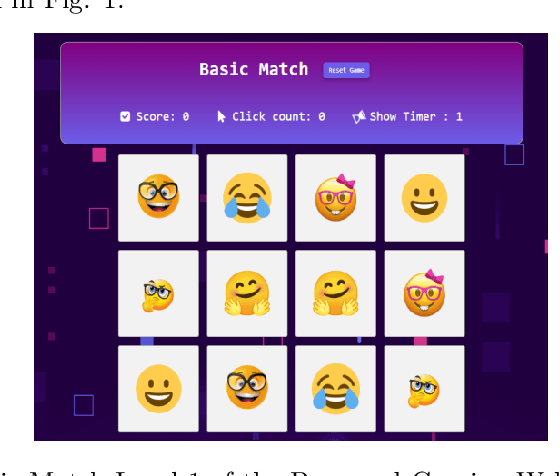
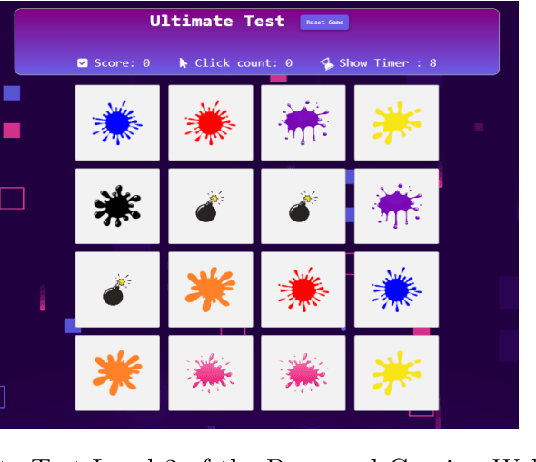
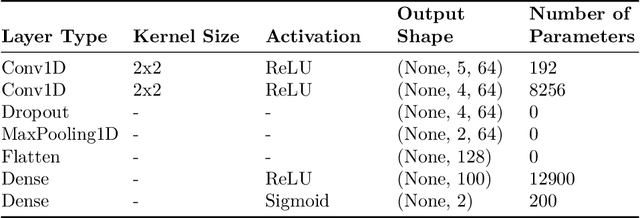
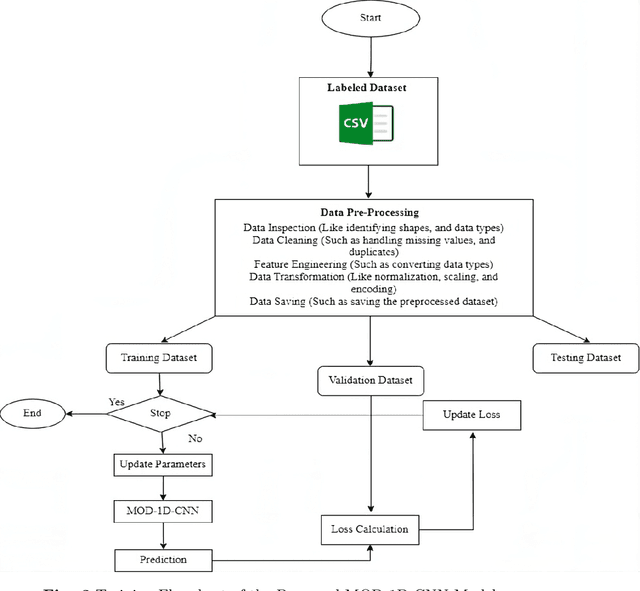
This paper aims to develop a new deep learning-inspired gaming approach for early detection of dementia. This research integrates a robust convolutional neural network (CNN)-based model for early dementia detection using health metrics data as well as facial image data through a cognitive assessment-based gaming application. We have collected 1000 data samples of health metrics dataset from Apollo Diagnostic Center Kolkata that is labeled as either demented or non-demented for the training of MOD-1D-CNN for the game level 1 and another dataset of facial images containing 1800 facial data that are labeled as either demented or non-demented is collected by our research team for the training of MOD-2D-CNN model in-game level 2. In our work, the loss for the proposed MOD-1D-CNN model is 0.2692 and the highest accuracy is 70.50% for identifying the dementia traits using real-life health metrics data. Similarly, the proposed MOD-2D-CNN model loss is 0.1755 and the highest accuracy is obtained here 95.72% for recognizing the dementia status using real-life face-based image data. Therefore, a rule-based weightage method is applied to combine both the proposed methods to achieve the final decision. The MOD-1D-CNN and MOD-2D-CNN models are more lightweight and computationally efficient alternatives because they have a significantly lower number of parameters when compared to the other state-of-the-art models. We have compared their accuracies and parameters with the other state-of-the-art deep learning models.
