 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCognitive Training for Language Models: Towards General Capabilities via Cross-Entropy Games
Mar 23, 2026Defining a constructive process to build general capabilities for language models in an automatic manner is considered an open problem in artificial intelligence. Towards this, we consider the problem of building a curriculum of tasks that grows a model via relevant skill discovery. We provide a concrete framework for this task, using a family of tasks called cross-entropy games, which we postulate is universal in a suitable sense. We show that if it is possible to grow the curriculum for relevant skill discovery by iterating a greedy optimization algorithm, then, under natural assumptions, there is essentially only one meta-objective possible (up to a few hyperparameters). We call the resulting process cognitive training. We postulate that, given sufficiently capable language models as players and meta-samplers and sufficient training time, cognitive training provides a principled way to relevant skill discovery; and hence to the extent general capabilities are achievable via greedy curriculum learning, cognitive training would be a solution.
Visualizing the Structure of Lenia Parameter Space
Jan 05, 2026Continuous cellular automata are rocketing in popularity, yet developing a theoretical understanding of their behaviour remains a challenge. In the case of Lenia, a few fundamental open problems include determining what exactly constitutes a soliton, what is the overall structure of the parameter space, and where do the solitons occur in it. In this abstract, we present a new method to automatically classify Lenia systems into four qualitatively different dynamical classes. This allows us to detect moving solitons, and to provide an interactive visualization of Lenia's parameter space structure on our website https://lenia-explorer.vercel.app/. The results shed new light on the above-mentioned questions and lead to several observations: the existence of new soliton families for parameters where they were not believed to exist, or the universality of the phase space structure across various kernels.
