 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Analysis of RF Transfer Learning Behavior Using Synthetic Data
Oct 03, 2022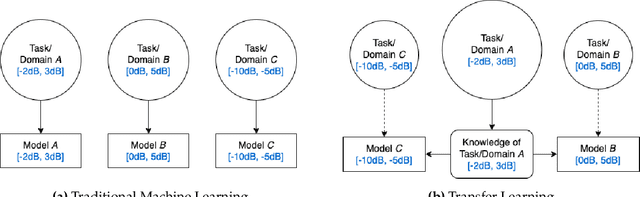
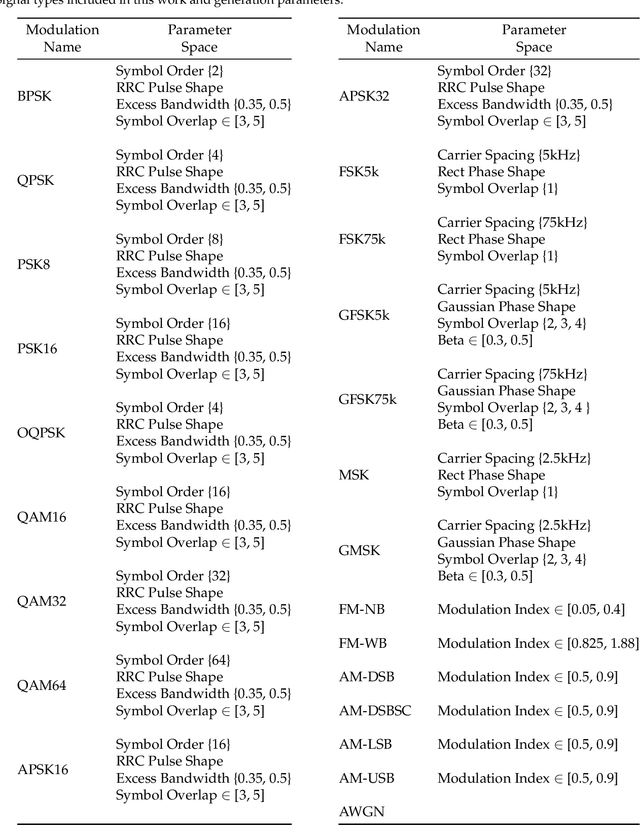

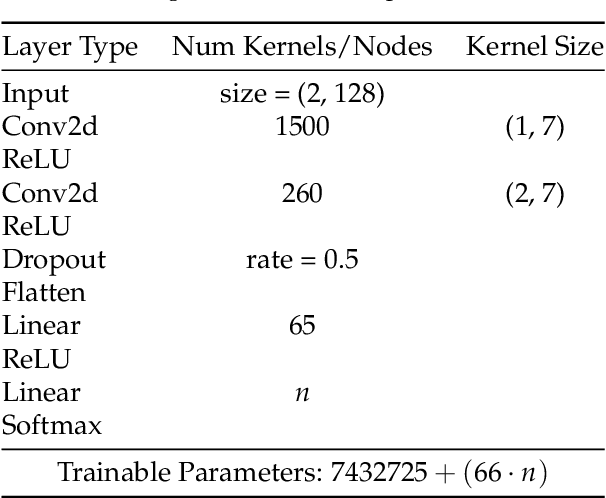
Transfer learning (TL) techniques, which leverage prior knowledge gained from data with different distributions to achieve higher performance and reduced training time, are often used in computer vision (CV) and natural language processing (NLP), but have yet to be fully utilized in the field of radio frequency machine learning (RFML). This work systematically evaluates how radio frequency (RF) TL behavior by examining how the training domain and task, characterized by the transmitter/receiver hardware and channel environment, impact RF TL performance for an example automatic modulation classification (AMC) use-case. Through exhaustive experimentation using carefully curated synthetic datasets with varying signal types, signal-to-noise ratios (SNRs), and frequency offsets (FOs), generalized conclusions are drawn regarding how best to use RF TL techniques for domain adaptation and sequential learning. Consistent with trends identified in other modalities, results show that RF TL performance is highly dependent on the similarity between the source and target domains/tasks. Results also discuss the impacts of channel environment, hardware variations, and domain/task difficulty on RF TL performance, and compare RF TL performance using head re-training and model fine-tuning methods.
