 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpaceNet 6: Multi-Sensor All Weather Mapping Dataset
Apr 14, 2020
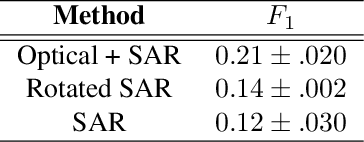


Within the remote sensing domain, a diverse set of acquisition modalities exist, each with their own unique strengths and weaknesses. Yet, most of the current literature and open datasets only deal with electro-optical (optical) data for different detection and segmentation tasks at high spatial resolutions. optical data is often the preferred choice for geospatial applications, but requires clear skies and little cloud cover to work well. Conversely, Synthetic Aperture Radar (SAR) sensors have the unique capability to penetrate clouds and collect during all weather, day and night conditions. Consequently, SAR data are particularly valuable in the quest to aid disaster response, when weather and cloud cover can obstruct traditional optical sensors. Despite all of these advantages, there is little open data available to researchers to explore the effectiveness of SAR for such applications, particularly at very-high spatial resolutions, i.e. <1m Ground Sample Distance (GSD). To address this problem, we present an open Multi-Sensor All Weather Mapping (MSAW) dataset and challenge, which features two collection modalities (both SAR and optical). The dataset and challenge focus on mapping and building footprint extraction using a combination of these data sources. MSAW covers 120 km^2 over multiple overlapping collects and is annotated with over 48,000 unique building footprints labels, enabling the creation and evaluation of mapping algorithms for multi-modal data. We present a baseline and benchmark for building footprint extraction with SAR data and find that state-of-the-art segmentation models pre-trained on optical data, and then trained on SAR (F1 score of 0.21) outperform those trained on SAR data alone (F1 score of 0.135).
SpaceNet MVOI: a Multi-View Overhead Imagery Dataset
Mar 28, 2019
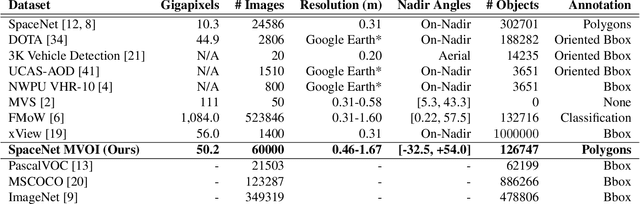
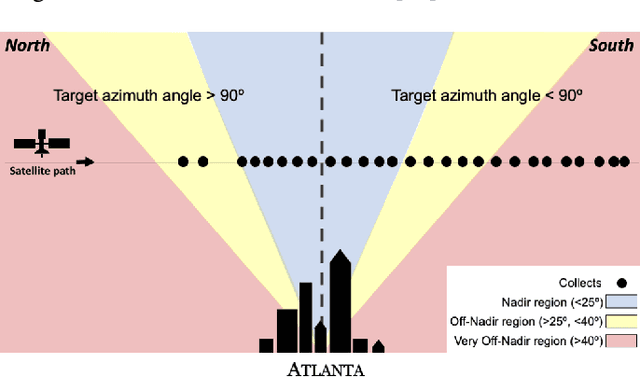

