 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCognitive networks highlight differences and similarities in the STEM mindsets of human and LLM-simulated trainees, experts and academics
Feb 26, 2025Understanding attitudes towards STEM means quantifying the cognitive and emotional ways in which individuals, and potentially large language models too, conceptualise such subjects. This study uses behavioural forma mentis networks (BFMNs) to investigate the STEM-focused mindset, i.e. ways of associating and perceiving ideas, of 177 human participants and 177 artificial humans simulated by GPT-3.5. Participants were split in 3 groups - trainees, experts and academics - to compare the influence of expertise level on their mindset. The results revealed that human forma mentis networks exhibited significantly higher clustering coefficients compared to GPT-3.5, indicating that human mindsets displayed a tendency to form and close triads of conceptual associations while recollecting STEM ideas. Human experts, in particular, demonstrated robust clustering coefficients, reflecting better integration of STEM concepts into their cognitive networks. In contrast, GPT-3.5 produced sparser mindsets. Furthermore, both human and GPT mindsets framed mathematics in neutral or positive terms, differently from STEM high schoolers, researchers and other large language models sampled in other works. This research contributes to understanding how mindset structure can provide cognitive insights about memory structure and machine limitations.
Assessing high-order effects in feature importance via predictability decomposition
Dec 13, 2024



Leveraging the large body of work devoted in recent years to describe redundancy and synergy in multivariate interactions among random variables, we propose a novel approach to quantify cooperative effects in feature importance, one of the most used techniques for explainable artificial intelligence. In particular, we propose an adaptive version of a well-known metric of feature importance, named Leave One Covariate Out (LOCO), to disentangle high-order effects involving a given input feature in regression problems. LOCO is the reduction of the prediction error when the feature under consideration is added to the set of all the features used for regression. Instead of calculating the LOCO using all the features at hand, as in its standard version, our method searches for the multiplet of features that maximize LOCO and for the one that minimize it. This provides a decomposition of the LOCO as the sum of a two-body component and higher-order components (redundant and synergistic), also highlighting the features that contribute to building these high-order effects alongside the driving feature. We report the application to proton/pion discrimination from simulated detector measures by GEANT.
Information-Theoretic Progress Measures reveal Grokking is an Emergent Phase Transition
Aug 16, 2024This paper studies emergent phenomena in neural networks by focusing on grokking where models suddenly generalize after delayed memorization. To understand this phase transition, we utilize higher-order mutual information to analyze the collective behavior (synergy) and shared properties (redundancy) between neurons during training. We identify distinct phases before grokking allowing us to anticipate when it occurs. We attribute grokking to an emergent phase transition caused by the synergistic interactions between neurons as a whole. We show that weight decay and weight initialization can enhance the emergent phase.
Large language models surpass human experts in predicting neuroscience results
Mar 14, 2024Scientific discoveries often hinge on synthesizing decades of research, a task that potentially outstrips human information processing capacities. Large language models (LLMs) offer a solution. LLMs trained on the vast scientific literature could potentially integrate noisy yet interrelated findings to forecast novel results better than human experts. To evaluate this possibility, we created BrainBench, a forward-looking benchmark for predicting neuroscience results. We find that LLMs surpass experts in predicting experimental outcomes. BrainGPT, an LLM we tuned on the neuroscience literature, performed better yet. Like human experts, when LLMs were confident in their predictions, they were more likely to be correct, which presages a future where humans and LLMs team together to make discoveries. Our approach is not neuroscience-specific and is transferable to other knowledge-intensive endeavors.
Predicting aging-related decline in physical performance with sparse electrophysiological source imaging
Jul 20, 2023



Objective: We introduce a methodology for selecting biomarkers from activation and connectivity derived from Electrophysiological Source Imaging (ESI). Specifically, we pursue the selection of stable biomarkers associated with cognitive decline based on source activation and connectivity patterns of resting-state EEG theta rhythm, used as predictors of physical performance decline in aging individuals measured by a Gait Speed (GS) slowing. Methods: Our two-step methodology involves estimating ESI using flexible sparse-smooth-nonnegative models, from which activation ESI (aESI) and connectivity ESI (cESI) features are derived. The Stable Sparse Classifier method then selects potential biomarkers related to GS changes. Results and Conclusions: Our predictive models using aESI outperform traditional methods such as the LORETA family. The models combining aESI and cESI features provide the best prediction of GS changes. Potential biomarkers from activation/connectivity patterns involve orbitofrontal and temporal cortical regions. Significance: The proposed methodology contributes to the understanding of activation and connectivity of GS-related ESI and provides features that are potential biomarkers of GS slowing. Given the known relationship between GS decline and cognitive impairment, this preliminary work opens novel paths to predict the progression of healthy and pathological aging and might allow an ESI-based evaluation of rehabilitation programs.