Cross-Entropy Games for Language Models: From Implicit Knowledge to General Capability Measures
Jun 07, 2025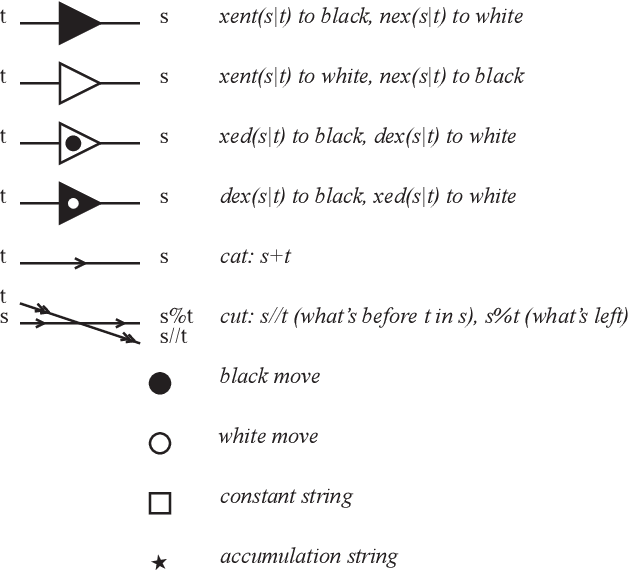
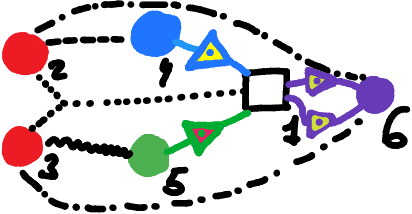
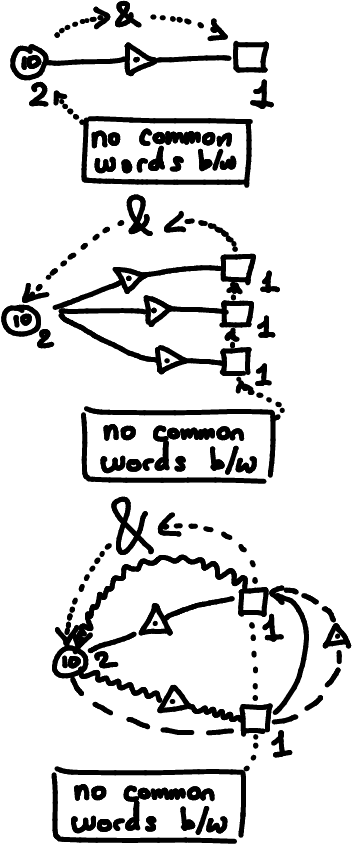
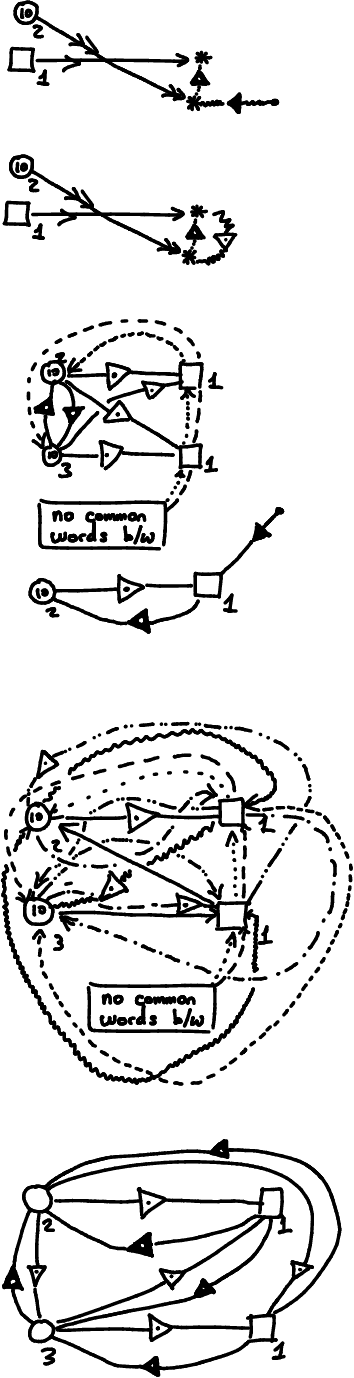
Large Language Models (LLMs) define probability measures on text. By considering the implicit knowledge question of what it means for an LLM to know such a measure and what it entails algorithmically, we are naturally led to formulate a series of tasks that go beyond generative sampling, involving forms of summarization, counterfactual thinking, anomaly detection, originality search, reverse prompting, debating, creative solving, etc. These tasks can be formulated as games based on LLM measures, which we call Cross-Entropy (Xent) Games. Xent Games can be single-player or multi-player. They involve cross-entropy scores and cross-entropy constraints, and can be expressed as simple computational graphs and programs. We show the Xent Game space is large enough to contain a wealth of interesting examples, while being constructible from basic game-theoretic consistency axioms. We then discuss how the Xent Game space can be used to measure the abilities of LLMs. This leads to the construction of Xent Game measures: finite families of Xent Games that can be used as capability benchmarks, built from a given scope, by extracting a covering measure. To address the unbounded scope problem associated with the challenge of measuring general abilities, we propose to explore the space of Xent Games in a coherent fashion, using ideas inspired by evolutionary dynamics.