Detection and segmentation of objects in overheard imagery is a challenging task. The variable density, random orientation, small size, and instance-to-instance heterogeneity of objects in overhead imagery calls for approaches distinct from existing models designed for natural scene datasets. Though new overhead imagery datasets are being developed, they almost universally comprise a single view taken from directly overhead ("at nadir"), failing to address one critical variable: look angle. By contrast, views vary in real-world overhead imagery, particularly in dynamic scenarios such as natural disasters where first looks are often over 40 degrees off-nadir. This represents an important challenge to computer vision methods, as changing view angle adds distortions, alters resolution, and changes lighting. At present, the impact of these perturbations for algorithmic detection and segmentation of objects is untested. To address this problem, we introduce the SpaceNet Multi-View Overhead Imagery (MVOI) Dataset, an extension of the SpaceNet open source remote sensing dataset. MVOI comprises 27 unique looks from a broad range of viewing angles (-32 to 54 degrees). Each of these images cover the same geography and are annotated with 126,747 building footprint labels, enabling direct assessment of the impact of viewpoint perturbation on model performance. We benchmark multiple leading segmentation and object detection models on: (1) building detection, (2) generalization to unseen viewing angles and resolutions, and (3) sensitivity of building footprint extraction to changes in resolution. We find that segmentation and object detection models struggle to identify buildings in off-nadir imagery and generalize poorly to unseen views, presenting an important benchmark to explore the broadly relevant challenge of detecting small, heterogeneous target objects in visually dynamic contexts.
Using Scene Graph Context to Improve Image Generation
Jan 15, 2019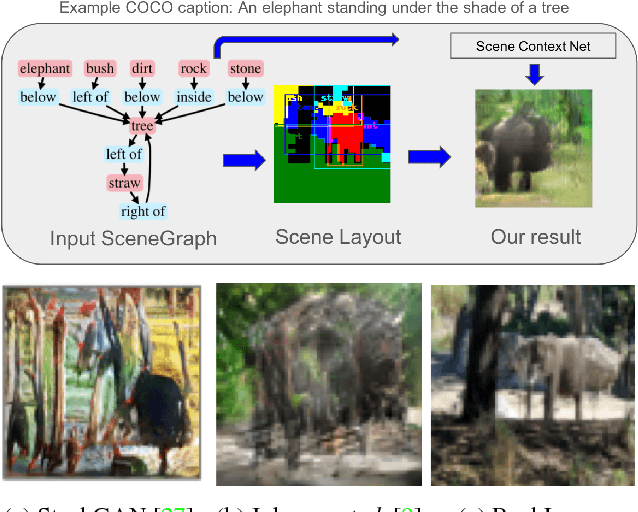

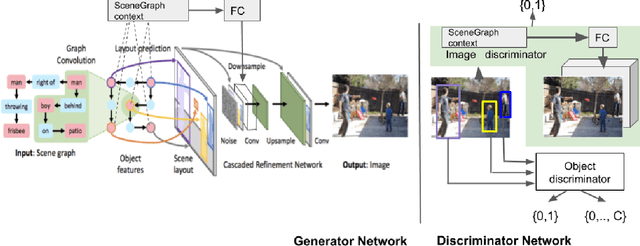

Generating realistic images from scene graphs asks neural networks to be able to reason about object relationships and compositionality. As a relatively new task, how to properly ensure the generated images comply with scene graphs or how to measure task performance remains an open question. In this paper, we propose to harness scene graph context to improve image generation from scene graphs. We introduce a scene graph context network that pools features generated by a graph convolutional neural network that are then provided to both the image generation network and the adversarial loss. With the context network, our model is trained to not only generate realistic looking images, but also to better preserve non-spatial object relationships. We also define two novel evaluation metrics, the relation score and the mean opinion relation score, for this task that directly evaluate scene graph compliance. We use both quantitative and qualitative studies to demonstrate that our pro-posed model outperforms the state-of-the-art on this challenging task.
Harassment detection: a benchmark on the #HackHarassment dataset
Sep 09, 2016Online harassment has been a problem to a greater or lesser extent since the early days of the internet. Previous work has applied anti-spam techniques like machine-learning based text classification (Reynolds, 2011) to detecting harassing messages. However, existing public datasets are limited in size, with labels of varying quality. The #HackHarassment initiative (an alliance of 1 tech companies and NGOs devoted to fighting bullying on the internet) has begun to address this issue by creating a new dataset superior to its predecssors in terms of both size and quality. As we (#HackHarassment) complete further rounds of labelling, later iterations of this dataset will increase the available samples by at least an order of magnitude, enabling corresponding improvements in the quality of machine learning models for harassment detection. In this paper, we introduce the first models built on the #HackHarassment dataset v1.0 (a new open dataset, which we are delighted to share with any interested researcherss) as a benchmark for future research.