 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Modulation Classification using a Waveform Signature
Apr 01, 2024Cognitive Radios (CRs) build upon Software Defined Radios (SDRs) to allow for autonomous reconfiguration of communication architectures. In recent years, CRs have been identified as an enabler for Dynamic Spectrum Access (DSA) applications in which secondary users opportunistically share licensed spectrum. A major challenge for DSA is accurately characterizing the spectral environment, which requires blind signal classification. Existing work in this area has focused on simplistic channel models; however, more challenging fading channels (e.g., frequency selective fading channels) cause existing methods to be computationally complex or insufficient. This paper develops a novel blind modulation classification algorithm, which uses a set of higher order statistics to overcome these challenges. The set of statistics forms a signature, which can either be used directly for classification or can be processed using big data analytical techniques, such as principle component analysis (PCA), to learn the environment. The algorithm is tested in simulation on both flat fading and selective fading channel models. Results of this blind classification algorithm are shown to improve upon those which use single value higher order statistical methods.
Quantifying and Extrapolating Data Needs in Radio Frequency Machine Learning
May 07, 2022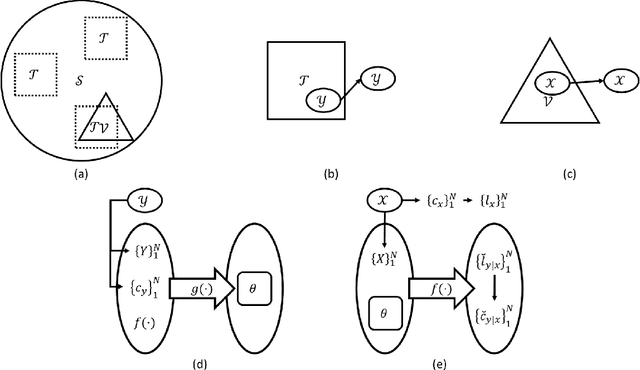

Understanding the relationship between training data and a model's performance once deployed is a fundamental component in the application of machine learning. While the model's deployed performance is dependent on numerous variables within the scope of machine learning, beyond that of the training data itself, the effect of the dataset is isolated in this work to better understand the role training data plays in the problem. This work examines a modulation classification problem in the Radio Frequency domain space, attempting to answer the question of how much training data is required to achieve a desired level of performance, but the procedure readily applies to classification problems across modalities. By repurposing the metrics of transfer potential developed within transfer learning an approach to bound data quantity needs developed given a training approach and machine learning architecture; this approach is presented as a means to estimate data quantity requirements to achieve a target performance. While this approach will require an initial dataset that is germane to the problem space to act as a target dataset on which metrics are extracted, the goal is to allow for the initial data to be orders of magnitude smaller than what is required for delivering a system that achieves the desired performance. An additional benefit of the techniques presented here is that the quality of different datasets can be numerically evaluated and tied together with the quantity of data, and the performance of the system.
Training Data Augmentation for Deep Learning RF Systems
Oct 19, 2020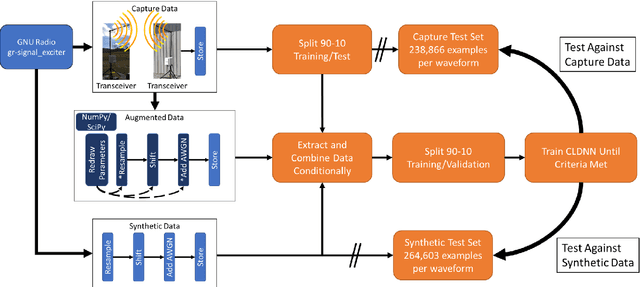
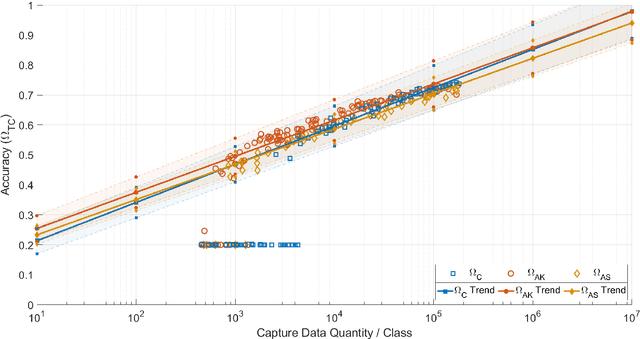

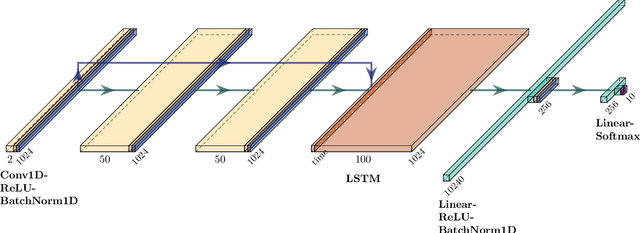
Applications of machine learning are subject to three major components that contribute to the final performance metrics. Within the specifics of neural networks, and deep learning specifically, the first two are the architecture for the model being trained and the training approach used. This work focuses on the third component, the data being used during training. The questions that arise are then "what is in the data" and "what within the data matters?" Looking into the Radio Frequency Machine Learning (RFML) field of Modulation Classification, the use of synthetic, captured, and augmented data are examined and compared to provide insights about the quantity and quality of the available data presented. In general, all three data types have useful contributions to a final application, but captured data germane to the intended use case will always provide more significant information and enable the greatest performance. Despite the benefit of captured data, the difficulties that arise from collection often make the quantity of data needed to achieve peak performance impractical. This paper helps quantify the balance between real and synthetic data, offering concrete examples where training data is parametrically varied in size and source.