Higher-order mutual information reveals synergistic sub-networks for multi-neuron importance
Nov 08, 2022

Quantifying which neurons are important with respect to the classification decision of a trained neural network is essential for understanding their inner workings. Previous work primarily attributed importance to individual neurons. In this work, we study which groups of neurons contain synergistic or redundant information using a multivariate mutual information method called the O-information. We observe the first layer is dominated by redundancy suggesting general shared features (i.e. detecting edges) while the last layer is dominated by synergy indicating local class-specific features (i.e. concepts). Finally, we show the O-information can be used for multi-neuron importance. This can be demonstrated by re-training a synergistic sub-network, which results in a minimal change in performance. These results suggest our method can be used for pruning and unsupervised representation learning.
Cognitive modelling with multilayer networks: Insights, advancements and future challenges
Oct 02, 2022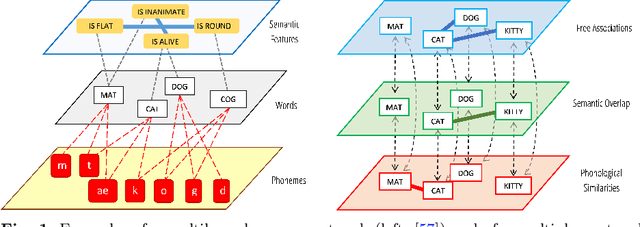
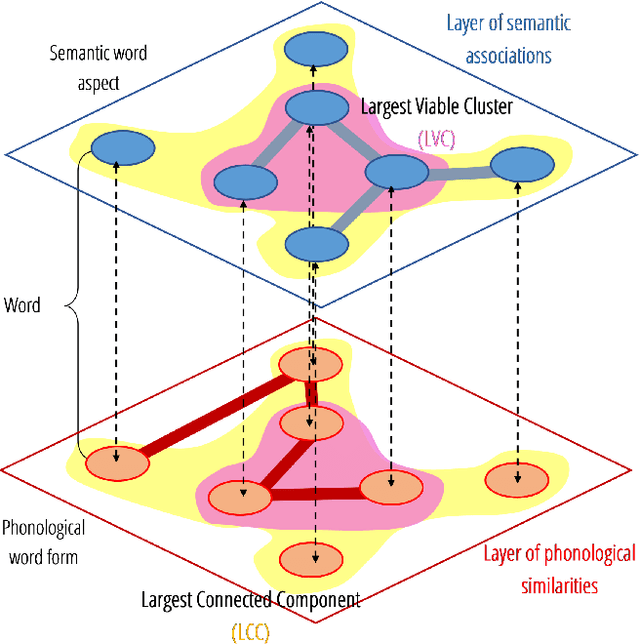
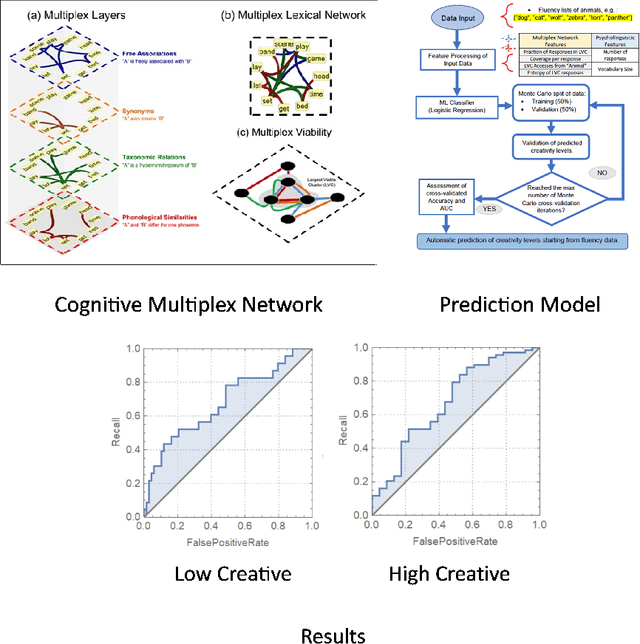
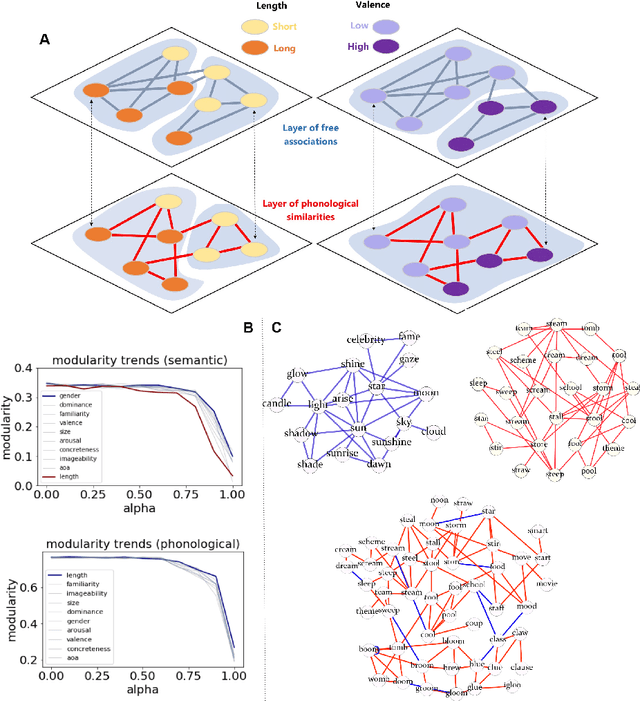
The mental lexicon is a complex cognitive system representing information about the words/concepts that one knows. Decades of psychological experiments have shown that conceptual associations across multiple, interactive cognitive levels can greatly influence word acquisition, storage, and processing. How can semantic, phonological, syntactic, and other types of conceptual associations be mapped within a coherent mathematical framework to study how the mental lexicon works? We here review cognitive multilayer networks as a promising quantitative and interpretative