DeepSat V2: Feature Augmented Convolutional Neural Nets for Satellite Image Classification
Nov 15, 2019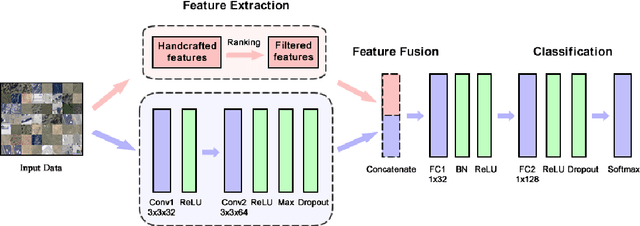
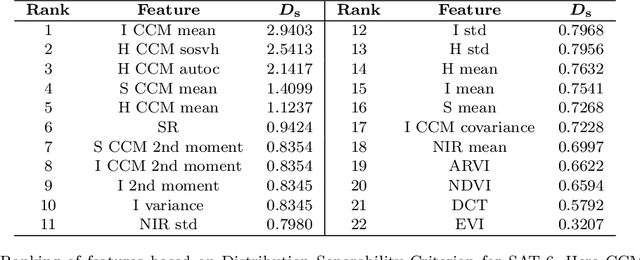
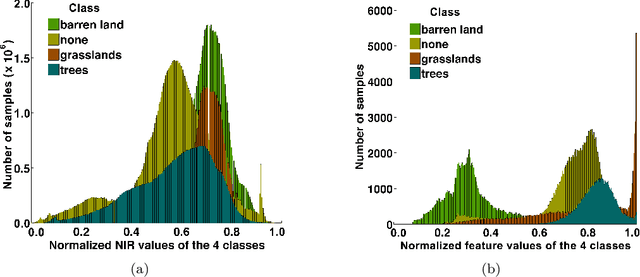
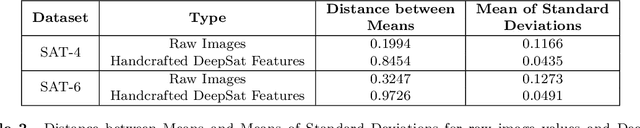
Satellite image classification is a challenging problem that lies at the crossroads of remote sensing, computer vision, and machine learning. Due to the high variability inherent in satellite data, most of the current object classification approaches are not suitable for handling satellite datasets. The progress of satellite image analytics has also been inhibited by the lack of a single labeled high-resolution dataset with multiple class labels. In a preliminary version of this work, we introduced two new high resolution satellite imagery datasets (SAT-4 and SAT-6) and proposed DeepSat framework for classification based on "handcrafted" features and a deep belief network (DBN). The present paper is an extended version, we present an end-to-end framework leveraging an improved architecture that augments a convolutional neural network (CNN) with handcrafted features (instead of using DBN-based architecture) for classification. Our framework, having access to fused spatial information obtained from handcrafted features as well as CNN feature maps, have achieved accuracies of 99.90% and 99.84% respectively, on SAT-4 and SAT-6, surpassing all the other state-of-the-art results. A statistical analysis based on Distribution Separability Criterion substantiates the robustness of our approach in learning better representations for satellite imagery.