Looking for Complexity at Phase Boundaries in Continuous Cellular Automata
Mar 08, 2024
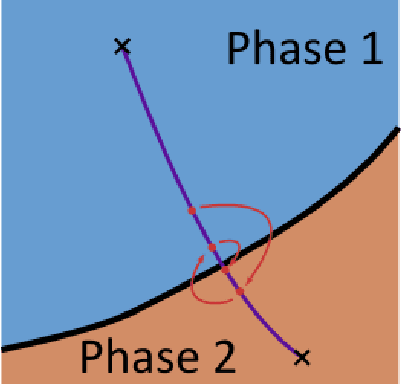
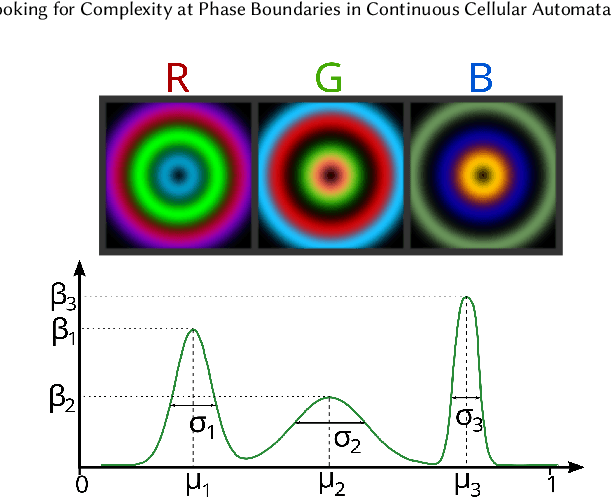
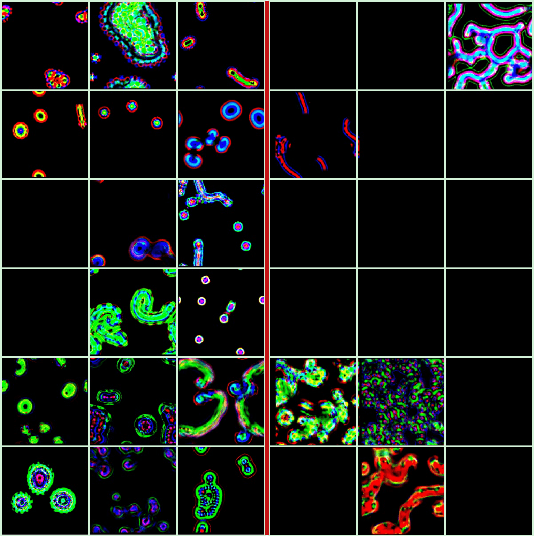
One key challenge in Artificial Life is designing systems that display an emergence of complex behaviors. Many such systems depend on a high-dimensional parameter space, only a small subset of which displays interesting dynamics. Focusing on the case of continuous systems, we introduce the 'Phase Transition Finder'(PTF) algorithm, which can be used to efficiently generate parameters lying at the border between two phases. We argue that such points are more likely to display complex behaviors, and confirm this by applying PTF to Lenia showing it can increase the frequency of interesting behaviors more than two-fold, while remaining efficient enough for large-scale searches.
Arrows of Time for Large Language Models
Jan 30, 2024We study the probabilistic modeling performed by Autoregressive Large Language Models through the angle of time directionality. We empirically find a time asymmetry exhibited by such models in their ability to model natural language: a difference in the average log-perplexity when trying to predict the next token versus when trying to predict the previous one. This difference is at the same time subtle and very consistent across various modalities (language, model size, training time, ...). Theoretically, this is surprising: from an information-theoretic point of view, there should be no such difference. We provide a theoretical framework to explain how such an asymmetry can appear from sparsity and computational complexity considerations, and outline a number of perspectives opened by our results.
Feature Learning in $L_{2}$-regularized DNNs: Attraction/Repulsion and Sparsity
May 31, 2022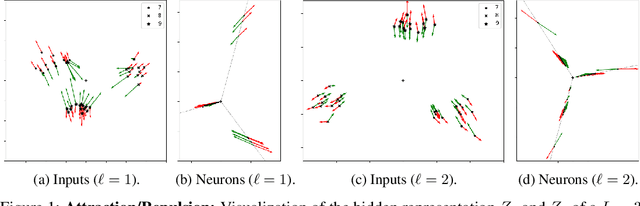

We study the loss surface of DNNs with $L_{2}$ regularization. We show that the loss in terms of the parameters can be reformulated into a loss in terms of the layerwise activations $Z_{\ell}$ of the training set. This reformulation reveals the dynamics behind feature learning: each hidden representations $Z_{\ell}$ are optimal w.r.t. to an attraction/repulsion problem and interpolate between the input and output representations, keeping as little information from the input as necessary to construct the activation of the next layer. For positively homogeneous non-linearities, the loss can be further reformulated in terms of the covariances of the hidden representations, which takes the form of a partially convex optimization over a convex cone. This second reformulation allows us to prove a sparsity result for homogeneous DNNs: any local minimum of the $L_{2}$-regularized loss can be achieved with at most $N(N+1)$ neurons in each hidden layer (where $N$ is the size of the training set). We show that this bound is tight by giving an example of a local minimum which requires $N^{2}/4$ hidden neurons. But we also observe numerically that in more traditional settings much less than $N^{2}$ neurons are required to reach the minima.
