 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecommending Training Set Sizes for Classification
Feb 16, 2021



Based on a comprehensive study of 20 established data sets, we recommend training set sizes for any classification data set. We obtain our recommendations by systematically withholding training data and developing models through five different classification methods for each resulting training set. Based on these results, we construct accuracy confidence intervals for each training set size and fit the lower bounds to inverse power low learning curves. We also estimate a sufficient training set size (STSS) for each data set based on established convergence criteria. We compare STSS to the data sets' characteristics; based on identified trends, we recommend training set sizes between 3000 and 30000 data points, according to a data set's number of classes and number of features. Because obtaining and preparing training data has non-negligible costs that are proportional to data set size, these results afford the potential opportunity for substantial savings for predictive modeling efforts.
Improving Community Resiliency and Emergency Response With Artificial Intelligence
May 28, 2020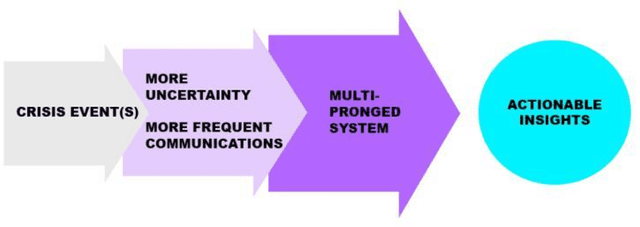
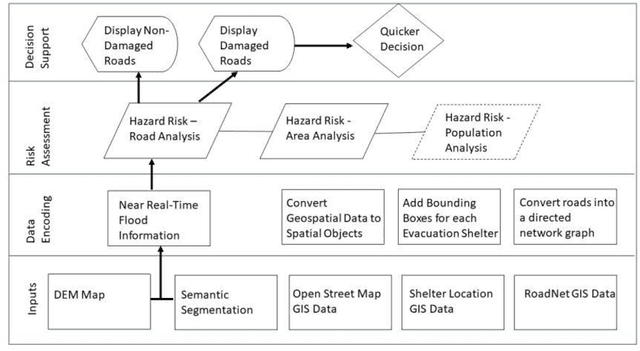
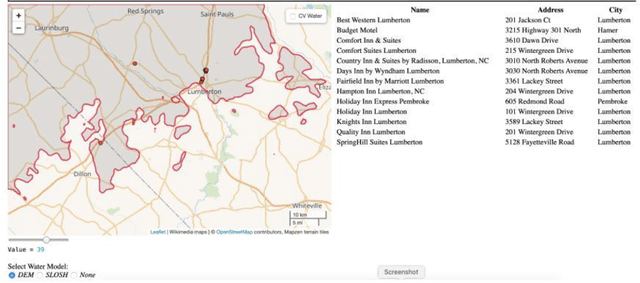

New crisis response and management approaches that incorporate the latest information technologies are essential in all phases of emergency preparedness and response, including the planning, response, recovery, and assessment phases. Accurate and timely information is as crucial as is rapid and coherent coordination among the responding organizations. We are working towards a multipronged emergency response tool that provide stakeholders timely access to comprehensive, relevant, and reliable information. The faster emergency personnel are able to analyze, disseminate and act on key information, the more effective and timelier their response will be and the greater the benefit to affected populations. Our tool consists of encoding multiple layers of open source geospatial data including flood risk location, road network strength, inundation maps that proxy inland flooding and computer vision semantic segmentation for estimating flooded areas and damaged infrastructure. These data layers are combined and used as input data for machine learning algorithms such as finding the best evacuation routes before, during and after an emergency or providing a list of available lodging for first responders in an impacted area for first. Even though our system could be used in a number of use cases where people are forced from one location to another, we demonstrate the feasibility of our system for the use case of Hurricane Florence in Lumberton, North Carolina.
AAAI FSS-19: Human-Centered AI: Trustworthiness of AI Models and Data Proceedings
Jan 15, 2020To facilitate the widespread acceptance of AI systems guiding decision-making in real-world applications, it is key that solutions comprise trustworthy, integrated human-AI systems. Not only in safety-critical applications such as autonomous driving or medicine, but also in dynamic open world systems in industry and government it is crucial for predictive models to be uncertainty-aware and yield trustworthy predictions. Another key requirement for deployment of AI at enterprise scale is to realize the importance of integrating human-centered design into AI systems such that humans are able to use systems effectively, understand results and output, and explain findings to oversight committees. While the focus of this symposium was on AI systems to improve data quality and technical robustness and safety, we welcomed submissions from broadly defined areas also discussing approaches addressing requirements such as explainable models, human trust and ethical aspects of AI.
Assessing Data Quality of Annotations with Krippendorff Alpha For Applications in Computer Vision
Dec 20, 2019
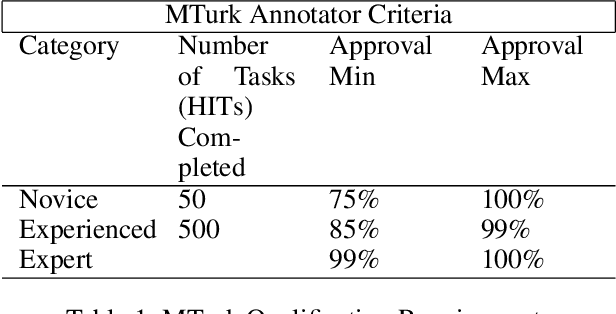
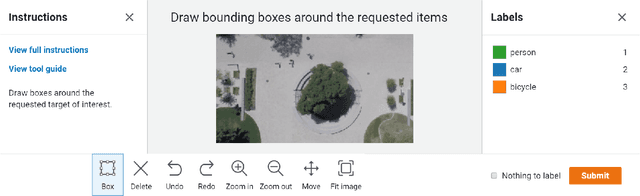
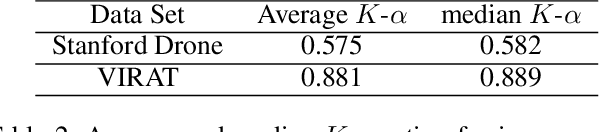
Current supervised deep learning frameworks rely on annotated data for modeling the underlying data distribution of a given task. In particular for computer vision algorithms powered by deep learning, the quality of annotated data is the most critical factor in achieving the desired algorithm performance. Data annotation is, typically, a manual process where the annotator follows guidelines and operates in a best-guess manner. Labeling criteria among annotators can show discrepancies in labeling results. This may impact the algorithm inference performance. Given the popularity and widespread use of deep learning among computer vision, more and more custom datasets are needed to train neural networks to tackle different kinds of tasks. Unfortunately, there is no full understanding of the factors that affect annotated data quality, and how it translates into algorithm performance. In this paper we studied this problem for object detection and recognition.We conducted several data annotation experiments to measure inter annotator agreement and consistency, as well as how the selection of ground truth impacts the perceived algorithm performance.We propose a methodology to monitor the quality of annotations during the labeling of images and how it can be used to measure performance. We also show that neglecting to monitor the annotation process can result in significant loss in algorithm precision. Through these experiments, we observe that knowledge of the labeling process, training data, and ground truth data used for algorithm evaluation are fundamental components to accurately assess trustworthiness of an AI system.