 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCognitive modelling with multilayer networks: Insights, advancements and future challenges
Oct 02, 2022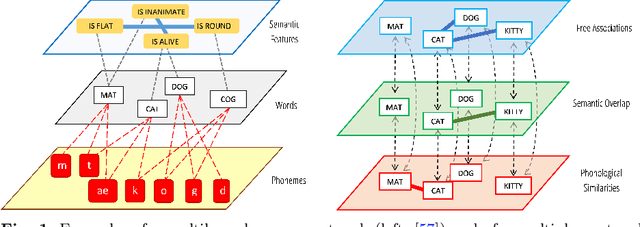
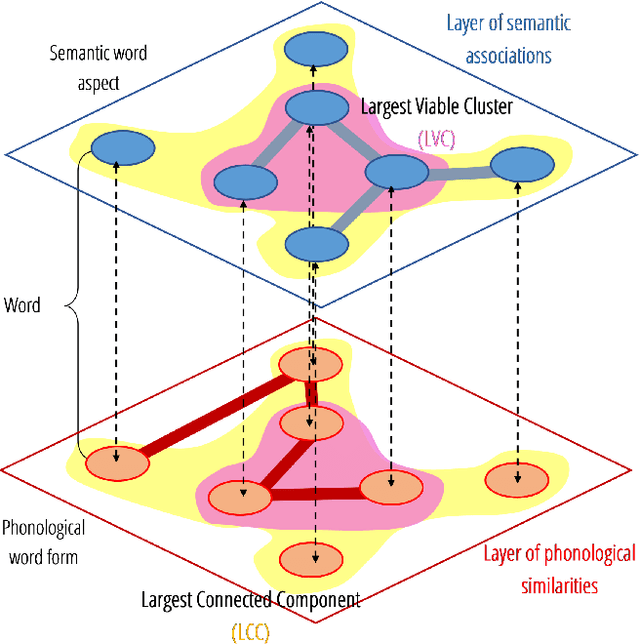
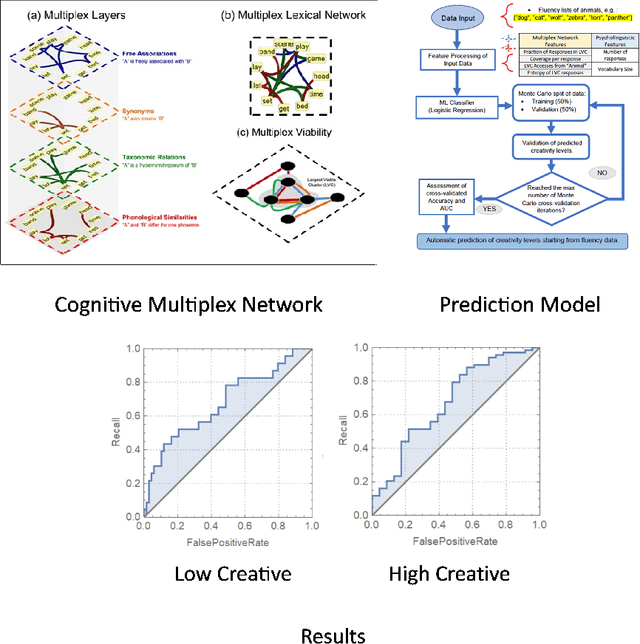
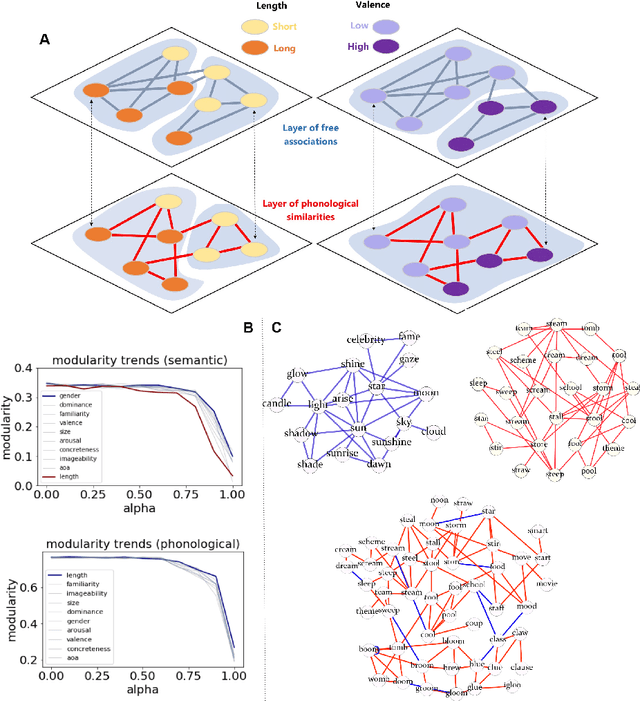
The mental lexicon is a complex cognitive system representing information about the words/concepts that one knows. Decades of psychological experiments have shown that conceptual associations across multiple, interactive cognitive levels can greatly influence word acquisition, storage, and processing. How can semantic, phonological, syntactic, and other types of conceptual associations be mapped within a coherent mathematical framework to study how the mental lexicon works? We here review cognitive multilayer networks as a promising quantitative and interpretative framework for investigating the mental lexicon. Cognitive multilayer networks can map multiple types of information at once, thus capturing how different layers of associations might co-exist within the mental lexicon and influence cognitive processing. This review starts with a gentle introduction to the structure and formalism of multilayer networks. We then discuss quantitative mechanisms of psychological phenomena that could not be observed in single-layer networks and were only unveiled by combining