 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Data Augmentation for Deep Learning RF Systems
Oct 19, 2020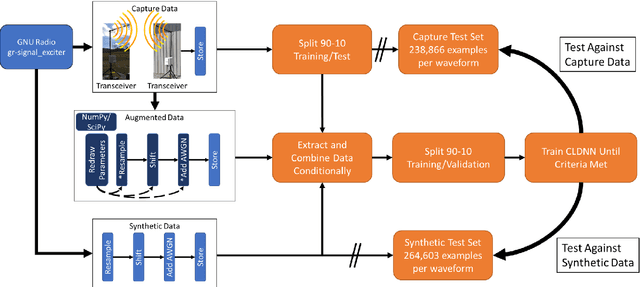
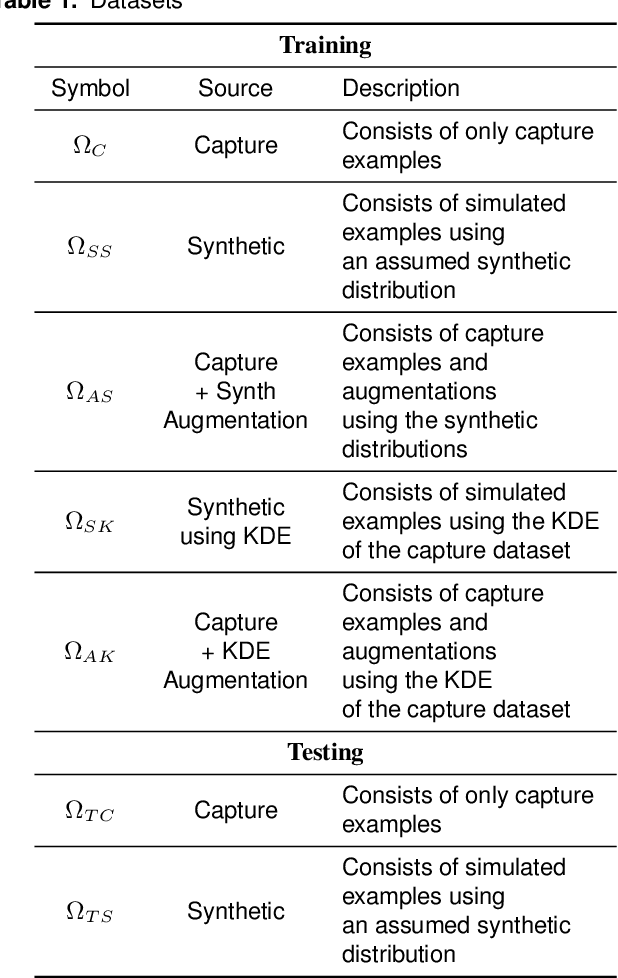
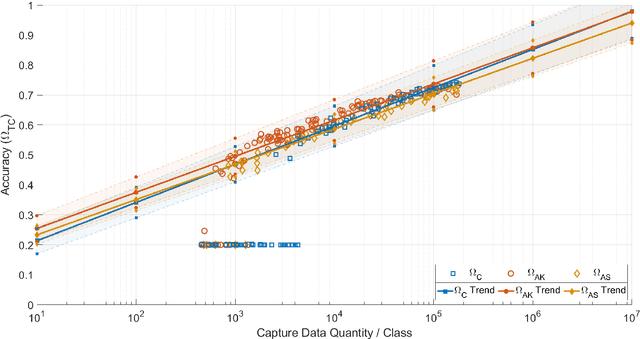

Applications of machine learning are subject to three major components that contribute to the final performance metrics. Within the specifics of neural networks, and deep learning specifically, the first two are the architecture for the model being trained and the training approach used. This work focuses on the third component, the data being used during training. The questions that arise are then "what is in the data" and "what within the data matters?" Looking into the Radio Frequency Machine Learning (RFML) field of Modulation Classification, the use of synthetic, captured, and augmented data are examined and compared to provide insights about the quantity and quality of the available data presented. In general, all three data types have useful contributions to a final application, but captured data germane to the intended use case will always provide more significant information and enable the greatest performance. Despite the benefit of captured data, the difficulties that arise from collection often make the quantity of data needed to achieve peak performance impractical. This paper helps quantify the balance between real and synthetic data, offering concrete examples where training data is parametrically varied in size and source.