From Satellite Imagery to Disaster Insights
Dec 17, 2018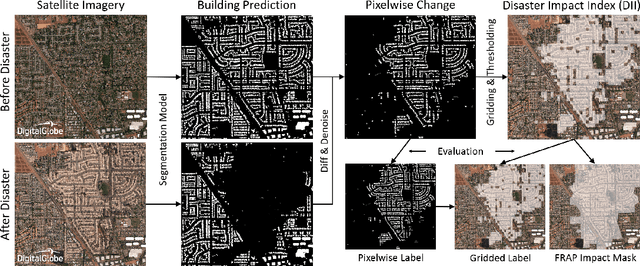

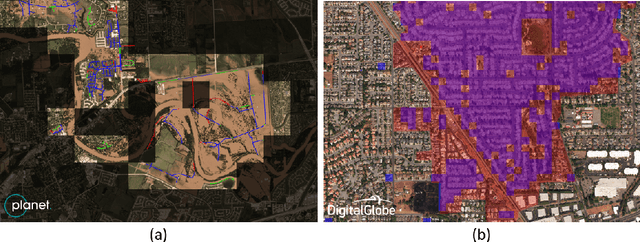

The use of satellite imagery has become increasingly popular for disaster monitoring and response. After a disaster, it is important to prioritize rescue operations, disaster response and coordinate relief efforts. These have to be carried out in a fast and efficient manner since resources are often limited in disaster-affected areas and it's extremely important to identify the areas of maximum damage. However, most of the existing disaster mapping efforts are manual which is time-consuming and often leads to erroneous results. In order to address these issues, we propose a framework for change detection using Convolutional Neural Networks (CNN) on satellite images which can then be thresholded and clustered together into grids to find areas which have been most severely affected by a disaster. We also present a novel metric called Disaster Impact Index (DII) and use it to quantify the impact of two natural disasters - the Hurricane Harvey flood and the Santa Rosa fire. Our framework achieves a top F1 score of 81.2% on the gridded flood dataset and 83.5% on the gridded fire dataset.
Pixel-level Reconstruction and Classification for Noisy Handwritten Bangla Characters
Jun 21, 2018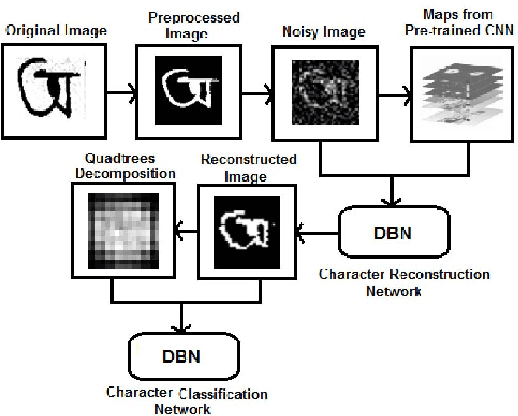
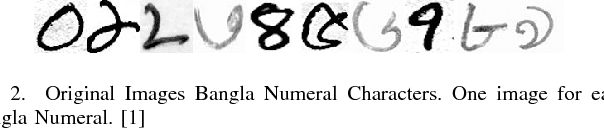


Classification techniques for images of handwritten characters are susceptible to noise. Quadtrees can be an efficient representation for learning from sparse features. In this paper, we improve the effectiveness of probabilistic quadtrees by using a pixel level classifier to extract the character pixels and remove noise from handwritten character images. The pixel level denoiser (a deep belief network) uses the map responses obtained from a pretrained CNN as features for reconstructing the characters eliminating noise. We experimentally demonstrate the effectiveness of our approach by reconstructing and classifying a noisy version of handwritten Bangla Numeral and Basic Character datasets.
DeepGlobe 2018: A Challenge to Parse the Earth through Satellite Images
May 17, 2018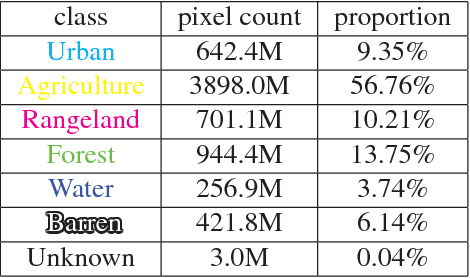

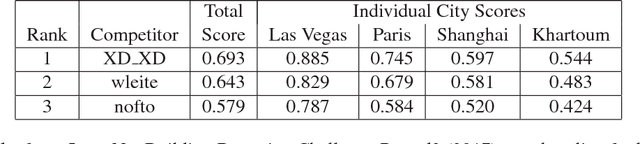

We present the DeepGlobe 2018 Satellite Image Understanding Challenge, which includes three public competitions for segmentation, detection, and classification tasks on satellite images. Similar to other challenges in computer vision domain such as DAVIS and COCO, DeepGlobe proposes three datasets and corresponding evaluation methodologies, coherently bundled in three competitions with a dedicated workshop co-located with CVPR 2018. We observed that satellite imagery is a rich and structured source of information, yet it is less investigated than everyday images by computer vision researchers. However, bridging modern computer vision with remote sensing data analysis could have critical impact to the way we understand our environment and lead to major breakthroughs in global urban planning or climate change research. Keeping such bridging objective in mind, DeepGlobe aims to bring together researchers from different domains to raise awareness of remote sensing in the computer vision community and vice-versa. We aim to improve and evaluate state-of-the-art satellite image understanding approaches, which can hopefully serve as reference benchmarks for future research in the same topic. In this paper, we analyze characteristics of each dataset, define the evaluation criteria of the competitions, and provide baselines for each task.