Deep Linear Networks Dynamics: Low-Rank Biases Induced by Initialization Scale and L2 Regularization
Jun 30, 2021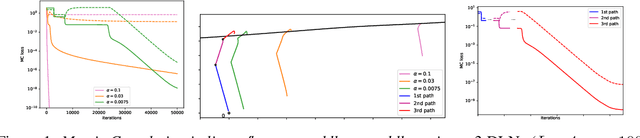

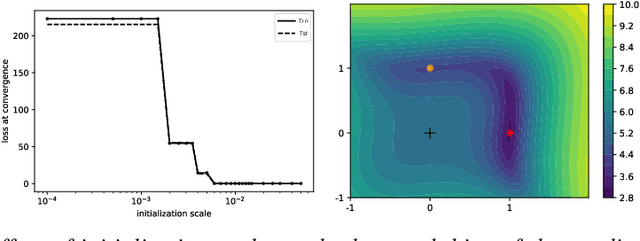
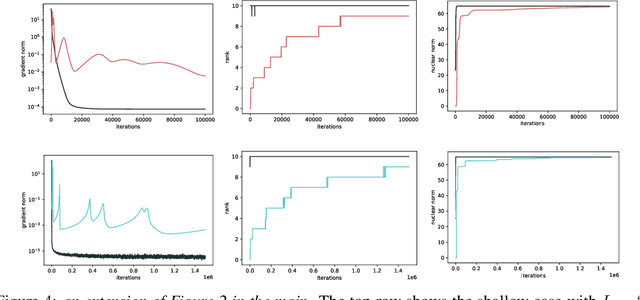
For deep linear networks (DLN), various hyperparameters alter the dynamics of training dramatically. We investigate how the rank of the linear map found by gradient descent is affected by (1) the initialization norm and (2) the addition of $L_{2}$ regularization on the parameters. For (1), we study two regimes: (1a) the linear/lazy regime, for large norm initialization; (1b) a \textquotedbl saddle-to-saddle\textquotedbl{} regime for small initialization norm. In the (1a) setting, the dynamics of a DLN of any depth is similar to that of a standard linear model, without any low-rank bias. In the (1b) setting, we conjecture that throughout training, gradient descent approaches a sequence of saddles, each corresponding to linear maps of increasing rank, until reaching a minimal rank global minimum. We support this conjecture with a partial proof and some numerical experiments. For (2), we show that adding a $L_{2}$ regularization on the parameters corresponds to the addition to the cost of a $L_{p}$-Schatten (quasi)norm on the linear map with $p=\frac{2}{L}$ (for a depth-$L$ network), leading to a stronger low-rank bias as $L$ grows. The effect of $L_{2}$ regularization on the loss surface depends on the depth: for shallow networks, all critical points are either strict saddles or global minima, whereas for deep networks, some local minima appear. We numerically observe that these local minima can generalize better than global ones in some settings.
