 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkipKV: Selective Skipping of KV Generation and Storage for Efficient Inference with Large Reasoning Models
Dec 08, 2025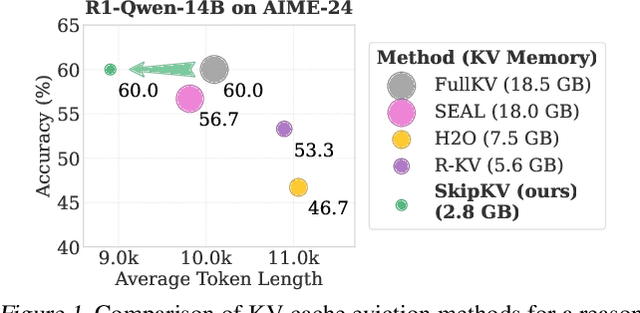
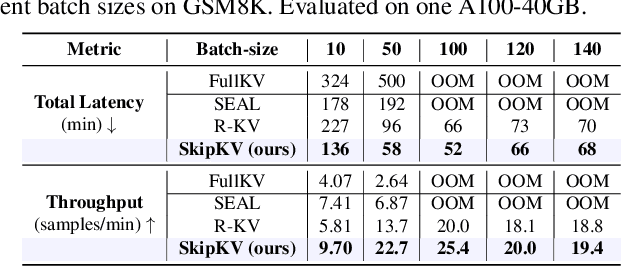
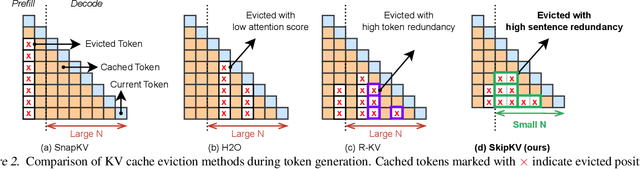
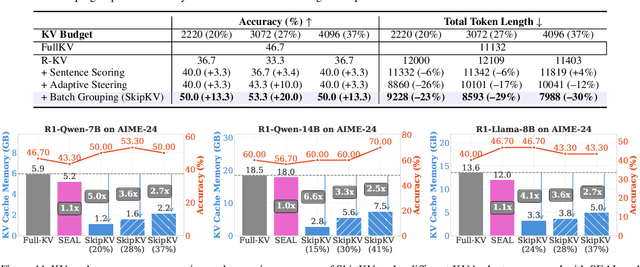
Large reasoning models (LRMs) often cost significant key-value (KV) cache overhead, due to their linear growth with the verbose chain-of-thought (CoT) reasoning process. This costs both memory and throughput bottleneck limiting their efficient deployment. Towards reducing KV cache size during inference, we first investigate the effectiveness of existing KV cache eviction methods for CoT reasoning. Interestingly, we find that due to unstable token-wise scoring and the reduced effective KV budget caused by padding tokens, state-of-the-art (SoTA) eviction methods fail to maintain accuracy in the multi-batch setting. Additionally, these methods often generate longer sequences than the original model, as semantic-unaware token-wise eviction leads to repeated revalidation during reasoning. To address these issues, we present \textbf{SkipKV}, a \textbf{\textit{training-free}} KV compression method for selective \textit{eviction} and \textit{generation} operating at a coarse-grained sentence-level sequence removal for efficient CoT reasoning. In specific, it introduces a \textit{sentence-scoring metric} to identify and remove highly similar sentences while maintaining semantic coherence. To suppress redundant generation, SkipKV dynamically adjusts a steering vector to update the hidden activation states during inference enforcing the LRM to generate concise response. Extensive evaluations on multiple reasoning benchmarks demonstrate the effectiveness of SkipKV in maintaining up to $\mathbf{26.7}\%$ improved accuracy compared to the alternatives, at a similar compression budget. Additionally, compared to SoTA, SkipKV yields up to $\mathbf{1.6}\times$ fewer generation length while improving throughput up to $\mathbf{1.7}\times$.