multiple layers of the lexicon: (i) multiplex viability highlights language kernels and facilitative effects of knowledge processing in healthy and clinical populations; (ii) multilayer community detection enables contextual meaning reconstruction depending on psycholinguistic features; (iii) layer analysis can mediate latent interactions of mediation, suppression and facilitation for lexical access. By outlining novel quantitative perspectives where multilayer networks can shed light on cognitive knowledge representations, also in next-generation brain/mind models, we discuss key limitations and promising directions for cutting-edge future research.
Feature-rich multiplex lexical networks reveal mental strategies of early language learning
Jan 13, 2022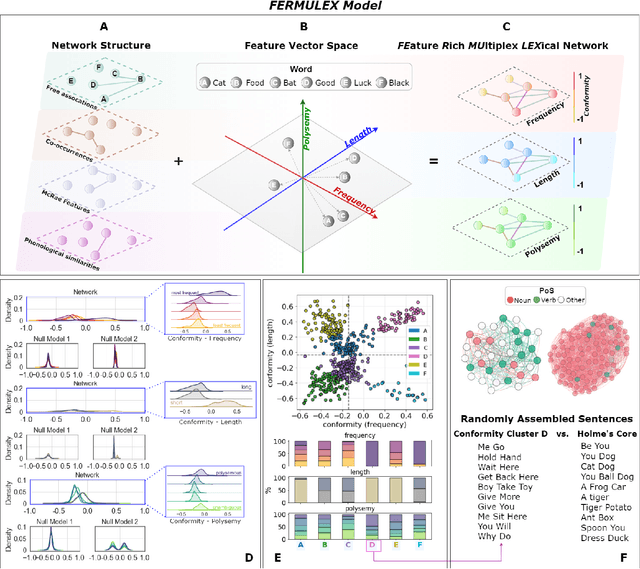
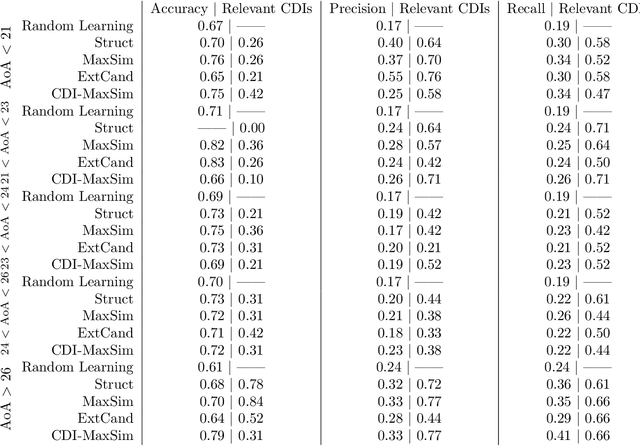
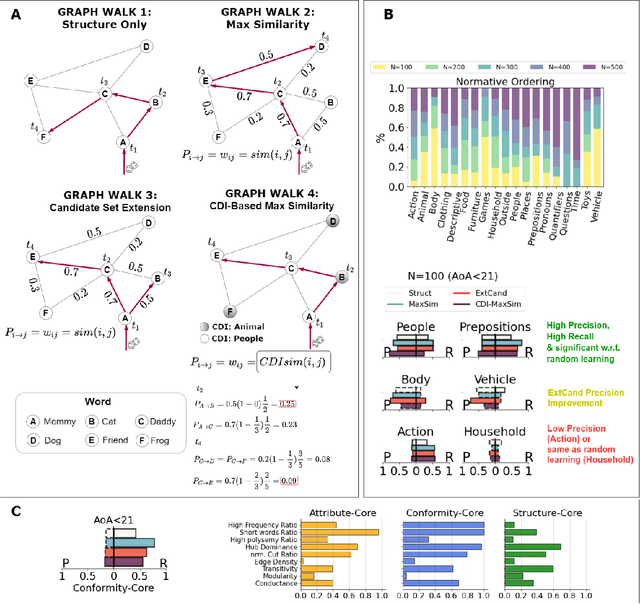
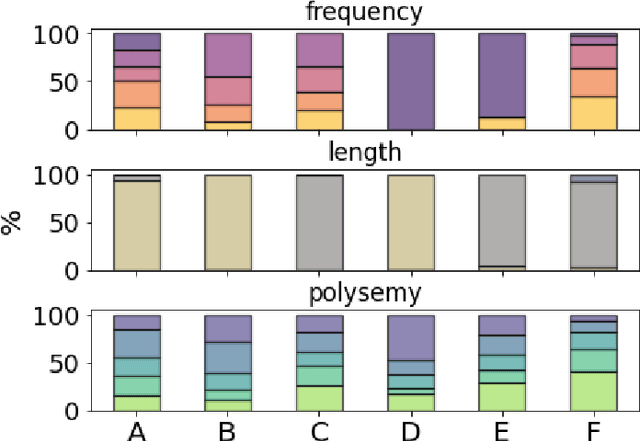
Knowledge in the human mind exhibits a dualistic vector/network nature. Modelling words as vectors is key to natural language processing, whereas networks of word associations can map the nature of semantic memory. We reconcile these paradigms - fragmented across linguistics, psychology and computer science - by introducing FEature-Rich MUltiplex LEXical (FERMULEX) networks. This novel framework merges structural similarities in networks and vector features of words, which can be combined or explored independently. Similarities model heterogenous word associations across semantic/syntactic/phonological aspects of knowledge. Words are enriched with multi-dimensional feature embeddings including frequency, age of acquisition, length and polysemy. These aspects enable unprecedented explorations of cognitive knowledge. Through CHILDES data, we use FERMULEX networks to model normative language acquisition by 1000 toddlers between 18 and 30 months. Similarities and embeddings capture word homophily via conformity, which measures assortative mixing via distance and features. Conformity unearths a language kernel of frequent/polysemous/short nouns and verbs key for basic sentence production, supporting recent evidence of children's syntactic constructs emerging at 30 months. This kernel is invisible to network core-detection and feature-only clustering: It emerges from the dual vector/network nature of words. Our quantitative analysis reveals two key strategies in early word learning. Modelling word acquisition as random walks on FERMULEX topology, we highlight non-uniform filling of communicative developmental inventories (CDIs). Conformity-based walkers lead to accurate (75%), precise (55%) and partially well-recalled (34%) predictions of early word learning in CDIs, providing quantitative support to previous empirical findings and developmental theories.