framework for investigating the mental lexicon. Cognitive multilayer networks can map multiple types of information at once, thus capturing how different layers of associations might co-exist within the mental lexicon and influence cognitive processing. This review starts with a gentle introduction to the structure and formalism of multilayer networks. We then discuss quantitative mechanisms of psychological phenomena that could not be observed in single-layer networks and were only unveiled by combining multiple layers of the lexicon: (i) multiplex viability highlights language kernels and facilitative effects of knowledge processing in healthy and clinical populations; (ii) multilayer community detection enables contextual meaning reconstruction depending on psycholinguistic features; (iii) layer analysis can mediate latent interactions of mediation, suppression and facilitation for lexical access. By outlining novel quantitative perspectives where multilayer networks can shed light on cognitive knowledge representations, also in next-generation brain/mind models, we discuss key limitations and promising directions for cutting-edge future research.
Nonlinear parametric model for Granger causality of time series
Feb 07, 2006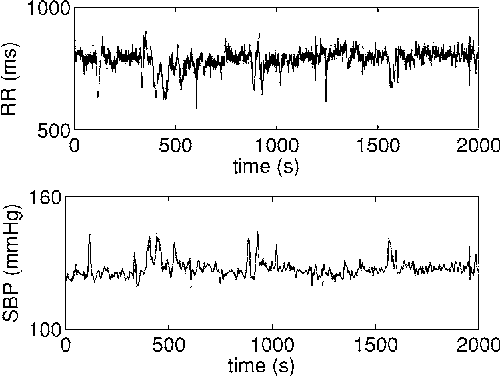
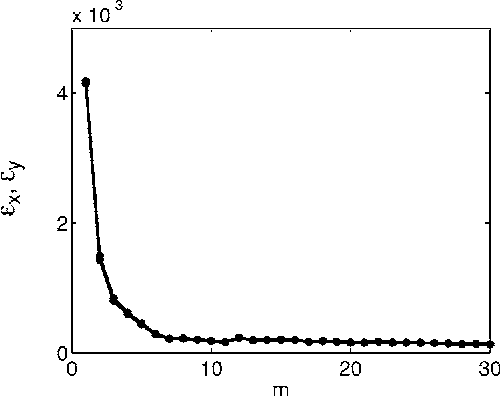

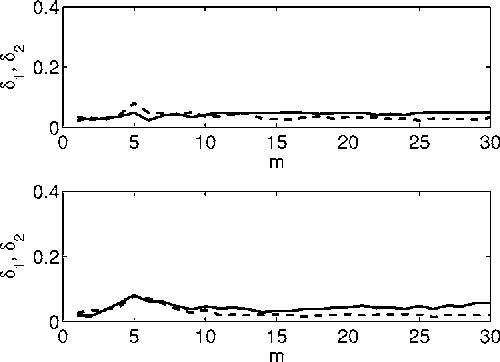
We generalize a previously proposed approach for nonlinear Granger causality of time series, based on radial basis function. The proposed model is not constrained to be additive in variables from the two time series and can approximate any function of these variables, still being suitable to evaluate causality. Usefulness of this measure of causality is shown in a physiological example and in the study of the feed-back loop in a model of excitatory and inhibitory neurons.