Assessing the Value of Transfer Learning Metrics for RF Domain Adaptation
Jun 16, 2022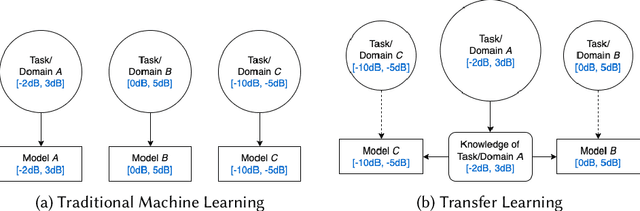

The use of transfer learning (TL) techniques has become common practice in fields such as computer vision (CV) and natural language processing (NLP). Leveraging prior knowledge gained from data with different distributions, TL offers higher performance and reduced training time, but has yet to be fully utilized in applications of machine learning (ML) and deep learning (DL) techniques to applications related to wireless communications, a field loosely termed radio frequency machine learning (RFML). This work begins this examination by evaluating the how radio frequency (RF) domain changes encourage or prevent the transfer of features learned by convolutional neural network (CNN)-based automatic modulation classifiers. Additionally, we examine existing transferability metrics, Log Expected Empirical Prediction (LEEP) and Logarithm of Maximum Evidence (LogME), as a means to both select source models for RF domain adaptation and predict post-transfer accuracy without further training.
Quantifying and Extrapolating Data Needs in Radio Frequency Machine Learning
May 07, 2022
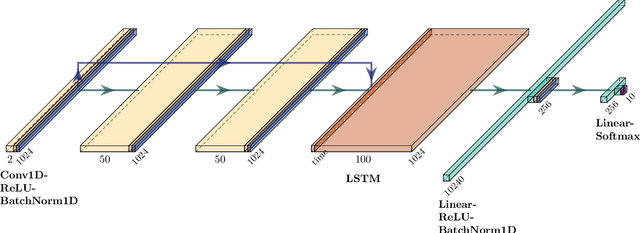

Understanding the relationship between training data and a model's performance once deployed is a fundamental component in the application of machine learning. While the model's deployed performance is dependent on numerous variables within the scope of machine learning, beyond that of the training data itself, the effect of the dataset is isolated in this work to better understand the role training data plays in the problem. This work examines a modulation classification problem in the Radio Frequency domain space, attempting to answer the question of how much training data is required to achieve a desired level of performance, but the procedure readily applies to classification problems across modalities. By repurposing the metrics of transfer potential developed within transfer learning an approach to bound data quantity needs developed given a training approach and machine learning architecture; this approach