 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Common Operating Picture Framework Leveraging Data Fusion and Deep Learning
Jan 16, 2020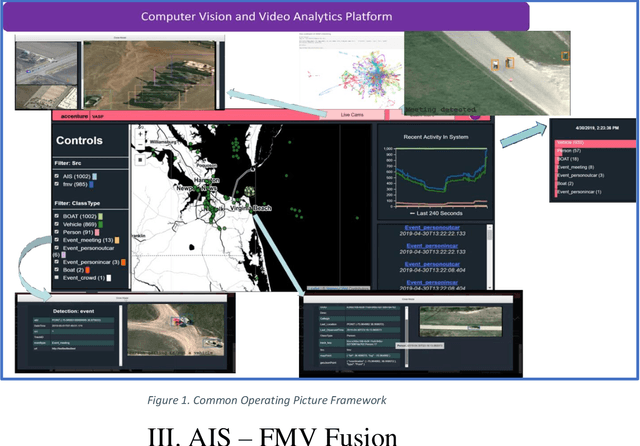
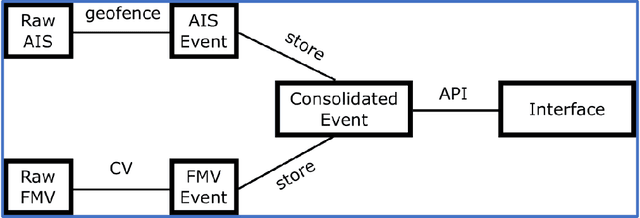
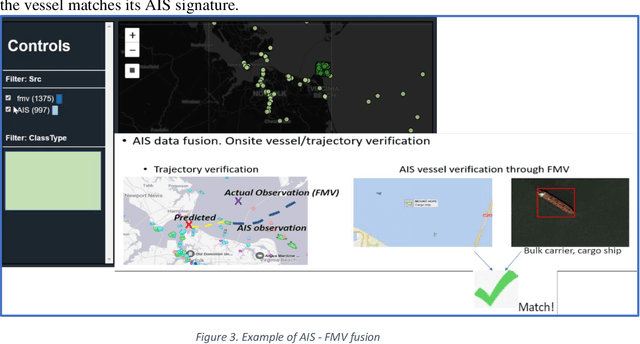

Organizations are starting to realize of the combined power of data and data-driven algorithmic models to gain insights, situational awareness, and advance their mission. A common challenge to gaining insights is connecting inherently different datasets. These datasets (e.g. geocoded features, video streams, raw text, social network data, etc.) per separate they provide very narrow answers; however collectively they can provide new capabilities. In this work, we present a data fusion framework for accelerating solutions for Processing, Exploitation, and Dissemination (PED). Our platform is a collection of services that extract information from several data sources (per separate) by leveraging deep learning and other means of processing. This information is fused by a set of analytical engines that perform data correlations, searches, and other modeling operations to combine information from the disparate data sources. As a result, events of interest are detected, geolocated, logged, and presented into a common operating picture. This common operating picture allows the user to visualize in real time all the data sources, per separate and their collective cooperation. In addition, forensic activities have been implemented and made available through the framework. Users can review archived results and compare them to the most recent snapshot of the operational environment. In our first iteration we have focused on visual data (FMV, WAMI, CCTV/PTZ-Cameras, open source video, etc.) and AIS data streams (satellite and terrestrial sources). As a proof-of-concept, in our experiments we show how FMV detections can be combined with vessel tracking signals from AIS sources to confirm identity, tip-and-cue aerial reconnaissance, and monitor vessel activity in an area.
