 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to predict creativity ratings from written narratives: A comparison of co-occurrence and textual forma mentis networks
Jan 12, 2026This tutorial paper provides a step-by-step workflow for building and analysing semantic networks from short creative texts. We introduce and compare two widely used text-to-network approaches: word co-occurrence networks and textual forma mentis networks (TFMNs). We also demonstrate how they can be used in machine learning to predict human creativity ratings. Using a corpus of 1029 short stories, we guide readers through text preprocessing, network construction, feature extraction (structural measures, spreading-activation indices, and emotion scores), and application of regression models. We evaluate how network-construction choices influence both network topology and predictive performance. Across all modelling settings, TFMNs consistently outperformed co-occurrence networks through lower prediction errors (best MAE = 0.581 for TFMN, vs 0.592 for co-occurrence with window size 3). Network-structural features dominated predictive performance (MAE = 0.591 for TFMN), whereas emotion features performed worse (MAE = 0.711 for TFMN) and spreading-activation measures contributed little (MAE = 0.788 for TFMN). This paper offers practical guidance for researchers interested in applying network-based methods for cognitive fields like creativity research. we show when syntactic networks are preferable to surface co-occurrence models, and provide an open, reproducible workflow accessible to newcomers in the field, while also offering deeper methodological insight for experienced researchers.
Cognitive networks highlight differences and similarities in the STEM mindsets of human and LLM-simulated trainees, experts and academics
Feb 26, 2025Understanding attitudes towards STEM means quantifying the cognitive and emotional ways in which individuals, and potentially large language models too, conceptualise such subjects. This study uses behavioural forma mentis networks (BFMNs) to investigate the STEM-focused mindset, i.e. ways of associating and perceiving ideas, of 177 human participants and 177 artificial humans simulated by GPT-3.5. Participants were split in 3 groups - trainees, experts and academics - to compare the influence of expertise level on their mindset. The results revealed that human forma mentis networks exhibited significantly higher