Cognitive networks identify the content of English and Italian popular posts about COVID-19 vaccines: Anticipation, logistics, conspiracy and loss of trust
Mar 29, 2021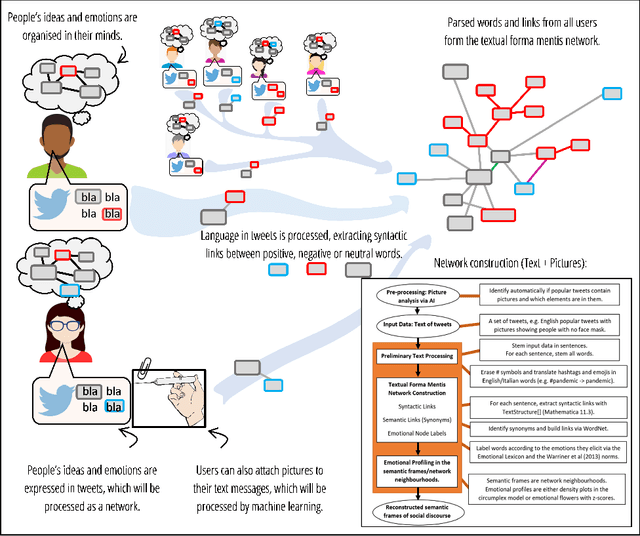
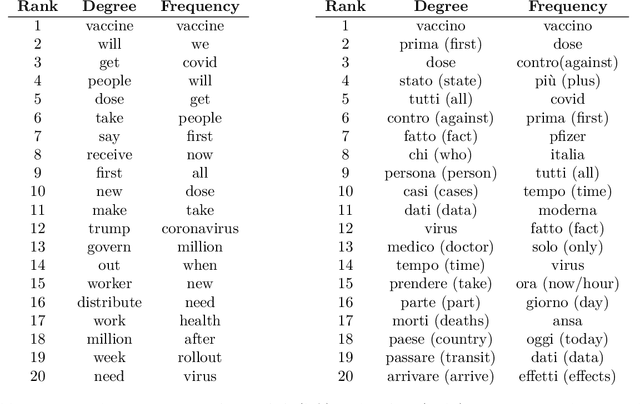
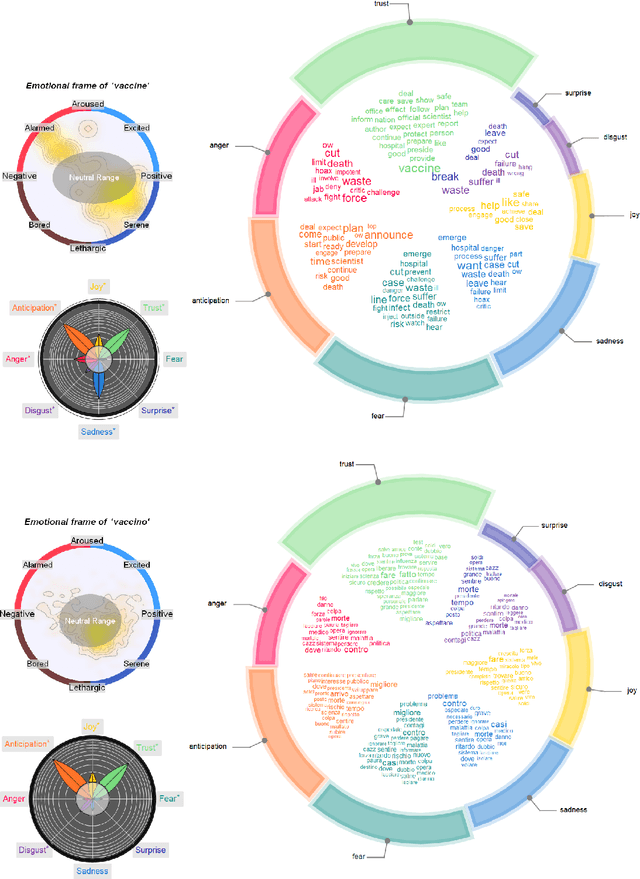
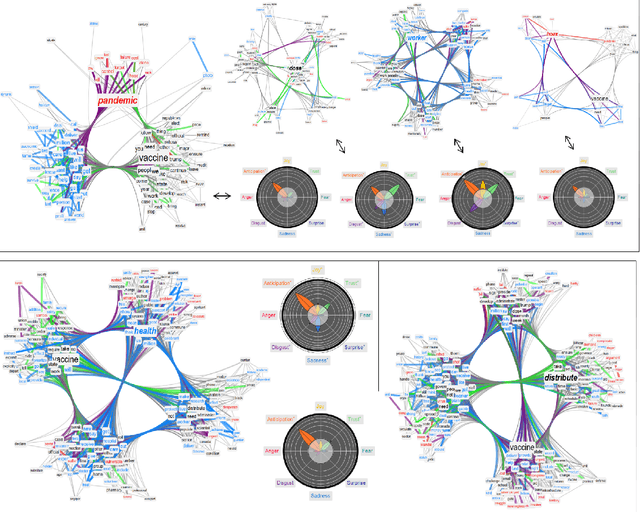
Monitoring social discourse about COVID-19 vaccines is key to understanding how large populations perceive vaccination campaigns. We focus on 4765 unique popular tweets in English or Italian about COVID-19 vaccines between 12/2020 and 03/2021. One popular English tweet was liked up to 495,000 times, stressing how popular tweets affected cognitively massive populations. We investigate both text and multimedia in tweets, building a knowledge graph of syntactic/semantic associations in messages including visual features and indicating how online users framed social discourse mostly around the logistics of vaccine distribution. The English semantic frame of "vaccine" was highly polarised between trust/anticipation (towards the vaccine as a scientific asset saving lives) and anger/sadness (mentioning critical issues with dose administering). Semantic associations with "vaccine," "hoax" and conspiratorial jargon indicated the persistence of conspiracy theories and vaccines in massively read English posts (absent in Italian messages). The image analysis found that popular tweets with images of people wearing face masks used language lacking the trust and joy found in tweets showing people with no masks, indicating a negative affect attributed to face covering in social discourse. A behavioural analysis revealed a tendency for users to share content eliciting joy, sadness and disgust and to like less sad messages, highlighting an interplay between emotions and content diffusion beyond sentiment. With the AstraZeneca vaccine being suspended in mid March 2021, "Astrazeneca" was associated with trustful language driven by experts, but popular Italian tweets framed "vaccine" by crucially replacing earlier levels of trust with deep sadness. Our results stress how cognitive networks and innovative multimedia processing open new ways for reconstructing online perceptions about vaccines and trust.
The origins of Zipf's meaning-frequency law
Dec 30, 2017In his pioneering research, G. K. Zipf observed that more frequent words tend to have more meanings, and showed that the number of meanings of a word grows as the square root of its frequency. He derived this relationship from two assumptions: that words follow Zipf's law for word frequencies (a power law dependency between frequency and rank) and Zipf's law of meaning distribution (a power law dependency between number of meanings and rank). Here we show that a single assumption on the joint probability of a word and a meaning suffices to infer Zipf's meaning-frequency law or relaxed versions. Interestingly, this assumption can be justified as the outcome of a biased random walk in the process of mental exploration.