An Analysis of RF Transfer Learning Behavior Using Synthetic Data
Oct 03, 2022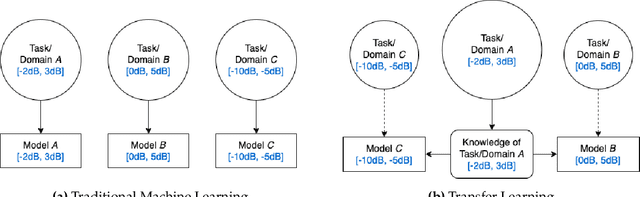
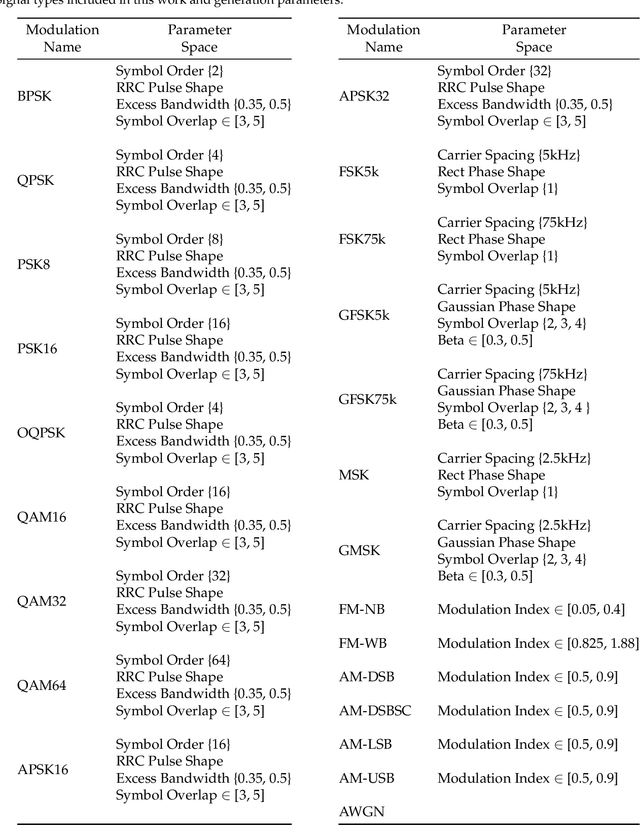

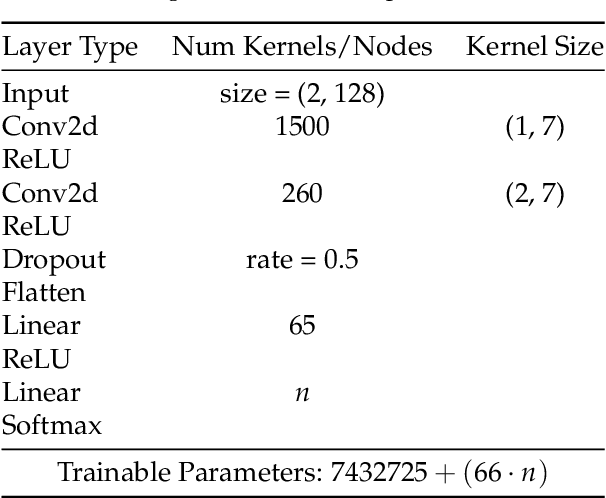
Transfer learning (TL) techniques, which leverage prior knowledge gained from data with different distributions to achieve higher performance and reduced training time, are often used in computer vision (CV) and natural language processing (NLP), but have yet to be fully utilized in the field of radio frequency machine learning (RFML). This work systematically evaluates how radio frequency (RF) TL behavior by examining how the training domain and task, characterized by the transmitter/receiver hardware and channel environment, impact RF TL performance for an example automatic modulation classification (AMC) use-case. Through exhaustive experimentation using carefully curated synthetic datasets with varying signal types, signal-to-noise ratios (SNRs), and frequency offsets (FOs), generalized conclusions are drawn regarding how best to use RF TL techniques for domain adaptation and sequential learning. Consistent with trends identified in other modalities, results show that RF TL performance is highly dependent on the similarity between the source and target domains/tasks. Results also discuss the impacts of channel environment, hardware variations, and domain/task difficulty on RF TL performance, and compare RF TL performance using head re-training and model fine-tuning methods.