Core Sampling Framework for Pixel Classification
Dec 06, 2016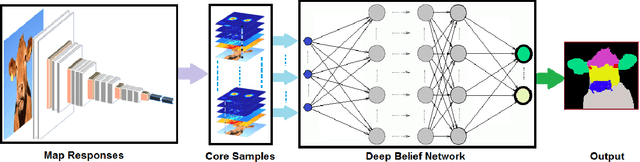

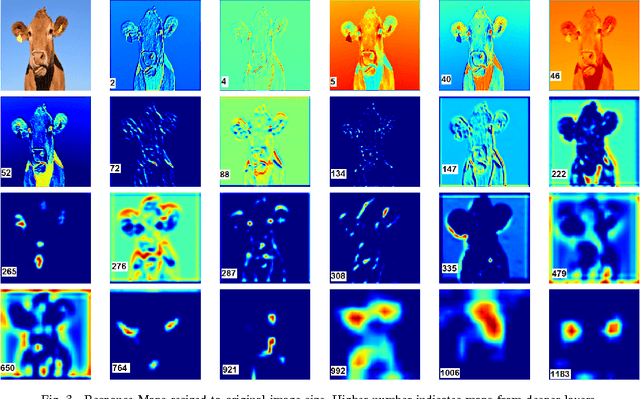
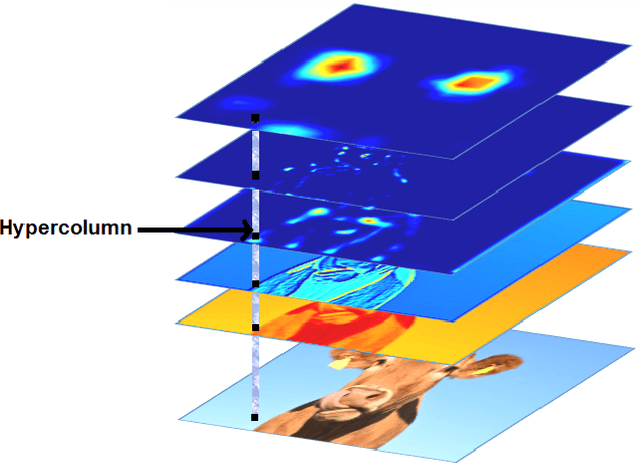
The intermediate map responses of a Convolutional Neural Network (CNN) contain information about an image that can be used to extract contextual knowledge about it. In this paper, we present a core sampling framework that is able to use these activation maps from several layers as features to another neural network using transfer learning to provide an understanding of an input image. Our framework creates a representation that combines features from the test data and the contextual knowledge gained from the responses of a pretrained network, processes it and feeds it to a separate Deep Belief Network. We use this representation to extract more information from an image at the pixel level, hence gaining understanding of the whole image. We experimentally demonstrate the usefulness of our framework using a pretrained VGG-16 model to perform segmentation on the BAERI dataset of Synthetic Aperture Radar(SAR) imagery and the CAMVID dataset.