Contextual Sense Making by Fusing Scene Classification, Detections, and Events in Full Motion Video
Jan 16, 2020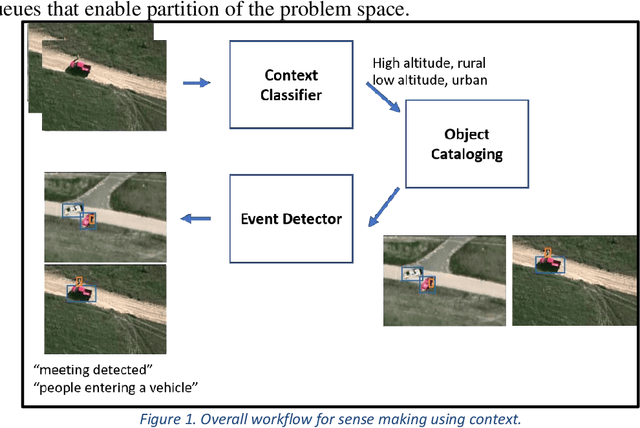
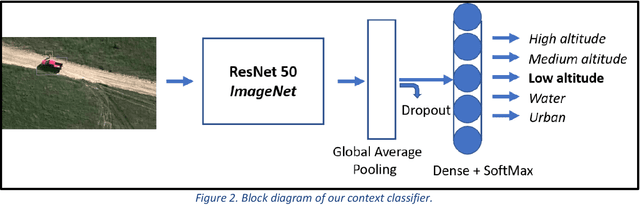
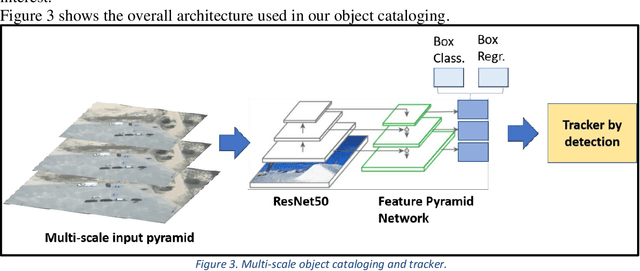

With the proliferation of imaging sensors, the volume of multi-modal imagery far exceeds the ability of human analysts to adequately consume and exploit it. Full motion video (FMV) possesses the extra challenge of containing large amounts of redundant temporal data. We aim to address the needs of human analysts to consume and exploit data given aerial FMV. We have investigated and designed a system capable of detecting events and activities of interest that deviate from the baseline patterns of observation given FMV feeds. We have divided the problem into three tasks: (1) Context awareness, (2) object cataloging, and (3) event detection. The goal of context awareness is to constraint the problem of visual search and detection in video data. A custom image classifier categorizes the scene with one or multiple labels to identify the operating context and environment. This step helps reducing the semantic search space of downstream tasks in order to increase their accuracy. The second step is object cataloging, where an ensemble of object detectors locates and labels any known objects found in the scene (people, vehicles, boats, planes, buildings, etc.). Finally, context information and detections are sent to the event detection engine to monitor for certain behaviors. A series of analytics monitor the scene by tracking object counts, and object interactions. If these object interactions are not declared to be commonly observed in the current scene, the system will report, geolocate, and log the event. Events of interest include identifying a gathering of people as a meeting and/or a crowd, alerting when there are boats on a beach unloading cargo, increased count of people entering a building, people getting in and/or out of vehicles of interest, etc. We have applied our methods on data from different sensors at different resolutions in a variety of geographical areas.
Assessing Data Quality of Annotations with Krippendorff Alpha For Applications in Computer Vision
Dec 20, 2019
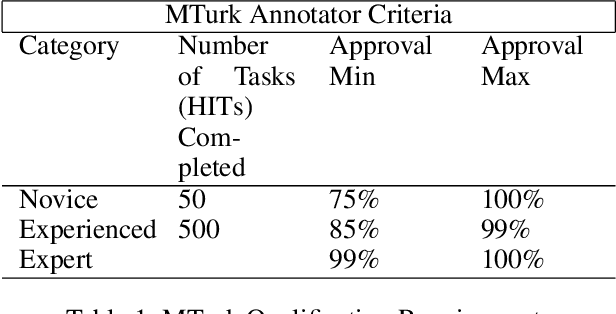
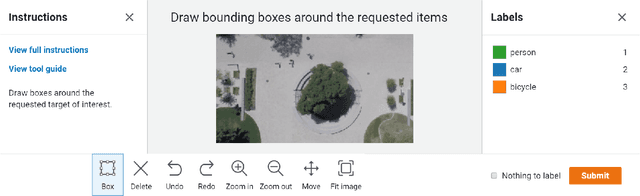
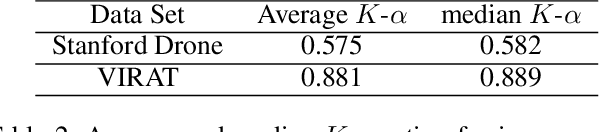
Current supervised deep learning frameworks rely on annotated data for modeling the underlying data distribution of a given task. In particular for computer vision algorithms powered by deep learning, the quality of annotated data is the most critical factor in achieving the desired algorithm performance. Data annotation is, typically, a manual process where the annotator follows guidelines and operates in a best-guess manner. Labeling criteria among annotators can show discrepancies in labeling results. This may impact the algorithm inference performance. Given the popularity and widespread use of deep learning among computer vision, more and more custom datasets are needed to train neural networks to tackle different kinds of tasks. Unfortunately, there is no full understanding of the factors that affect annotated data quality, and how it translates into algorithm performance. In this paper we studied this problem for object detection and recognition.We conducted several data annotation experiments to measure inter annotator agreement and consistency, as well as how the selection of ground truth impacts the perceived algorithm performance.We propose a methodology to monitor the quality of annotations during the labeling of images and how it can be used to measure performance. We also show that neglecting to monitor the annotation process can result in significant loss in algorithm precision. Through these experiments, we observe that knowledge of the labeling process, training data, and ground truth data used for algorithm evaluation are fundamental components to accurately assess trustworthiness of an AI system.