Assessing the Value of Transfer Learning Metrics for RF Domain Adaptation
Jun 16, 2022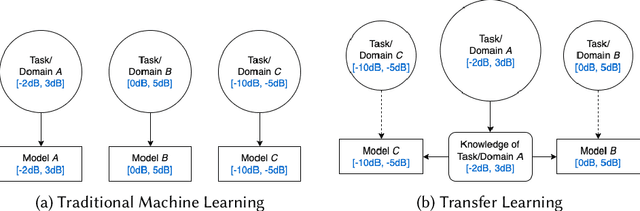

The use of transfer learning (TL) techniques has become common practice in fields such as computer vision (CV) and natural language processing (NLP). Leveraging prior knowledge gained from data with different distributions, TL offers higher performance and reduced training time, but has yet to be fully utilized in applications of machine learning (ML) and deep learning (DL) techniques to applications related to wireless communications, a field loosely termed radio frequency machine learning (RFML). This work begins this examination by evaluating the how radio frequency (RF) domain changes encourage or prevent the transfer of features learned by convolutional neural network (CNN)-based automatic modulation classifiers. Additionally, we examine existing transferability metrics, Log Expected Empirical Prediction (LEEP) and Logarithm of Maximum Evidence (LogME), as a means to both select source models for RF domain adaptation and predict post-transfer accuracy without further training.
Explainable Neural Network-based Modulation Classification via Concept Bottleneck Models
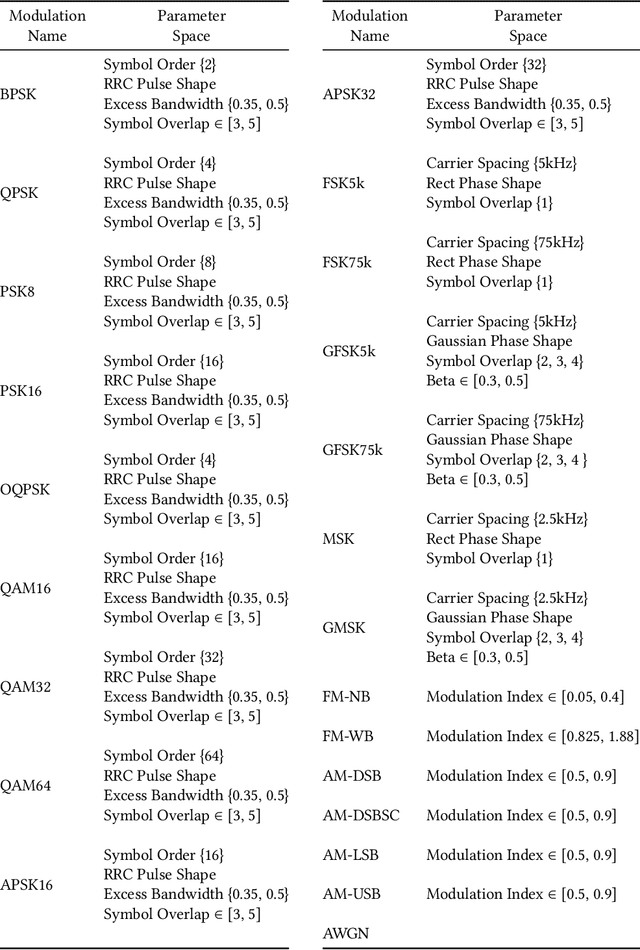
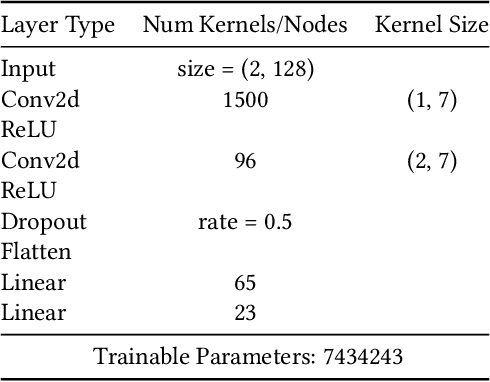
Jan 04, 2021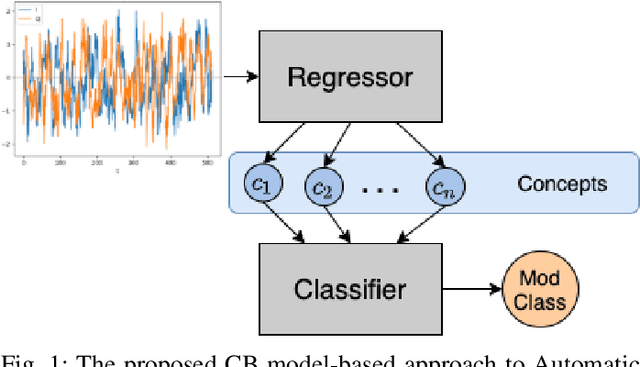
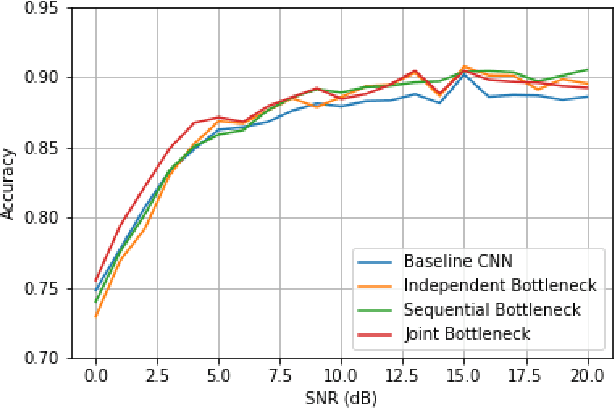

While RFML is expected to be a key enabler of future wireless standards, a significant challenge to the widespread adoption of RFML techniques is the lack of explainability in deep learning models. This work investigates the use of CB models as a means to provide inherent decision explanations in the context of DL-based AMC. Results show that the proposed approach not only meets the performance of single-network DL-based AMC algorithms, but provides the desired model explainability and shows potential for classifying modulation schemes not seen during training (i.e. zero-shot learning).
SpaceNet MVOI: a Multi-View Overhead Imagery Dataset