A Theoretical Analysis of Deep Neural Networks for Texture Classification
Jun 21, 2016
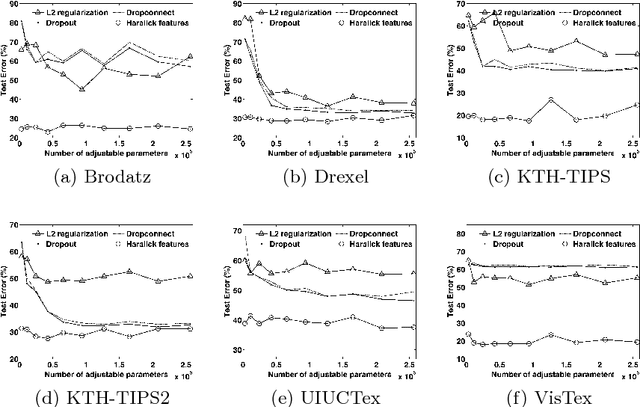
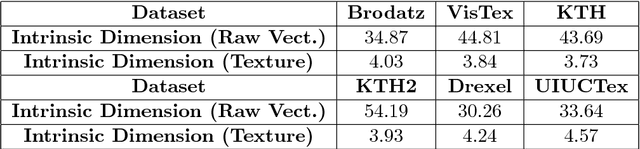
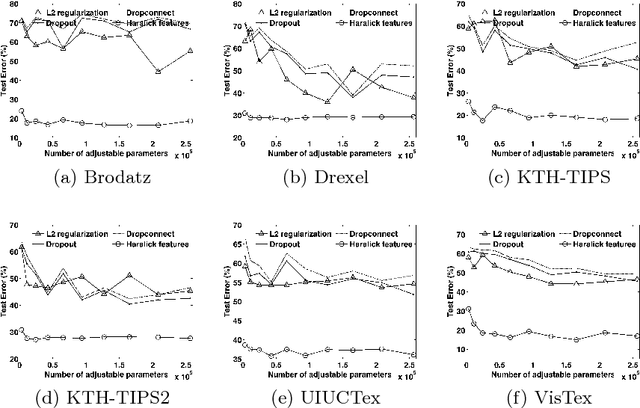
We investigate the use of Deep Neural Networks for the classification of image datasets where texture features are important for generating class-conditional discriminative representations. To this end, we first derive the size of the feature space for some standard textural features extracted from the input dataset and then use the theory of Vapnik-Chervonenkis dimension to show that hand-crafted feature extraction creates low-dimensional representations which help in reducing the overall excess error rate. As a corollary to this analysis, we derive for the first time upper bounds on the VC dimension of Convolutional Neural Network as well as Dropout and Dropconnect networks and the relation between excess error rate of Dropout and Dropconnect networks. The concept of intrinsic dimension is used to validate the intuition that texture-based datasets are inherently higher dimensional as compared to handwritten digits or other object recognition datasets and hence more difficult to be shattered by neural networks. We then derive the mean distance from the centroid to the nearest and farthest sampling points in an n-dimensional manifold and show that the Relative Contrast of the sample data vanishes as dimensionality of the underlying vector space tends to infinity.
DeepSat - A Learning framework for Satellite Imagery
Sep 11, 2015
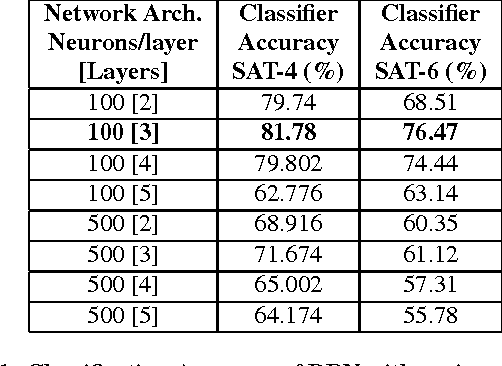
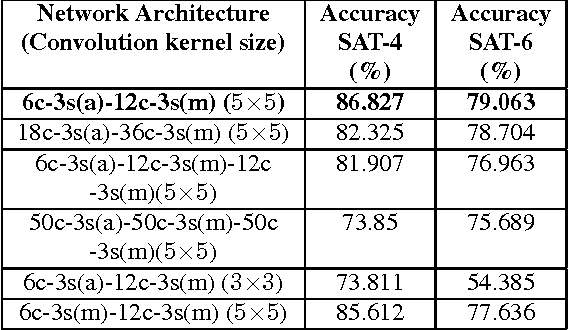
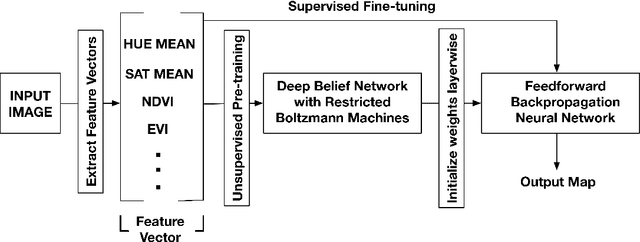