is presented as a means to estimate data quantity requirements to achieve a target performance. While this approach will require an initial dataset that is germane to the problem space to act as a target dataset on which metrics are extracted, the goal is to allow for the initial data to be orders of magnitude smaller than what is required for delivering a system that achieves the desired performance. An additional benefit of the techniques presented here is that the quality of different datasets can be numerically evaluated and tied together with the quantity of data, and the performance of the system.
Training Data Augmentation for Deep Learning RF Systems
Oct 19, 2020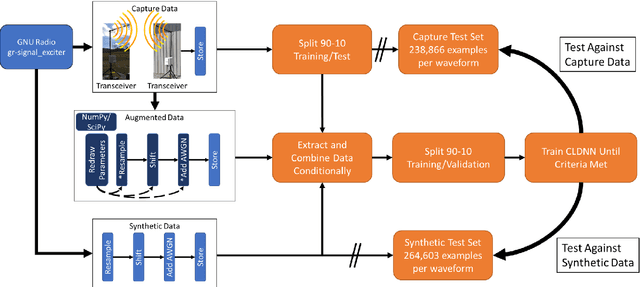
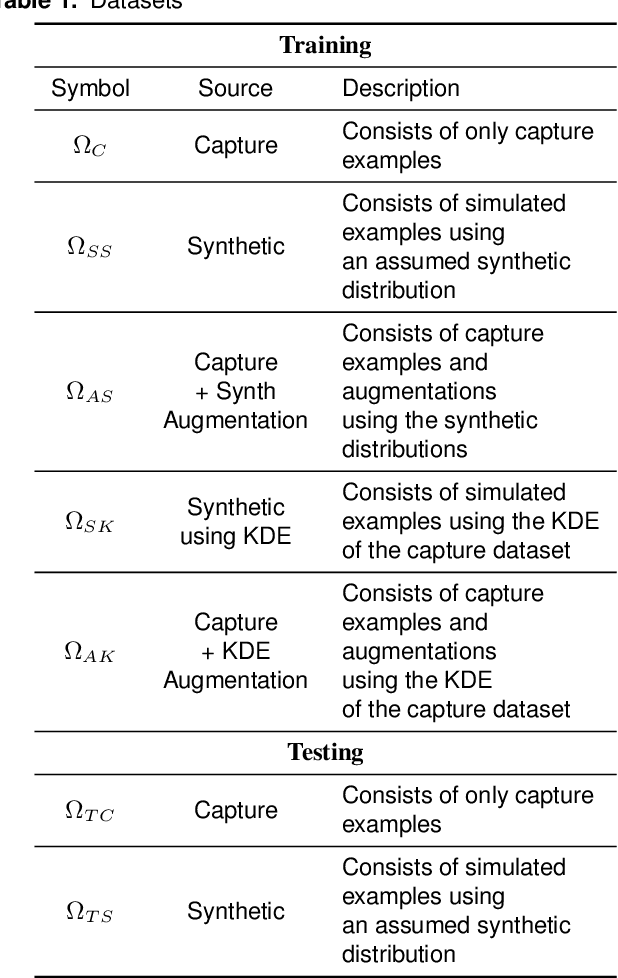
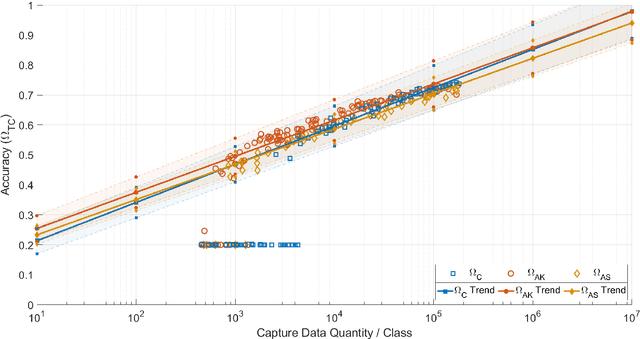

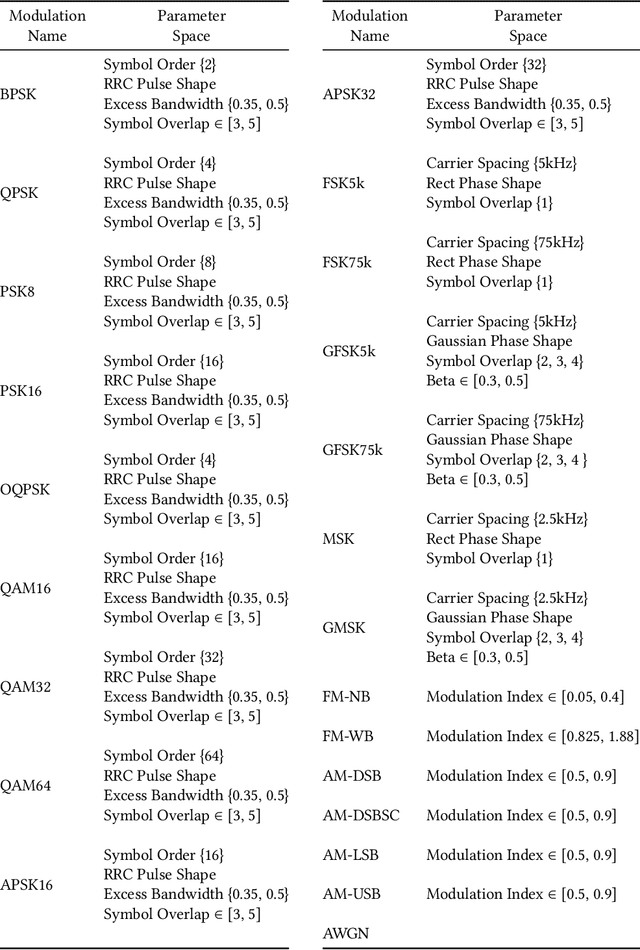
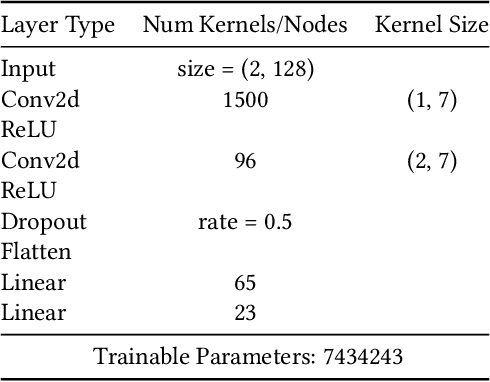
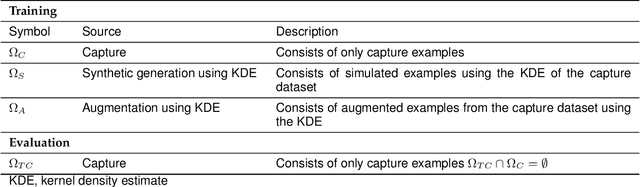
Applications of machine learning are subject to three major components that contribute to the final performance metrics. Within the specifics of neural networks, and deep learning specifically, the first two are the architecture for the model being trained and the training approach used. This work focuses on the third component, the data being used during training. The questions that arise are then "what is in the data" and "what within the data matters?" Looking into the Radio Frequency Machine Learning (RFML) field of Modulation Classification, the use of synthetic, captured, and augmented data are examined and compared to provide insights about the quantity and quality of the available data presented. In general, all three data types have useful contributions to a final application, but captured data germane to the intended use case will always provide more significant information and enable the greatest performance. Despite the benefit of captured data, the difficulties that arise from collection often make the quantity of data needed to achieve peak performance impractical. This paper helps quantify the balance between real and synthetic data, offering concrete examples where training data is parametrically varied in size and source.