Mar 28, 2019
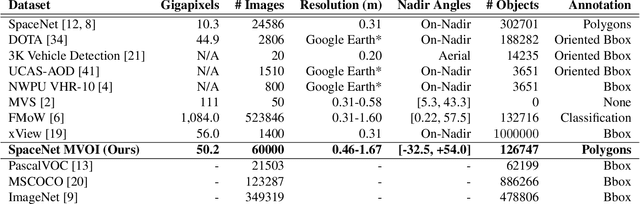
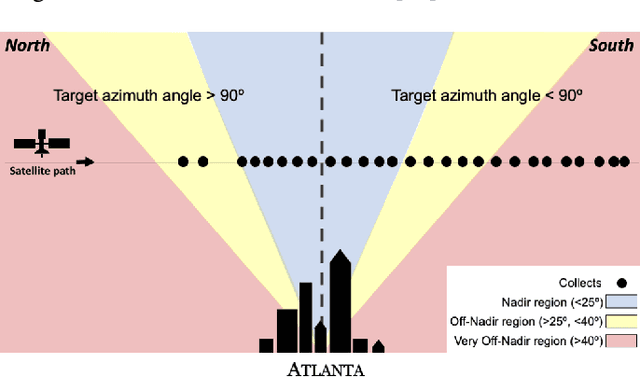

Detection and segmentation of objects in overheard imagery is a challenging task. The variable density, random orientation, small size, and instance-to-instance heterogeneity of objects in overhead imagery calls for approaches distinct from existing models designed for natural scene datasets. Though new overhead imagery datasets are being developed, they almost universally comprise a single view taken from directly overhead ("at nadir"), failing to address one critical variable: look angle. By contrast, views vary in real-world overhead imagery, particularly in dynamic scenarios such as natural disasters where first looks are often over 40 degrees off-nadir. This represents an important challenge to computer vision methods, as changing view angle adds distortions, alters resolution, and changes lighting. At present, the impact of these perturbations for algorithmic detection and segmentation of objects is untested. To address this problem, we introduce the SpaceNet Multi-View Overhead Imagery (MVOI) Dataset, an extension of the SpaceNet open source remote sensing dataset. MVOI comprises 27 unique looks from a broad range of viewing angles (-32 to 54 degrees). Each of these images cover the same geography and are annotated with 126,747 building footprint labels, enabling direct assessment of the impact of viewpoint perturbation on model performance. We benchmark multiple leading segmentation and object detection models on: (1) building detection, (2) generalization to unseen viewing angles and resolutions, and (3) sensitivity of building footprint extraction to changes in resolution. We find that segmentation and object detection models struggle to identify buildings in off-nadir imagery and generalize poorly to unseen views, presenting an important benchmark to explore the broadly relevant challenge of detecting small, heterogeneous target objects in visually dynamic contexts.