clustering coefficients compared to GPT-3.5, indicating that human mindsets displayed a tendency to form and close triads of conceptual associations while recollecting STEM ideas. Human experts, in particular, demonstrated robust clustering coefficients, reflecting better integration of STEM concepts into their cognitive networks. In contrast, GPT-3.5 produced sparser mindsets. Furthermore, both human and GPT mindsets framed mathematics in neutral or positive terms, differently from STEM high schoolers, researchers and other large language models sampled in other works. This research contributes to understanding how mindset structure can provide cognitive insights about memory structure and machine limitations.
Forma mentis networks predict creativity ratings of short texts via interpretable artificial intelligence in human and GPT-simulated raters
Nov 30, 2024
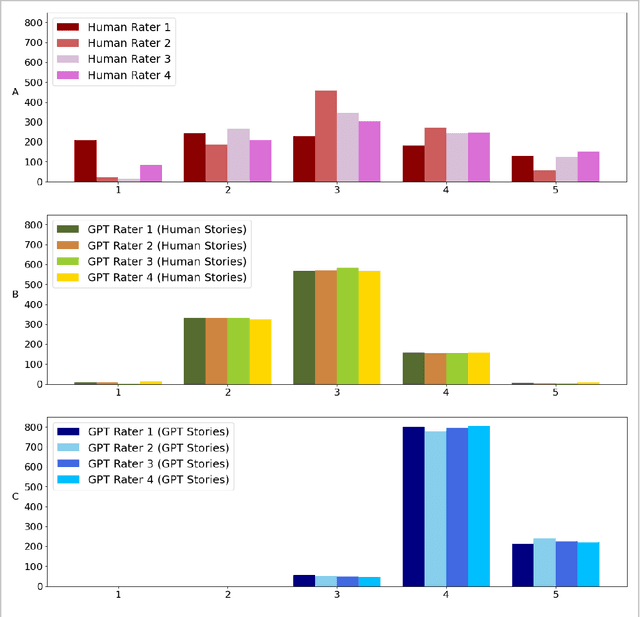
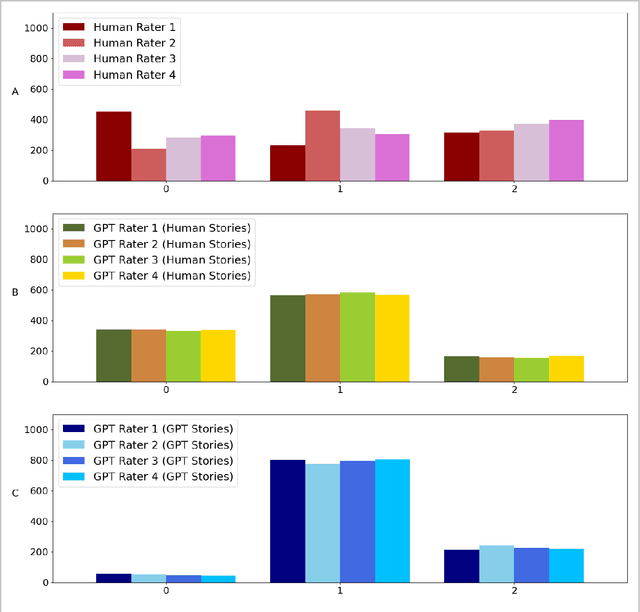
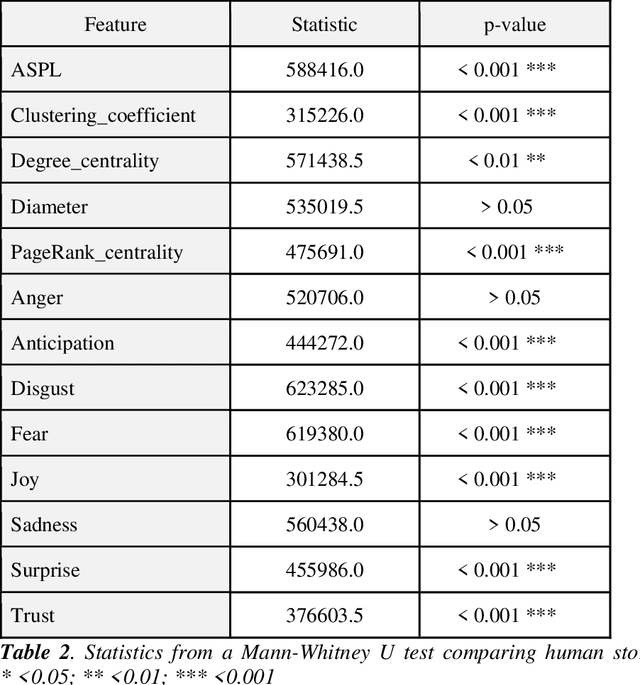
Creativity is a fundamental skill of human cognition. We use textual forma mentis networks (TFMN) to extract network (semantic/syntactic associations) and emotional features from approximately one thousand human- and GPT3.5-generated stories. Using Explainable Artificial Intelligence (XAI), we test whether features relative to Mednick's associative theory of creativity can explain creativity ratings assigned by humans and GPT-3.5. Using XGBoost, we examine three scenarios: (i) human ratings of human stories, (ii) GPT-3.5 ratings of human stories, and (iii) GPT-3.5 ratings of GPT-generated stories. Our findings reveal that GPT-3.5 ratings differ significantly from human ratings not only in terms of correlations but also because of feature patterns identified with XAI methods. GPT-3.5 favours 'its own' stories and rates human stories differently from humans. Feature importance analysis with SHAP scores shows that: (i) network features are more predictive for human creativity ratings but also for GPT-3.5's ratings of human stories; (ii) emotional features played a greater role than semantic/syntactic network structure in GPT-3.5 rating its own stories. These quantitative results underscore key limitations in GPT-3.5's ability to align with human assessments of creativity. We emphasise the need for caution when using GPT-3.5 to assess and generate creative content, as it does not yet capture the nuanced complexity that characterises human creativity.