Geometry of the Loss Landscape in Overparameterized Neural Networks: Symmetries and Invariances
May 25, 2021
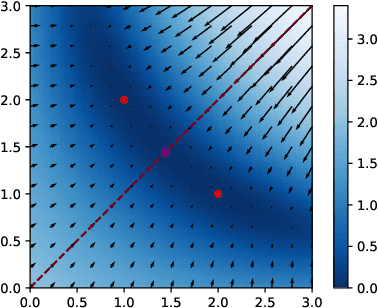
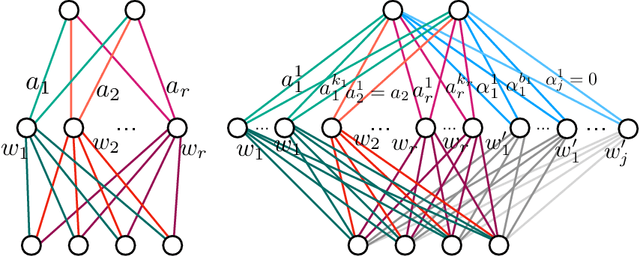
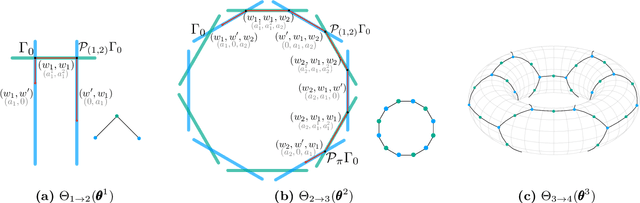
We study how permutation symmetries in overparameterized multi-layer neural networks generate `symmetry-induced' critical points. Assuming a network with $ L $ layers of minimal widths $ r_1^*, \ldots, r_{L-1}^* $ reaches a zero-loss minimum at $ r_1^*! \cdots r_{L-1}^*! $ isolated points that are permutations of one another, we show that adding one extra neuron to each layer is sufficient to connect all these previously discrete minima into a single manifold. For a two-layer overparameterized network of width $ r^*+ h =: m $ we explicitly describe the manifold of global minima: it consists of $ T(r^*, m) $ affine subspaces of dimension at least $ h $ that are connected to one another. For a network of width $m$, we identify the number $G(r,m)$ of affine subspaces containing only symmetry-induced critical points that are related to the critical points of a smaller network of width $r<r^*$. Via a combinatorial analysis, we derive closed-form formulas for $ T $ and $ G $ and show that the number of symmetry-induced critical subspaces dominates the number of affine subspaces forming the global minima manifold in the mildly overparameterized regime (small $ h $) and vice versa in the vastly overparameterized regime ($h \gg r^*$). Our results provide new insights into the minimization of the non-convex loss function of overparameterized neural networks.
Smart Proofs via Smart Contracts: Succinct and Informative Mathematical Derivations via Decentralized Markets
Feb 12, 2021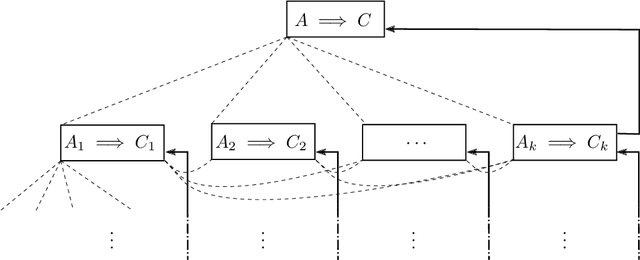
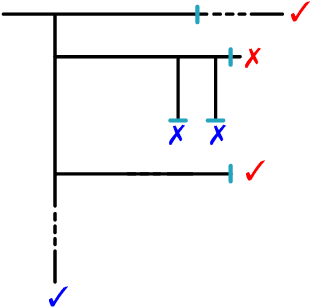
Modern mathematics is built on the idea that proofs should be translatable into formal proofs, whose validity is an objective question, decidable by a computer. Yet, in practice, proofs are informal and may omit many details. An agent considers a proof valid if they trust that it could be expanded into a machine-verifiable proof. A proof's validity can thus become a subjective matter and lead to a debate, which may be difficult to settle. Hence, while the concept of valid proof is well-defined, the process to establish validity is itself a complex multi-agent problem. We introduce the SPRIG protocol. SPRIG allows agents to propose and verify succinct and informative proofs in a decentralized fashion; the trust is established by agents being able to request more details in the proof steps; debates, if they arise, must isolate details of proofs and, if they persist, go down to machine-level details, where they are automatically settled. A structure of bounties and stakes is set to incentivize agents to act in good faith. We propose a game-theoretic discussion of SPRIG, showing how agents with various types of information interact, leading to a proof tree with an appropriate level of detail and to the invalidation of wrong proofs, and we discuss resilience against various attacks. We then analyze a simplified model, characterize its equilibria and compute the agents' level of trust. SPRIG is designed to run as a smart contract on a blockchain platform. This allows anonymous agents to participate in the verification debate, and to contribute with their information. The smart contract mediates the interactions, settles debates, and guarantees that bounties and stakes are paid as specified. SPRIG enables new applications, such as the issuance of bounties for open problems, and the creation of derivatives markets, allowing agents to inject more information pertaining to proofs.