Satellite image classification is a challenging problem that lies at the crossroads of remote sensing, computer vision, and machine learning. Due to the high variability inherent in satellite data, most of the current object classification approaches are not suitable for handling satellite datasets. The progress of satellite image analytics has also been inhibited by the lack of a single labeled high-resolution dataset with multiple class labels. The contributions of this paper are twofold - (1) first, we present two new satellite datasets called SAT-4 and SAT-6, and (2) then, we propose a classification framework that extracts features from an input image, normalizes them and feeds the normalized feature vectors to a Deep Belief Network for classification. On the SAT-4 dataset, our best network produces a classification accuracy of 97.95% and outperforms three state-of-the-art object recognition algorithms, namely - Deep Belief Networks, Convolutional Neural Networks and Stacked Denoising Autoencoders by ~11%. On SAT-6, it produces a classification accuracy of 93.9% and outperforms the other algorithms by ~15%. Comparative studies with a Random Forest classifier show the advantage of an unsupervised learning approach over traditional supervised learning techniques. A statistical analysis based on Distribution Separability Criterion and Intrinsic Dimensionality Estimation substantiates the effectiveness of our approach in learning better representations for satellite imagery.
Learning Sparse Feature Representations using Probabilistic Quadtrees and Deep Belief Nets
Sep 11, 2015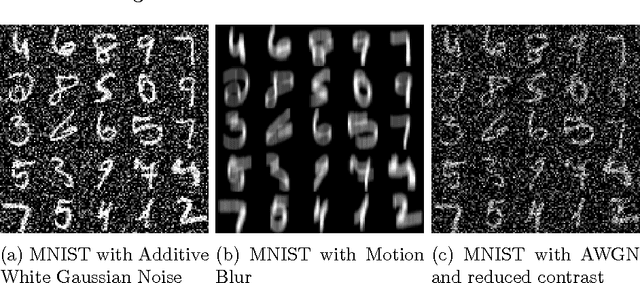
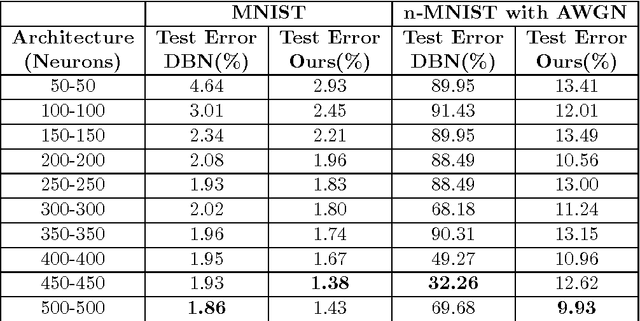
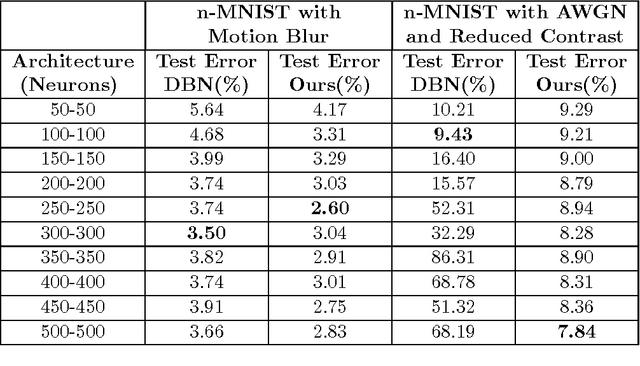
Learning sparse feature representations is a useful instrument for solving an unsupervised learning problem. In this paper, we present three labeled handwritten digit datasets, collectively called n-MNIST. Then, we propose a novel framework for the classification of handwritten digits that learns sparse representations using probabilistic quadtrees and Deep Belief Nets. On the MNIST and n-MNIST datasets, our framework shows promising results and significantly outperforms traditional Deep Belief Networks.