 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Learning in $L_{2}$-regularized DNNs: Attraction/Repulsion and Sparsity
Paper and Code
May 31, 2022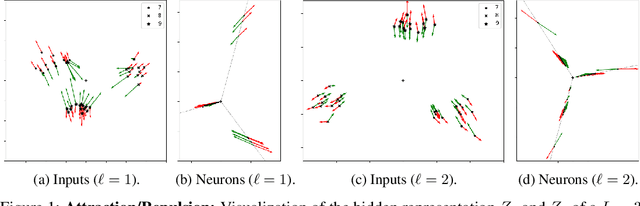

We study the loss surface of DNNs with $L_{2}$ regularization. We show that the loss in terms of the parameters can be reformulated into a loss in terms of the layerwise activations $Z_{\ell}$ of the training set. This reformulation reveals the dynamics behind feature learning: each hidden representations $Z_{\ell}$ are optimal w.r.t. to an attraction/repulsion problem and interpolate between the input and output representations, keeping as little information from the input as necessary to construct the activation of the next layer. For positively homogeneous non-linearities, the loss can be further reformulated in terms of the covariances of the hidden representations, which takes the form of a partially convex optimization over a convex cone. This second reformulation allows us to prove a sparsity result for homogeneous DNNs: any local minimum of the $L_{2}$-regularized loss can be achieved with at most $N(N+1)$ neurons in each hidden layer (where $N$ is the size of the training set). We show that this bound is tight by giving an example of a local minimum which requires $N^{2}/4$ hidden neurons. But we also observe numerically that in more traditional settings much less than $N^{2}$ neurons are required to reach the minima.