Kernel Alignment Risk Estimator: Risk Prediction from Training Data
Jun 17, 2020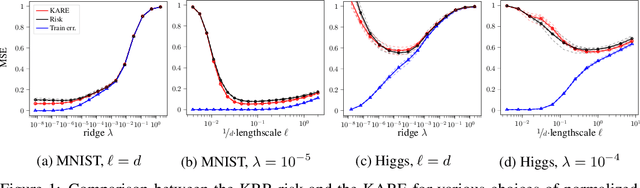
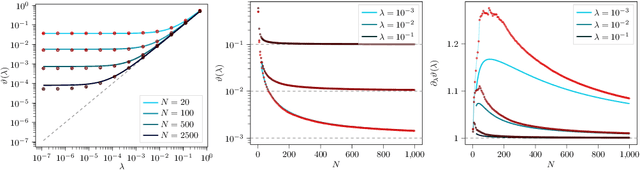
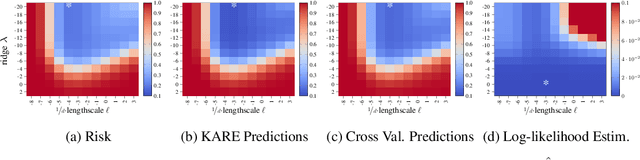
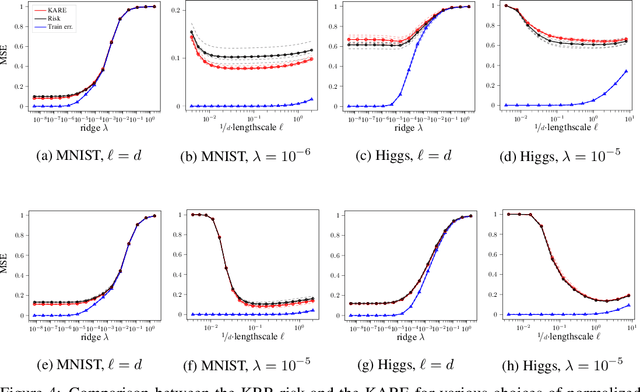
We study the risk (i.e. generalization error) of Kernel Ridge Regression (KRR) for a kernel $K$ with ridge $\lambda>0$ and i.i.d. observations. For this, we introduce two objects: the Signal Capture Threshold (SCT) and the Kernel Alignment Risk Estimator (KARE). The SCT $\vartheta_{K,\lambda}$ is a function of the data distribution: it can be used to identify the components of the data that the KRR predictor captures, and to approximate the (expected) KRR risk. This then leads to a KRR risk approximation by the KARE $\rho_{K, \lambda}$, an explicit function of the training data, agnostic of the true data distribution. We phrase the regression problem in a functional setting. The key results then follow from a finite-size analysis of the Stieltjes transform of general Wishart random matrices. Under a natural universality assumption (that the KRR moments depend asymptotically on the first two moments of the observations) we capture the mean and variance of the KRR predictor. We numerically investigate our findings on the Higgs and MNIST datasets for various classical kernels: the KARE gives an excellent approximation of the risk, thus supporting our universality assumption. Using the KARE, one can compare choices of Kernels and hyperparameters directly from the training set. The KARE thus provides a promising data-dependent procedure to select Kernels that generalize well.